
AI対応データセットおよびベクターデータベースの構築
生成 AI と予測 AI のユースケースに合わせて、質の高い構造化データと非構造化データを生成し、検証します。
データの品質を容易に向上
生成AI、自動化、カスタマイズを駆使して、データセットを強化し、精度と堅牢性を兼ね備えたモデルのトレーニングが可能です。

ユースケースに合わせた有益なインサイトを獲得
最もインパクトの大きい特徴量をデータセットから容易に特定し、活用できます。
プロトタイプを作成してデータ移動を削減
クラウドデータウェアハウスとデータレイク全体におけるデータガバナンスの管理を行い、それらの計算能力を活用します。
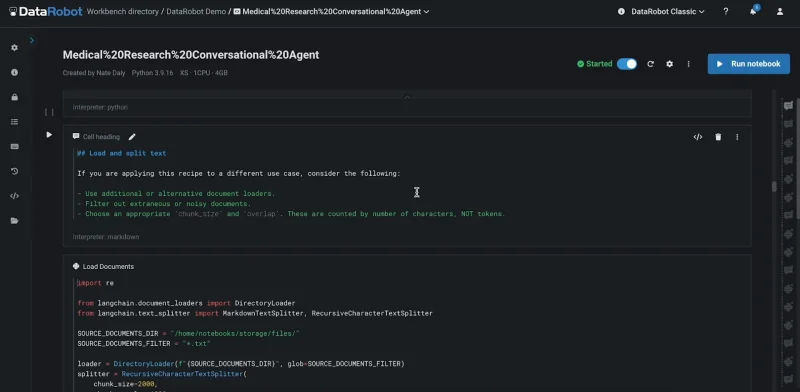
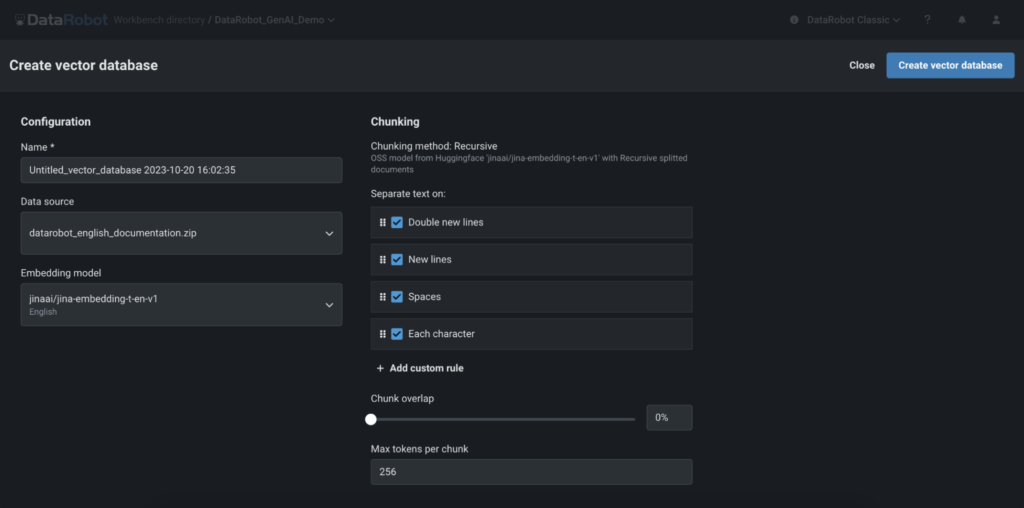
カスタムベクターデータベースを使用してグラウンディングデータを特定の要件に合わせる
独自のベクターデータベースを作成して、生成 AI の独自の課題に対応したりパフォーマンスを最適化したりするには、一から作成する手法と既存のデータベースを統合する手法があります。既存の LLM を組織のデータで拡張することで、機密情報の安全性を常に確保できます。
AI の取り組みを成功に導くには、DataRobot 独自のホスト型ノートブックを利用するか、直感的な UI を利用します。どちらの場合も、AI の取り組みがもたらす効果やインパクトを拡大できます。
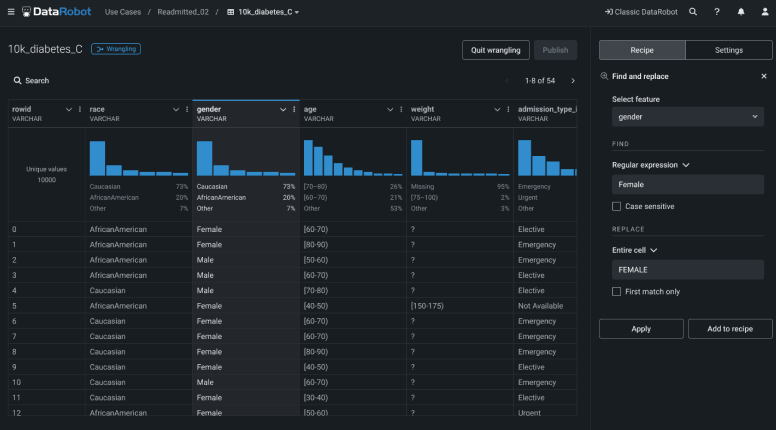
全てのデータタイプのためのデータ準備を効率化する
