Training Sets, Validation Sets, and Holdout Sets
What are Training, Validation, and Holdout?
Partitioning Data
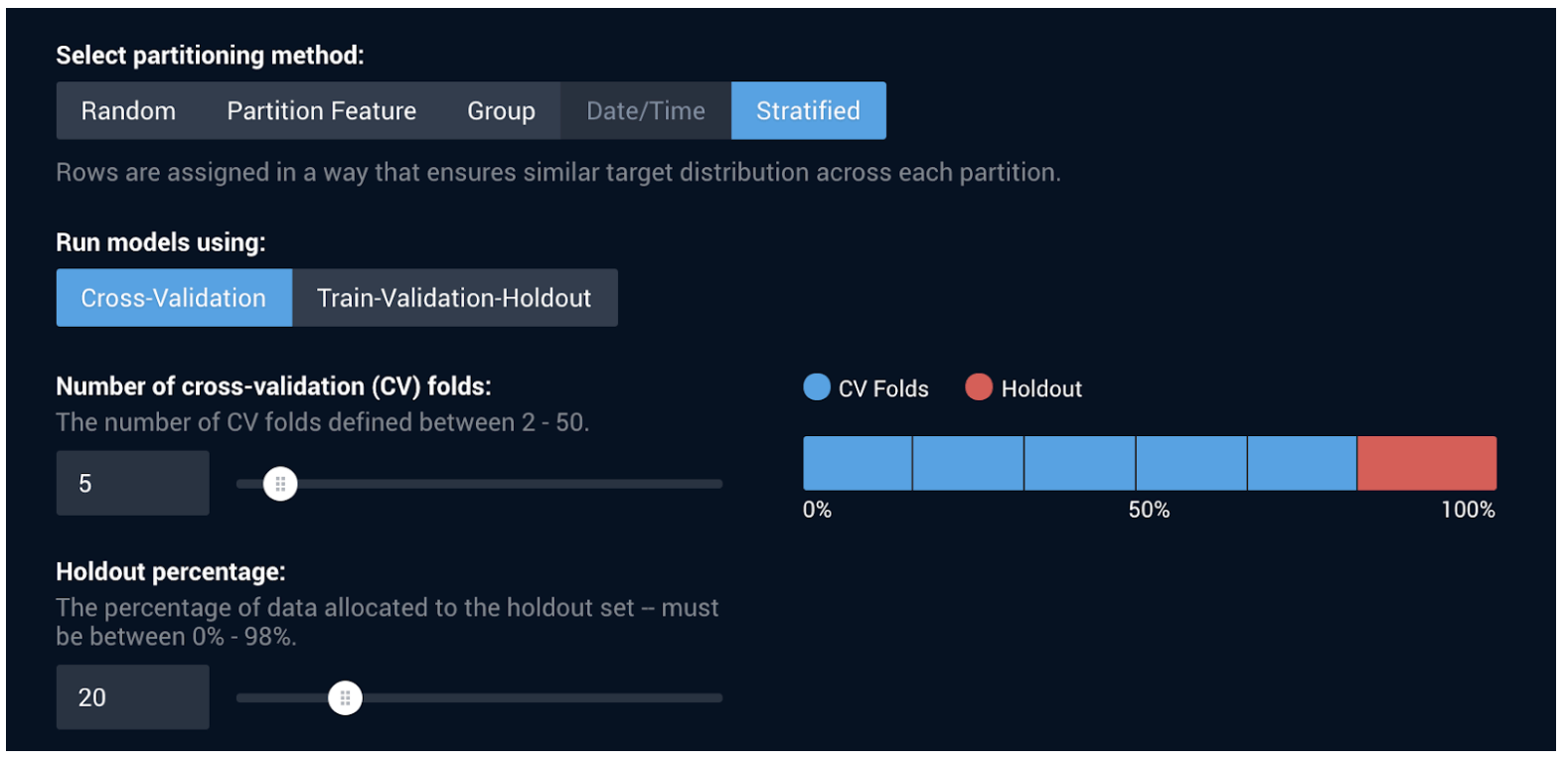
The first step in developing a machine learning model is training and validation. In order to train and validate a model, you must first partition your dataset, which involves choosing what percentage of your data to use for the training, validation, and holdout sets. The following example shows a dataset with 64% training data, 16% validation data, and 20% holdout data.

What is a Training Set?
A training set is the subsection of a dataset from which the machine learning algorithm uncovers, or “learns,” relationships between the features and the target variable. In supervised machine learning, training data is labeled with known outcomes.
What is a Validation Set?
A validation set is another subset of the input data to which we apply the machine learning algorithm to see how accurately it identifies relationships between the known outcomes for the target variable and the dataset’s other features.
What is a Holdout Set?
Sometimes referred to as “testing” data, a holdout subset provides a final estimate of the machine learning model’s performance after it has been trained and validated. Holdout sets should never be used to make decisions about which algorithms to use or for improving or tuning algorithms.
Why are Training, Validation, and Holdout Sets Important?
Partitioning data into training, validation, and holdout sets allows you to develop highly accurate models that are relevant to data that you collect in the future, not just the data the model was trained on. By training your data, validating it, and testing it on the holdout set, you get a real sense of how accurate the model’s outcomes will be, leading to better decisions and greater confidence in your model’s accuracy.
Training Sets, Validation Sets, and Holdout Sets + DataRobot
Determining the best way to partition, train, validate, and test data can be difficult, especially to those new to automated machine learning and data science in general. The DataRobot AI platform automatically partitions, trains, and tests data in order to develop the most accurate machine learning models, and it also allows for manual adjustments if users already know the percentages they want to use.
For each model, the DataRobot Leaderboard displays the validation, cross-validation, and holdout accuracy scores based on an optimization metric (which defaults to LogLoss, as you can see on the application’s home screen after you upload your dataset).

This helps users determine which model is the most accurate, allowing you to make the best business decisions possible.
DataRobot’s default method for validation and testing is five-fold cross-validation with 20% holdout, which our award-winning data scientists have found results in highly accurate models in the widest range of situations.