オーバーフィット
オーバーフィットとは
オーバーフィットは、機械学習モデルが、トレーニングしているデータに対して過剰に適合した結果、他のデータセットへの適応性が失われた場合に発生します。オーバーフィット状態の場合、モデルは元のデータに特化しすぎているので、将来的に収集したデータに適用しようとしても、問題のある予測や誤った結果が生成され、最適とはいえない決定が下されてしまいます。
適切にフィッティングされたモデルとオーバーフィット状態のモデルの違いを以下に示します。
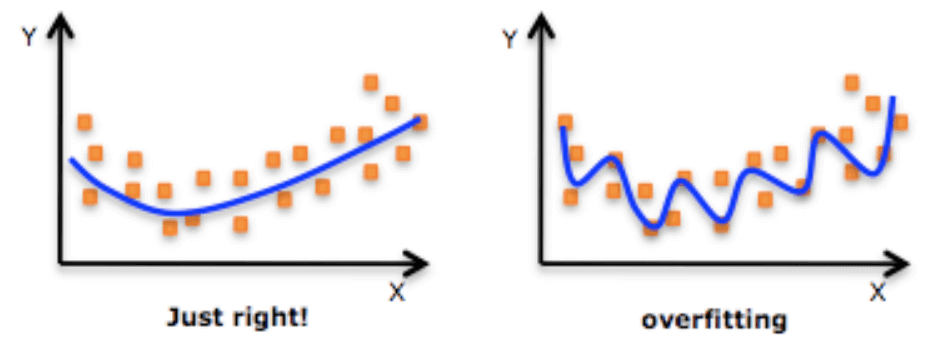
オーバーフィット状態のモデルは、まったく同じデータセットに適用しない限り、役に立ちません。オーバーフィットしたラインにぴったりと沿う他のデータなどないためです。
オーバーフィットが重要である理由
オーバーフィットにより、モデルが学習したデータを正しく表現できなくなります。オーバーフィット状態のモデルは、より一般的にフィッティングされたモデルと比べ、新たな類似データでは精度が低くなる可能性がありますが、その反面、トレーニングデータに適用した場合は精度がより高くなります。オーバーフィットへの対策を講じなくても、モデル開発者は精度が高いと考えるモデルをトレーニングしてデプロイすることがありますが、本番で新しいデータを与えられた場合のパフォーマンスは低くなります。
オーバーフィット状態のモデルをデプロイすると、あらゆる種類の問題が発生する可能性があります。たとえば、債務不履行の可能性を 95% の精度で予測できると考えているモデルが、実際にはオーバーフィット状態で、精度が 60% 程度である場合、将来的な融資の裁定にこれを適用すると、本来は利益があったはずのビジネスで多額の損失が発生し、顧客満足度が低下してしまいます。
オーバーフィット + DataRobot
DataRobot の自動機械学習プラットフォームは、トレーニングデータからの標本内モデル予測に対してトレーニング、検定、ホールドアウト(TVH)、データ分割、N 分割の交差検定、積み上げ予測などのテクニックを使用して、機械学習ライフサイクル内のすべてのステップでオーバーフィットを防止します。DataRobot は、トップレベルのデータサイエンティストの専門知識を組み込み、フィッティングプロセスを自動化します。これにより、モデルの実際の精度を疑うことなく、自社のビジネス上の問題に対する関連性が最も高いモデルを選ぶことに集中できます。