モデルブループリント
モデルブループリントとは
DataRobot 固有の機能であるモデルブループリントは、特徴量エンジニアリング、その他のデータ前処理のステップ、プラットフォームがデータから関係、パターン、インサイト、予測を引き出すために使用する機械学習アルゴリズムを組み合わせたものです。DataRobot の各ブループリントは、経験豊富なデータサイエンティストによって開発および微調整されています。このモジュール式のアプローチを機械学習に使用することで、高い柔軟性を得られます。
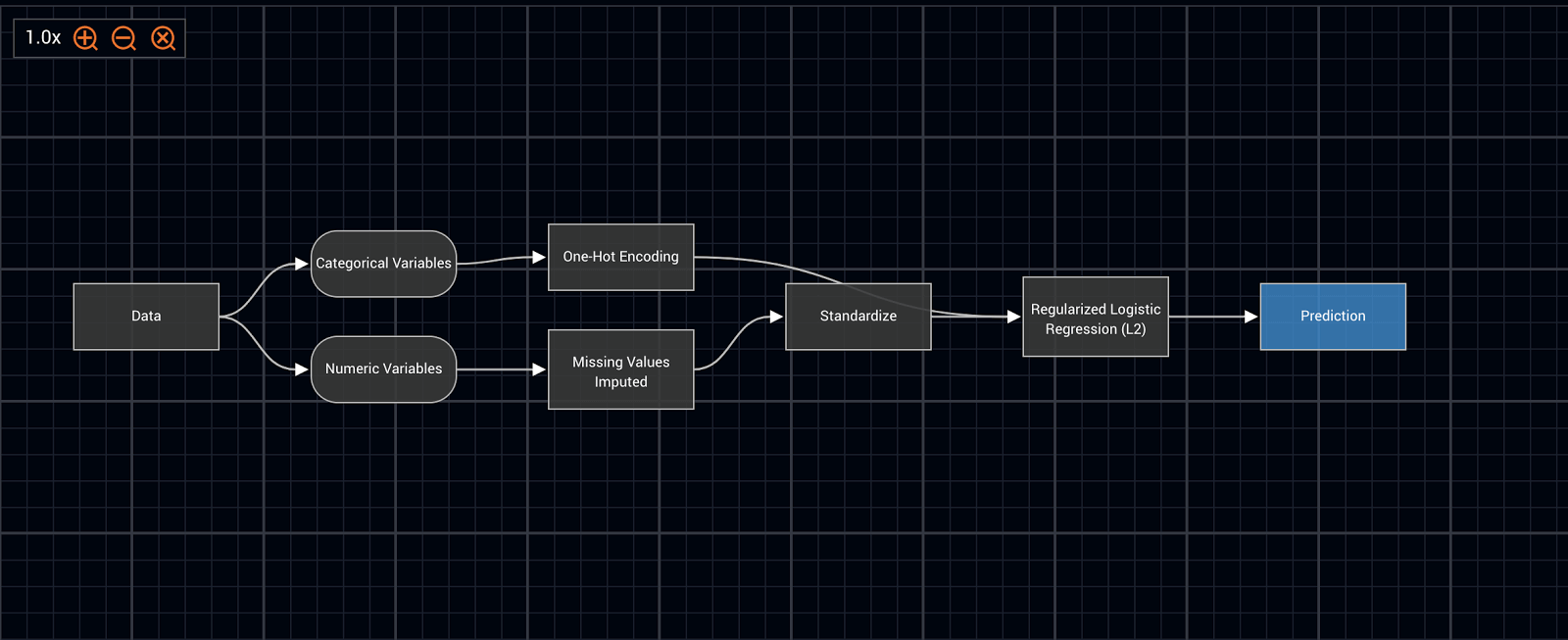
モデルブループリントが重要である理由
手動でモデルをコーディングするのに時間がかかることから、データサイエンティストは、多くの場合、使用するモデリング手法の数を限定しています。また、特定の種類のアルゴリズムを選択して実行したり、データ準備時に常に特定の手法を選択して欠損値を処理することがあります。実際、1 つの方法ですべての課題に対処することはできません。つまり、1 つまたは 2 つの一般的な方法に限定すると、最も精度の高い結果を得ることはできません。これは「ノーフリーランチ定理」と呼ばれています。何でも上手に学習できるアルゴリズムは存在しません。
固有のデータセットやビジネス課題ごとに最適なモデリング手法を見つけるには、データサイエンスプロジェクトで、さまざまなモデリング手法を組み合わせる必要があります。モデルブループリントはこのプロセスを自動化し、従来のデータサイエンティストが数個を試すのと同じ時間で、ユーザーが多くのモデリング手法を迅速にテストできるようにします。これにより、モデルの多様性が高まり、最も精度の高いモデルに基づいて適切な判断が行われるようになります。
DataRobot + モデルブループリント
DataRobot の熟練のデータサイエンティストチームは、あらゆる種類のモデルブループリントを開発して徹底的にテストし、DataRobot の機械学習自動化プラットフォームで公開しました。DataRobot を使用するたびに、データに対してさまざまなモデリング手法が試されます。モデルの多様性が促進され、最も精度の高いモデルを選択できます。それだけでなく、DataRobot は常に機械学習モデルのライブラリを拡張およびテストし、利用可能な最良のオープンソース技術に基づいて新しいブループリントを作成しています。
さらに、DataRobot を使用すれば、すべてのブループリント内部の各ステップを広範囲にわたって文書化し、モデルの解釈可能性を高め、バックグラウンドでの実施内容について深い理解を得られます。