
AI ソリューションが意図どおりに機能しているかどうかを確認
時間の経過と共に予測 AI および生成 AI がどのように変化しているか、その原因や詳細を把握します。

利用状況に基づく継続的な最適化
エンドユーザーによって利用される生成 AI モデルから重要なインサイトを収集し、それをもとに継続的に改良します。

モデルの比較、チャンレンジャーの設定、モデルの置き換えをすばやく実行
複数のチャレンジャーモデルを並べて比較します。実稼働モデルを 1 回のクリックですばやく置き換えることができます。

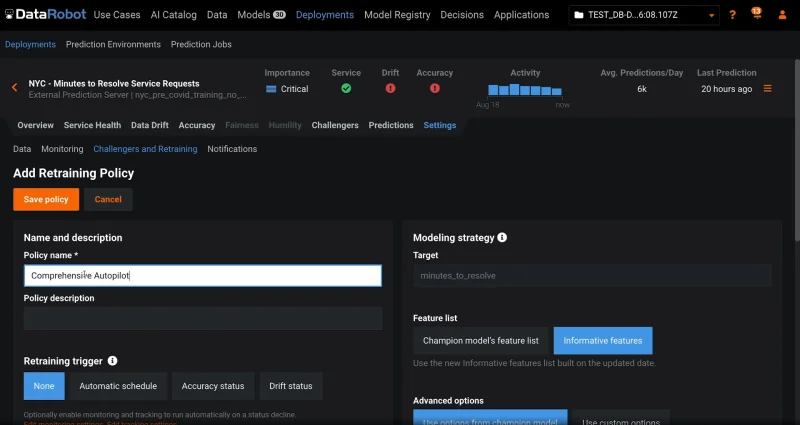
事前対応型またはトリガー応答型による再トレーニング
高度な再トレーニングポリシーと介入ポリシーを設定して、継続的な改善をオートパイロットで実行します。
モデルが意図どおりに動作していることを確認
生成 AI と予測 AI をひとつの統合エクスペリエンスにシームレスに組み合わせることで、「ガードモデル」を導入してハルシネーションを回避し、生成 AI モデルが意図どおりに活用されるようにします。
