トレーニングセット、検定セット、ホールドアウトセット
トレーニング、検定、ホールドアウトとは
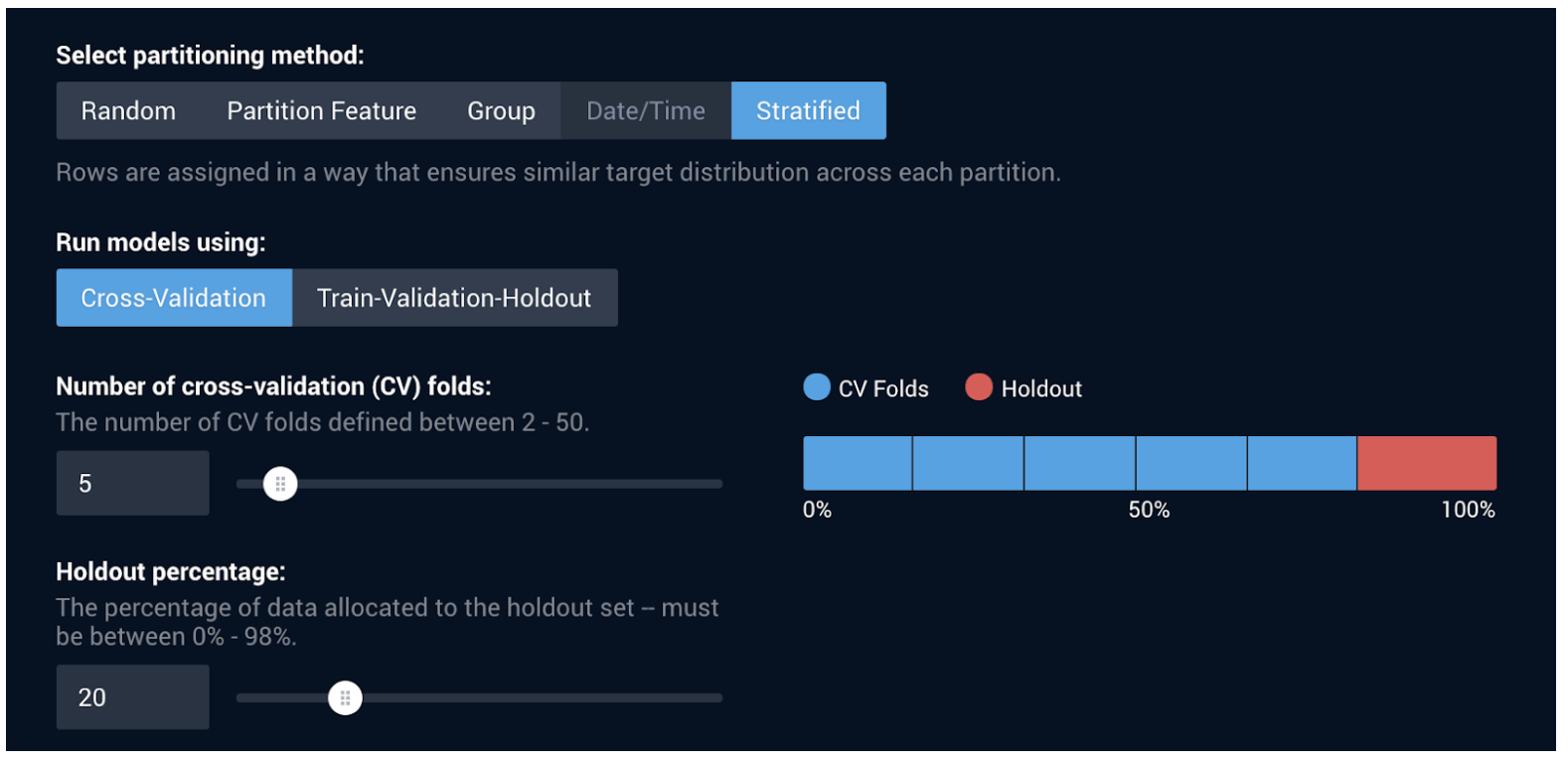
データのパーティショニング
機械学習モデルを開発するにあたっての最初のステップは、トレーニングと検定です。モデルをトレーニングして検定するには、まずデータセットを分割する必要があります。この分割では、トレーニング、検定、およびホールドアウトセットに使用するデータの割合を選択します。以下の例は、64% のトレーニングデータ、16% の検定データ、20% のホールドアウトデータを含むデータセットを示しています。

トレーニングセットとは
トレーニングセットとは、データセットのサブセクションであり、機械学習アルゴリズムはここから特徴量とターゲット変数との関係を見つけ出す、つまり「学習」します。教師あり機械学習では、トレーニングデータに既知の結果がラベル付けされます。
検定セットとは
検定セットとは、入力データのもう 1 つのサブセットであり、ここに機械学習アルゴリズムを適用して、ターゲット変数の既知の結果とデータセットの他の特徴量との関係をどの程度の精度で識別できるかを確認します。
ホールドアウトセットとは
ホールドアウトサブセットは「テスト」データとも呼ばれ、トレーニングと検定が完了した機械学習モデルのパフォーマンスを最終的に推定します。ホールドアウトセットは、使用するアルゴリズムに関する意思決定や、アルゴリズムのチューニングまたは改善には使用すべきではありません。
トレーニング、検定、ホールドアウトの各セットが重要である理由
データをトレーニング、検定、およびホールドアウトセットへと分割することにより、精度が高く、モデルのトレーニングの基になったデータだけでなく、将来収集するデータと関連性のあるモデルを開発できます。データをトレーニング、検定し、ホールドアウトセットでテストすることにより、モデルの結果の精度がどのぐらいになるかを知ることができ、意思決定およびモデル精度の信頼性の向上につながります。
トレーニングセット、検定セット、ホールドアウトセット + DataRobot
機械学習の自動化とデータサイエンス全般に詳しくない場合は特に、データを分割、トレーニング、検定、テストするための最善の方法を判断することが難しくなります。DataRobot プラットフォームは、最も精度の高い機械学習モデルを開発するようにデータを自動的に分割、トレーニング、テストします。また、使用する割合をユーザーがすでにわかっている場合は、手動での調整も可能です。
各モデルに対し、DataRobot のリーダーボードに、検定、交差検定、ホールドアウトの精度スコアが最適化指標(データセットのアップロード後にアプリケーションのホーム画面に表示されるとおり、デフォルトでは LogLoss に設定されています)に基づいて表示されます。

これにより、ユーザーはどのモデルが最も精度が高いかを判断し、可能な限り最適なビジネス決定を下すことができます。
DataRobot のデフォルトの検定およびテスト手法は、受賞歴のある弊社データサイエンティストが見つけ出した、20% のホールドアウトを含む 5 分割交差検定です。最も広範な状況にわたって精度の高いモデルを構築できます。