AI プロセスを既存のデータとシームレスに統合することで、データシグナルを迅速に特定し、AI 対応データセットを作成します。堅牢で自動化された探索的データ解析のメリットを活用すれば、単一の包括的なデータセット内で、位置情報、テキスト、画像などさまざまなデータ型のデータを、効率的に変換、分析、集計できます。また、データウェアハウスのスピードと規模を活用することで、データ移動を最小限に抑えながらガバナンスを確保できます。欠損データの処理や集計といった手間のかかるデータクリーンアップ作業を自動化すれば、重複排除、テーブル結合、集計機能などを使用して、数週間とはいかなくても数時間分の作業を節約できます。
複数のデータセットから新しい特徴量を探索
特徴量エンジニアリングパイプラインを自動化します。さまざまなデータソースにまたがる複雑なデータスキーマやデータセットを操作する必要はもうありません。予測モデルにとって重要な特徴量を、新たに何百も自動で検出、テスト、作成できるようになりました(これには時間認識モデルも含まれます)。そのため、手動による大量の反復作業を行うことなく、モデルの精度を高めることができます。
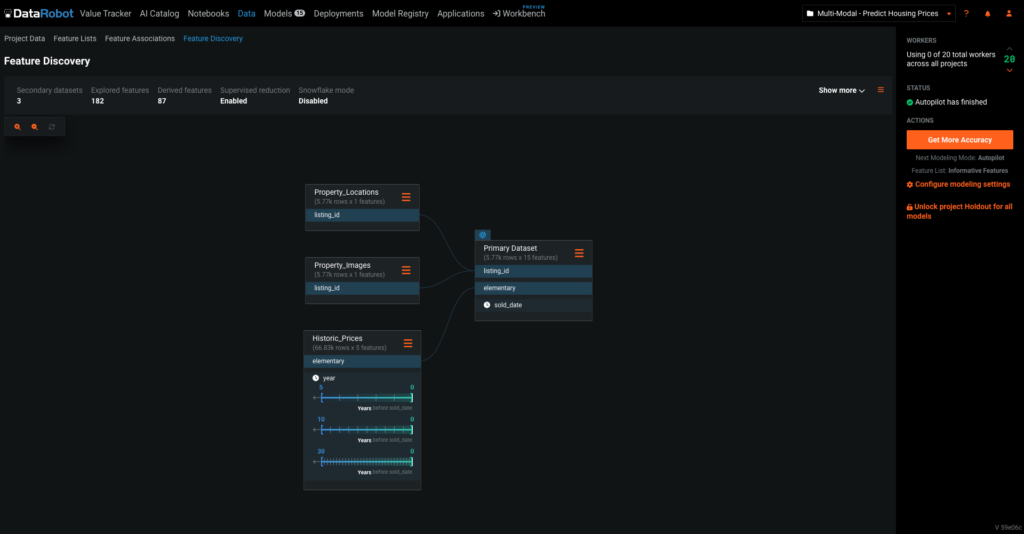
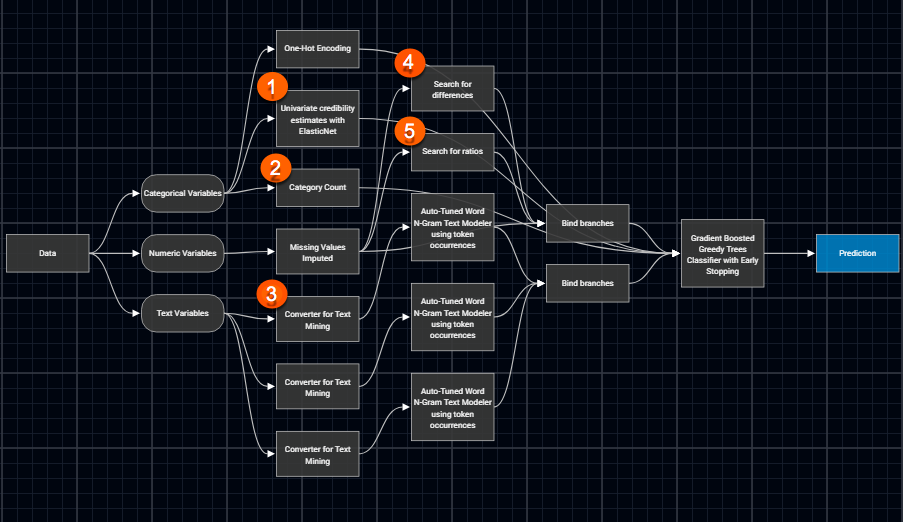
特徴量エンジニアリングパイプラインの自動化とカスタマイズ
モデルブループリントを使用してあらゆるデータ型で特徴量エンジニアリングを自動化すれば、反復作業に追われることなく、ソースからモデルに至るまでのデータをトレースできます。このブループリントは、欠損値の補完から、データの標準化やテキストの作成、さらに画像の埋め込みにまで対応します。また、オープンソースや独自のアルゴリズムを組み合わせた DataRobot のライブラリを使用してブループリントを調整および拡張したり、API 経由で外部モデルを統合したりすることもできます。
スピード、インパクト、スケールを実現できる DataRobot を世界中の企業が信頼