有害な応答は未然に防ぐことが肝心です。有害なプロンプトや不完全な情報を含む応答、個人情報の漏れなど、特定の行動が取られた際に追跡や介入が行われるモデルを設定します。正確性や感情などの指標に基づいて、応答レベルで評価が提供されます。また、組み込みのユーザーフィードバックループを活用すれば、改善が継続的に行われるようになります。
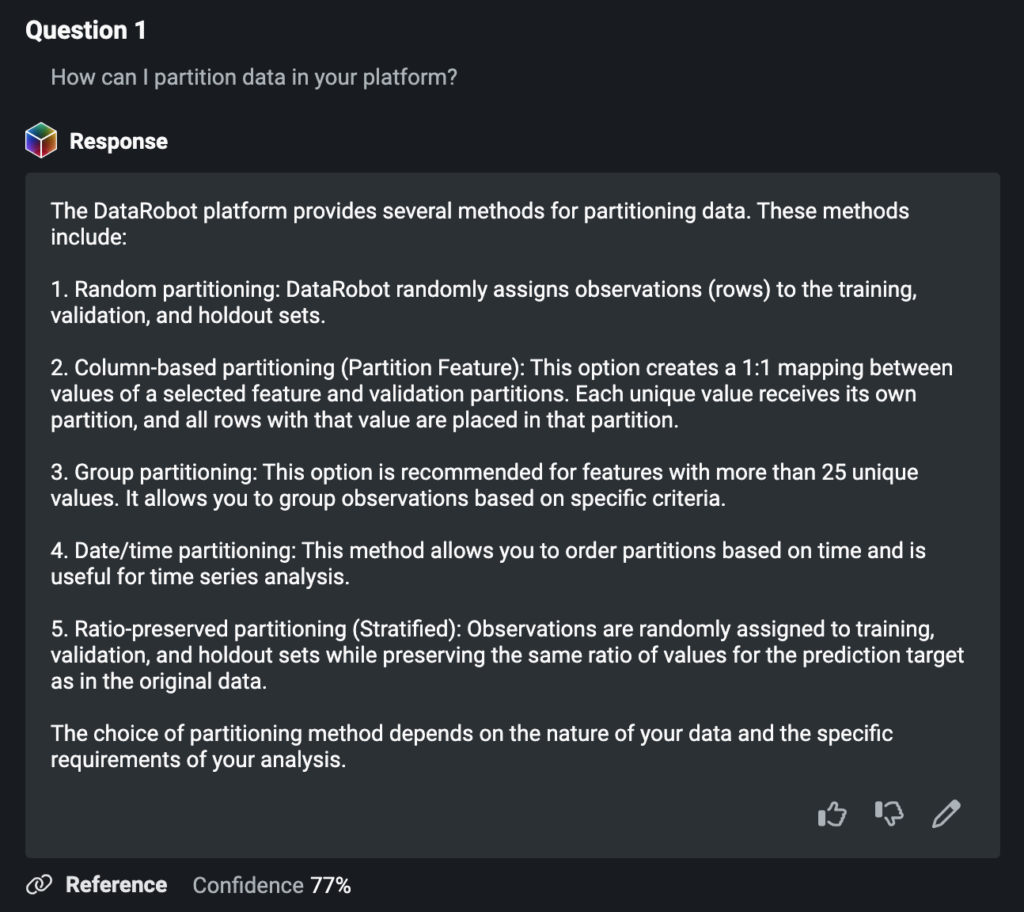
利用状況に基づく継続的な最適化
生成 AI モデルがエンドユーザーによって活用される中で、貴重なインサイトを収集して、継続的な改善を図ることができます。
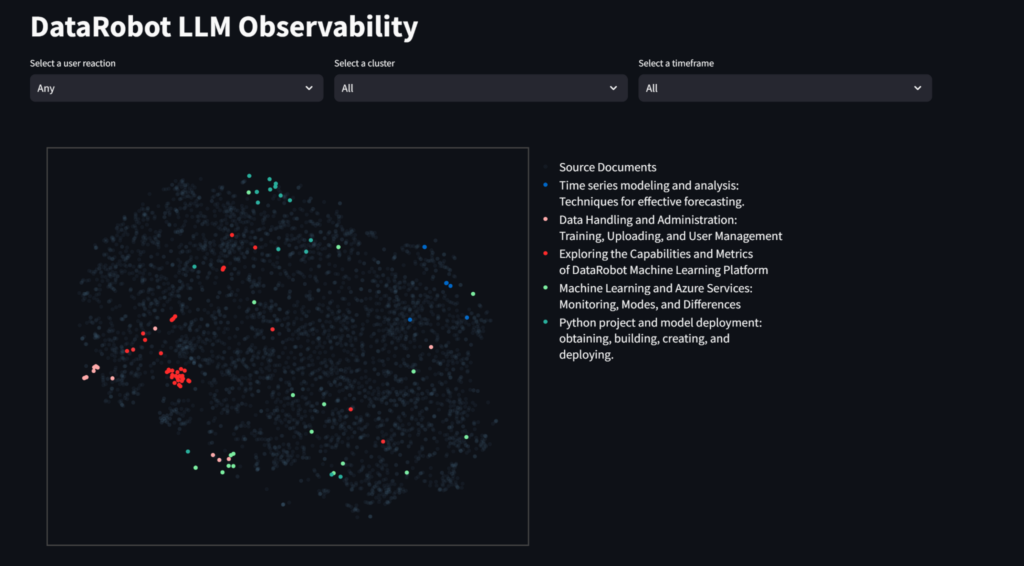
Streamlit アプリケーションで表示可能なインサイトを使用して、ユーザーの質問や生成 AI の応答がベクターデータベース内の情報とどれほど一致しているのかを評価します。データベースが包括的で、関連性があり、最新の内容になっていることを確認するとともに、その構造とコンテンツも評価します。また、インサイトを使用することで、ユーザーとのやり取りでよく出てくるトピックに関して、組織内でトレーニングを行うタイミングを見極めることができます。
