特徴量変数
機械学習での特徴量変数とは
特徴量とは、分析しようとしているオブジェクトの測定可能なプロパティです。データセットでは、特徴量は列として表示されます。

上の画像は、不運に見舞われたタイタニック号の処女航海の乗客情報を含むパブリックデータセットの一部です。各特徴量、つまり列は、分析に使用できる測定可能なデータである氏名、年齢、性別、料金などを表します。特徴量は「変数」または「属性」と呼ばれることもあります。データセットに含める特徴量は、何の分析を試みるかに応じて大きく異なる場合があります。
特徴量変数が重要である理由
特徴量はデータセットの基本要素です。データセットに含める特徴量の品質が、そのデータセットを機械学習に使用する場合に得るインサイトの質に大きく影響します。また、同じ業界の中でも、ビジネス上のさまざまな問題に必要な特徴量は必ずしも同じではありません。データサイエンスプロジェクトのビジネス目標をよく理解することが重要なのはそのためです。
特徴量の選択や特徴量エンジニアリングなどのプロセスによってデータセットの特徴量の品質を改善できますが、これらのプロセスは非常に困難で退屈なことが知られています。しかし、これらの手法を適切に実行すれば、具体的なビジネス上の問題に影響する可能性がある重要な特徴量をすべて含む最適なデータセットになり、可能な限り最善のモデル結果と最も有益なインサイトが得られます。
特徴量変数 + DataRobot
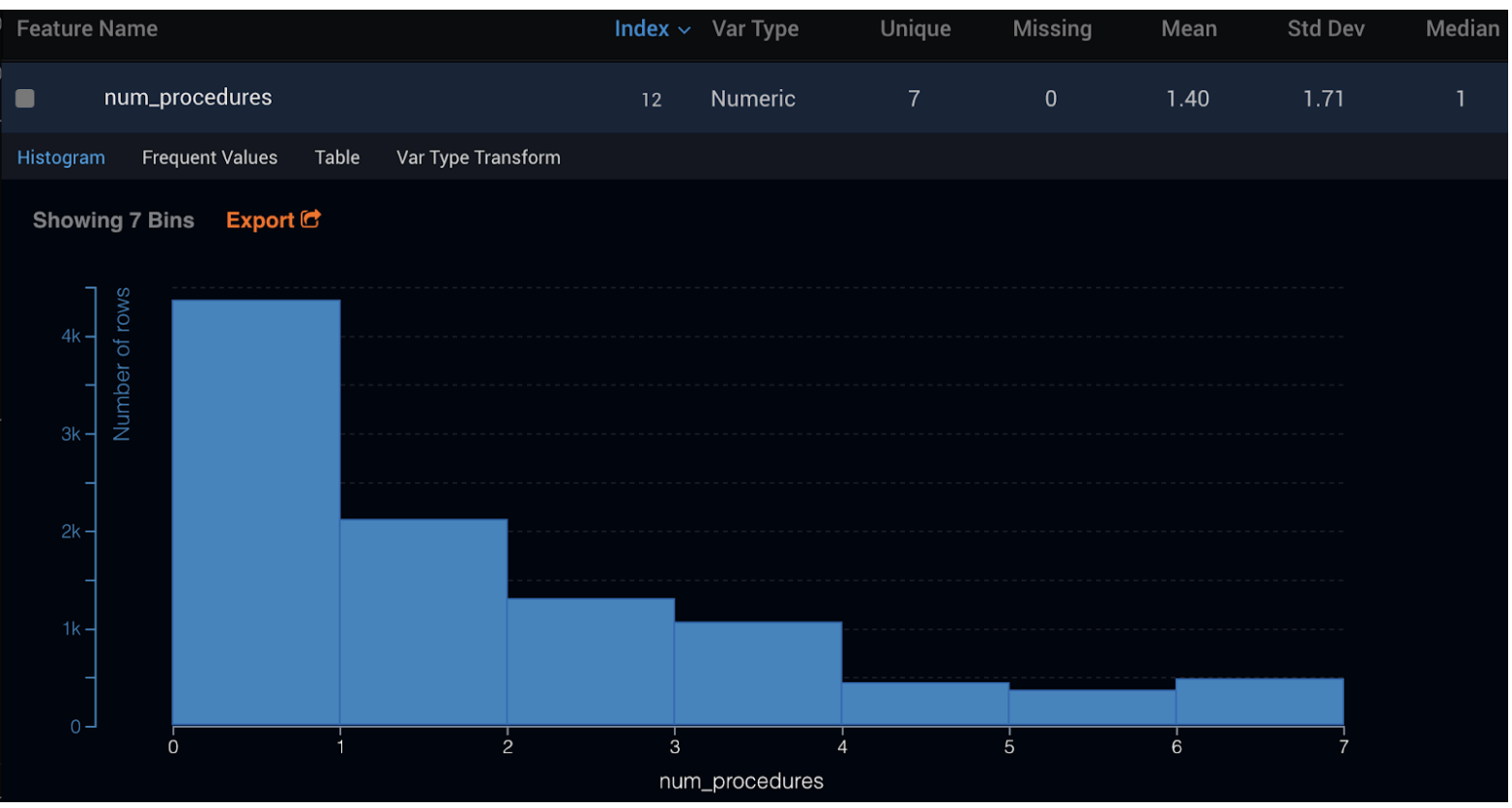
特徴量に関する作業は、従来のデータサイエンスで最も時間のかかる部分の 1 つです。DataRobot では、各特徴量のデータ型(カテゴリ、数値、日付、パーセンテージなど)が自動的に検出され、基本的な統計分析(平均、中央値、標準偏差など)が特徴量ごとに実行されます。また、各特徴量のヒストグラム、頻出値チャート、出現回数表が自動的に生成されます。ユーザーが変数の型を手動で変更することもできます。これにより、データおよびそのデータから生成されるインサイトを簡単に理解できるようになります。
それだけでなく、DataRobot では特徴量の選択と特徴量エンジニアリングが自動的に実行され、データセットごとにさまざまな組み合わせがテストされて、モデルの結果の精度と含まれるデータの関連性が確保されます。