

Cross-Validation
What is Cross-Validation?
Cross-validation is an extension of the training, validation, and holdout (TVH) process that minimizes the sampling bias of machine learning models. Data partitioning for the regular TVH process looks like this:

With cross-validation, we still have our holdout data, but we use several different portions of the data for validation rather than using one fifth for the holdout, one for validation, and the remainder for training as shown in the above example. Since the non-holdout data was split into five buckets, we call this “5-fold cross-validation.” If there had been four buckets, it would have been 4-fold cross-validation.
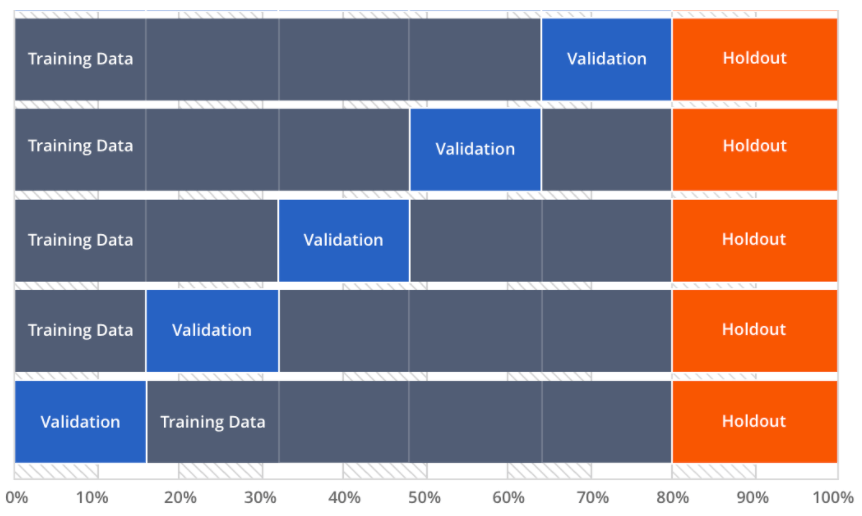
Next, we build five iterations of a model (represented by the five different rows), training it on the gray part of the set and testing it on the blue part. Then we can take the average performance of the model on each of the validation partitions and use it to measure model performance.
Why is Cross-Validation Important?
If the original validation partition is not representative of the overall population, then the resulting model may appear to have a high accuracy when in reality it just happens to fit the unusual validation set well, causing you to implement a model that actually has poor accuracy when applied to future data. With cross-validation, you can double-check how accurate your model is on multiple different subsets of data, ensuring it will generalize well to data you collect in the future.
Cross-Validation + DataRobot
DataRobot automatically uses 5-fold cross-validation, but also allows you to manually partition your data.
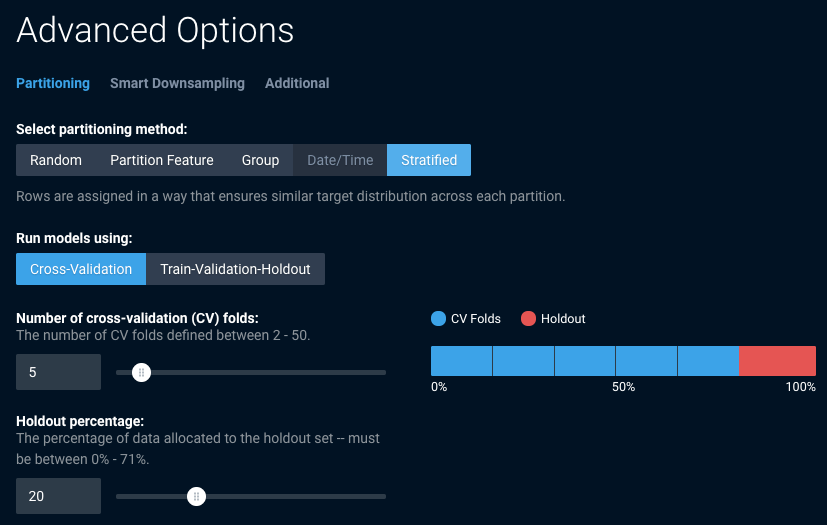
Alternatively, rather than using TVH or cross-validation, you can specify group partitioning or out-of-time partitioning, which trains models on data from one time period and validates the model on data from a later time period. For the maximum level of control, you can specify the partition to which each record in your dataset is assigned.