モデル精度の比較
実稼働モデルを劣化させてはいけません。現実のシナリオに対するパフォーマンスを適宜分析することで、最適なモデルを特定します。チャレンジャーモデルは、独自に作成するか、DataRobot AI Platform を使って作成します。次に、チャレンジャーモデルのインサイトを生成し、チャレンジャーのパフォーマンスやチャンピオンとの比較結果を詳しく直感的に分析します。チャレンジャーとの比較は、時系列モデル、多クラスモデル、外部モデルで実行できます。
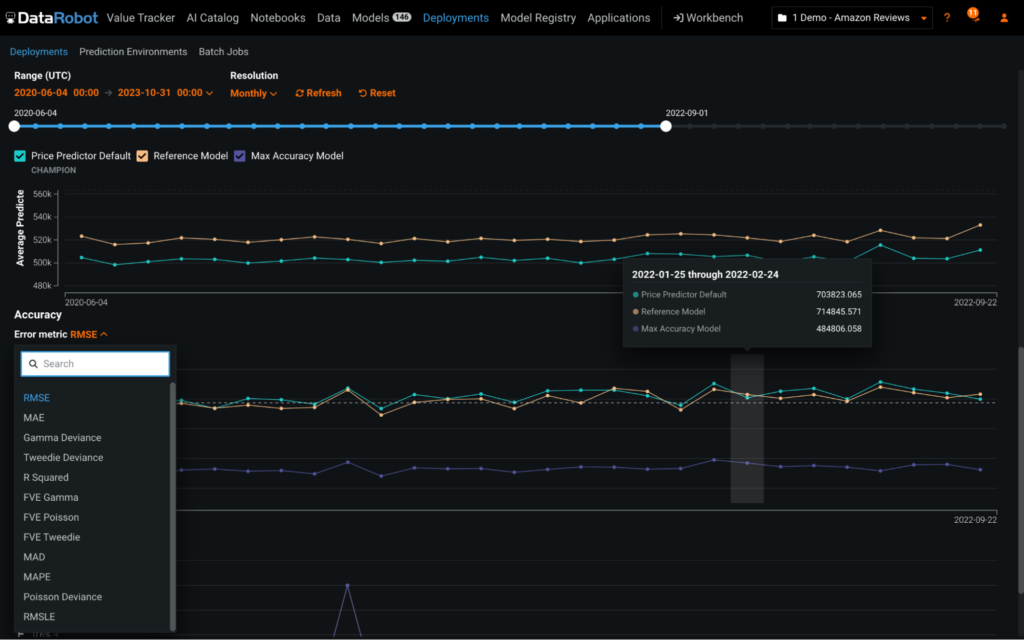
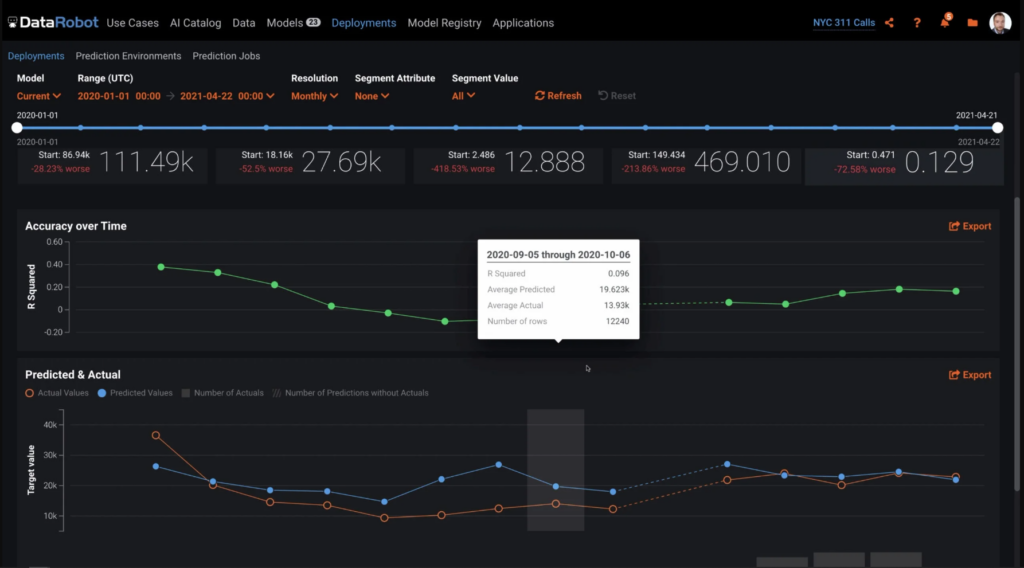
精度をひと目で確認
すぐに使用できるカスタム精度指標で、モデルの精度をひと目で確認できます。予測後に実際の結果をアップロードして、実稼働モデルの品質を評価します。真の結果が判明するのが数秒後、数時間後、あるいは数年後であっても、一意の予測 ID を利用してグラウンドトゥルースの解答を予測と関連付けることで、チャンピオンモデルとチャレンジャーモデルの両方で強力な精度追跡を実現します。
