

Semi-Supervised Machine Learning
What is Semi-Supervised Machine Learning?
Semi-supervised machine learning is a combination of supervised and unsupervised machine learning methods.
With more common supervised machine learning methods, you train a machine learning algorithm on a “labeled” dataset in which each record includes the outcome information. This allows the algorithm to deduce patterns and identify relationships between your target variable and the rest of the dataset based on information it already has. In contrast, unsupervised machine learning algorithms learn from a dataset without the outcome variable. In semi-supervised learning, an algorithm learns from a dataset that includes both labeled and unlabeled data, usually mostly unlabeled.
Why is Semi-Supervised Machine Learning Important?
When you don’t have enough labeled data to produce an accurate model and you don’t have the ability or resources to get more data, you can use semi-supervised techniques to increase the size of your training data. For example, imagine you are developing a model intended to detect fraud for a large bank. Some fraud you know about, but other instances of fraud are slipping by without your knowledge. You can label the dataset with the fraud instances you’re aware of, but the rest of your data will remain unlabelled:
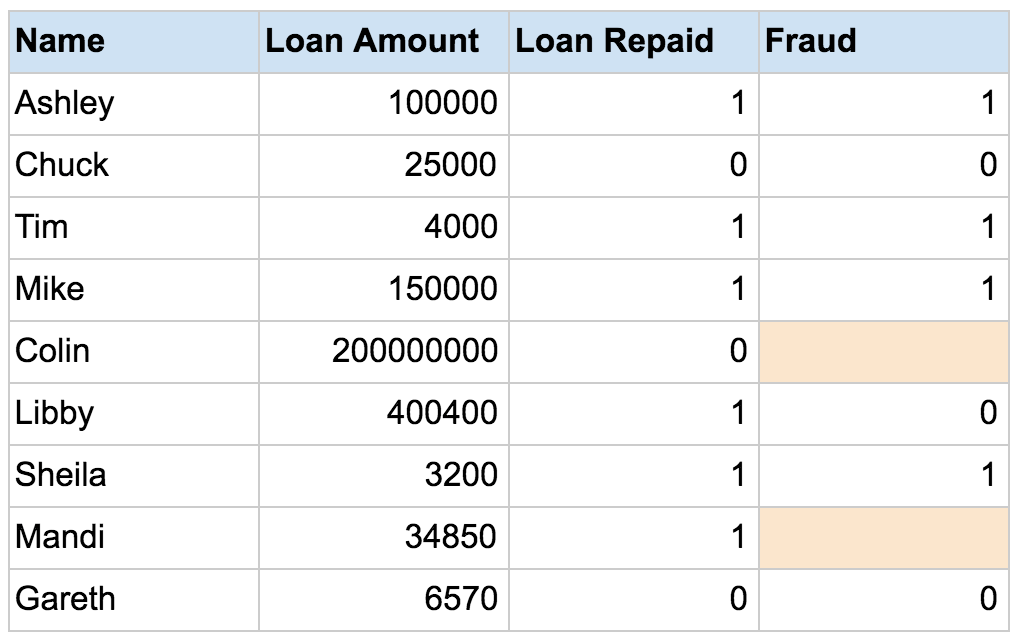
You can use a semi-supervised learning algorithm to label the data, and retrain the model with the newly labeled dataset:
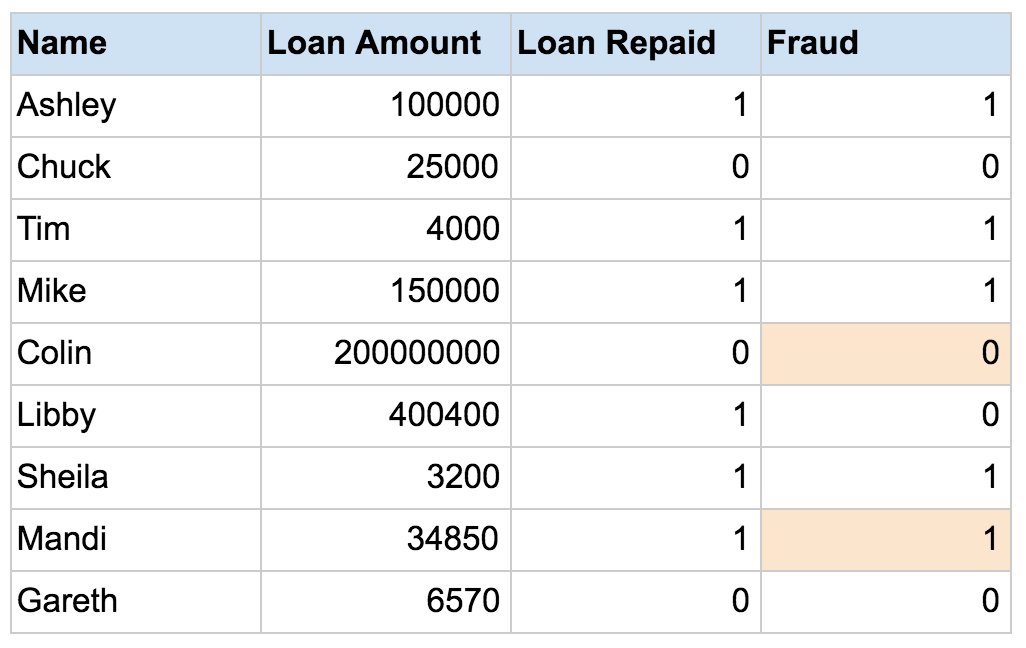
Then, you apply the retrained model to new data, more accurately identifying fraud using supervised machine learning techniques. However, there is no way to verify that the algorithm has produced labels that are 100% accurate, resulting in less trustworthy outcomes than traditional supervised techniques.
Semi-Supervised Machine Learning + DataRobot
If your training dataset contains a few thousand rows of records that have a known outcome but thousands more that don’t, you can use the DataRobot AI platform to label more of your data. It quickly builds models based on your labeled data and applies them to your unlabeled data, and then uses those data to train more models. This drastically reduces the amount of time it would take an analyst or data scientist to hand-label a dataset, adding a boost to efficiency and productivity.