データ準備
機械学習のためのデータ準備とは
データ準備とは、データサイエンティストやアナリストが機械学習アルゴリズムによってインサイトを見つけ出したり、予測したりできるように、未加工データを変換するプロセスのことです。
データ準備プロセスは、以下のような問題によって複雑化することがあります。
-
- 欠損レコードまたは不完全なレコード。データセットに含まれるすべてのレコードのデータポイントを取得するのは困難です。欠損データは、空白セルとして表示されるか、疑問符などの特定の記号で表示されることがあります。例:
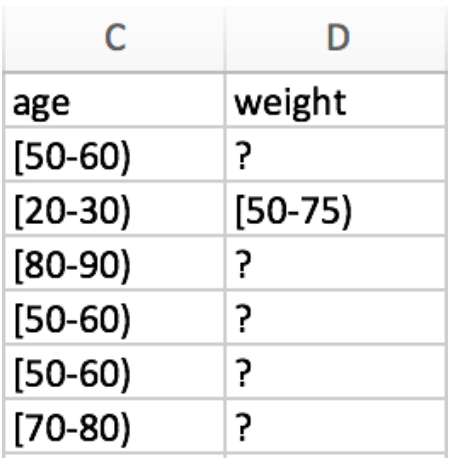
- 不正な形式のデータ。データを別の形式または場所へ抽出することが必要な場合もあります。この場合の適切な対処方法としては、専門家に問い合わせるか、他のソースからのデータを加えます。
- 特徴量エンジニアリングなどのテクニックの必要性。すべての関連データを入手できたとしても、データ準備プロセスでは、モデルの精度と妥当性を高める追加コンテンツを生成するために特徴量エンジニアリングなどのテクニックが必要になる場合があります。
- 欠損レコードまたは不完全なレコード。データセットに含まれるすべてのレコードのデータポイントを取得するのは困難です。欠損データは、空白セルとして表示されるか、疑問符などの特定の記号で表示されることがあります。例:
データ準備が重要である理由
ほとんどの機械学習アルゴリズムでは、データを特定の方法でフォーマットすることが必要になります。したがって、一般的には、データセットから有益なインサイトを引き出すには、事前にある程度の準備が必要になります。値が欠損している、無効な値が含まれているなど、アルゴリズムで処理しにくい値が含まれているデータセットもあります。データが欠損していれば、アルゴリズムでそのデータを使用できません。データが無効な場合は、アルゴリズムによって生成される結果の精度が落ちるか、誤解を招く結果になります。適切なデータ準備を行えば、クリーンで十分に精選されたデータが生成され、より実用的で高精度なモデル結果が得られます。
データ準備 + DataRobot
DataRobot の自動機械学習プラットフォームは、Trifacta などのツールと連携してデータ準備プロセスを支援します。
ユーザーが機械学習用のデータセットを適切に準備したら、DataRobot へのインポートは .csv をドラッグアンドドロップするか、Hadoop や一般的な SQL データベースからインポートするだけで簡単に実行できます。ユーザーは、DataRobot の言語別の API を使用して、Pandas(Python)や R データフレームなどの一般的な形式を直接アップロードすることもできます。DataRobot では、ユーザーのプログラミングスキルを問わず、該当するレベルに適したインポートメカニズムが用意されています。

ユーザーがプラットフォームにデータをアップロードすると、DataRobot は自動的に探索的データ分析を実行して、各変数タイプを識別し、平均、中央値、標準偏差など数値レコードの記述統計を生成します。これにより、アナリストとデータサイエンティストは、Excel やその他同様のソフトウェアを使用して手動で分析することなく、簡単にデータを探索できます。DataRobot では、欠損値も必要に応じて自動的に補完されます。追加の特徴量を手動で導出するためのグラフィカルツールも用意されています。