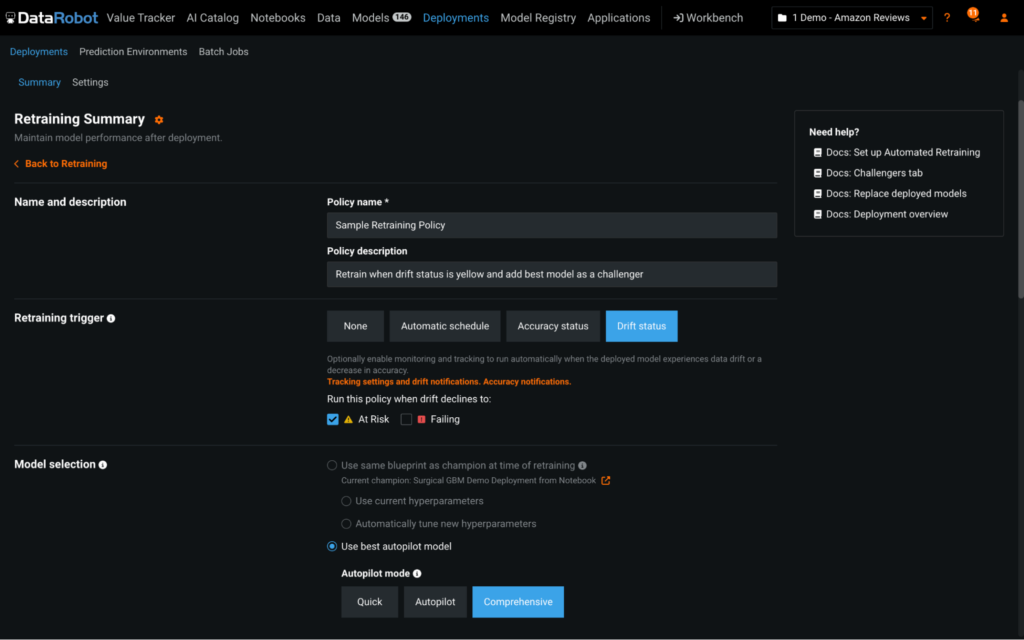
トリガーイベントに基づくカスタマイズ可能な再トレーニングアクション
デプロイ環境ごとにカスタマイズ可能な再トレーニングポリシーを適用して、モデルを最適化し、より新しいデータで再学習が行われるようにします。再トレーニングのタイミングは、カレンダーまたはトリガー(データドリフトや精度の低下など)に基づいて設定します。新しいモデル検索の範囲として、ひとつのブループリントを選択することも、実行中の包括的なオートパイロットモードを選択することもできます。また、再トレーニングの完了時に実行されるアクションも管理できます。これらのアクションには、新しいモデルパッケージを保存する、デプロイ環境にチャレンジャーとして追加する、あるいはカスタム定義の置換ガバナンスワークフローに基づきモデルを置換する、などがあります。
スピード、インパクト、スケールを実現できる DataRobot を世界中の企業が信頼










