積み上げ予測
積み上げ予測とは
機械学習アルゴリズムは、本番環境用データセットではなくトレーニングデータセットに対して実装しなければならない場合があります。たとえば、多段階モデリングプロセスでオーバーフィットを防止する場合などです。複数のモデルをトレーニングデータのさまざまな「分割」つまりセクションで構築する方法である積み上げ予測を使用すると、「標本外」予測を行い、誤解を招きかねないほど高い精度のスコアを防止することができます。
積み上げ予測の技術的側面を詳しく見ていく前に、ハイパーパラメーターと交差検定を理解することが重要です。
ハイパーパラメーターは、モデルのアーキテクチャおよびトレーニングプロセスを記述する構成パラメーターです。トレーニングの結果としてのモデルを記述するモデルパラメーターとは混同しないようにしてください。ハイパーパラメーターの例には、ランダムフォレストアルゴリズムのツリーの深さ、サポートベクターマシン分類子の C パラメーター、gamma パラメーターなどがあります。交差検定プロセスでは、スコアリングに対してモデルが選択されます。次に、データはさらに 5 つに小さく分割され、DataRobot が自動的にハイパーパラメーターチューニングを実行します。下の図に示すこのプロセスは、入れ子構造の交差検定と呼ばれています。
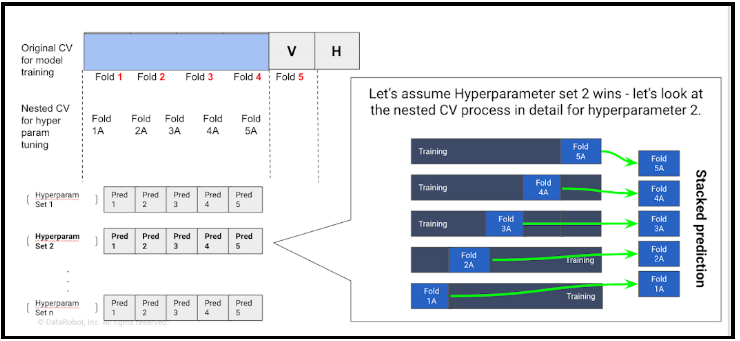
その後、分割された5 つすべての標本外予測を付加することによって積み上げ予測が計算されます。
積み上げ予測が重要である理由
トレーニングデータセットを使用した標本内予測は適切ではありません。これは、サンプル試験問題で練習して試験に備えている学生のように、モデルがデータをすでに「見ている」ためです。教師がサンプル問題を実際の試験で再び使用すれば、学生はほぼ確実に高得点を取ることができますが、新たな問題の回答方法は習得できていません。
積み上げ予測では、モデルをトレーニングするために使用するデータを最終的な予測の対象となるデータとは異なるものにします。新しい試験で古い問題を繰り返さないようにするのと同じです。
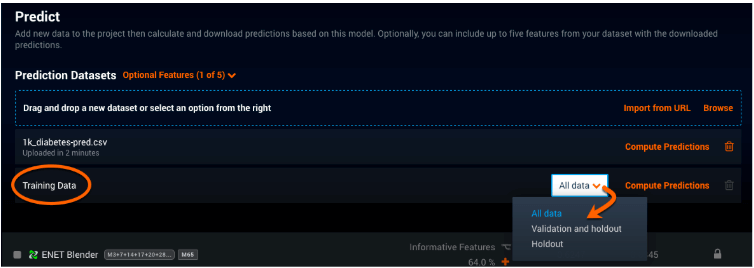
DataRobot + 積み上げ予測
以下に示すように、DataRobot プラットフォームでは[Predict(予測)]タブでトレーニングデータセットに対するモデルを開発できます。このプラットフォームでは、小規模なデータセット(750MB 未満)に対してのみ積み上げ予測を使用します。大規模なデータセット内のすべてのデータに対して積み上げ予測を実行するとコストがかかりすぎるため、ファイルサイズが 750MB を超えると、DataRobot では代わりに検定およびホールドアウトデータに対してモデルを実行します。