混同行列
混同行列とは
データセットを使用した機械学習分類モデルのトレーニングで作成される混同行列には、モデルがどのくらいの精度で各レコードを分類したか、どこでエラーが発生した可能性があるかが表示されます。行列の行は、トレーニングデータセットに含まれていた実際のラベルを表し、列はモデルの結果を表しています。
以下は、DataRobot プラットフォームの混同行列の例です。
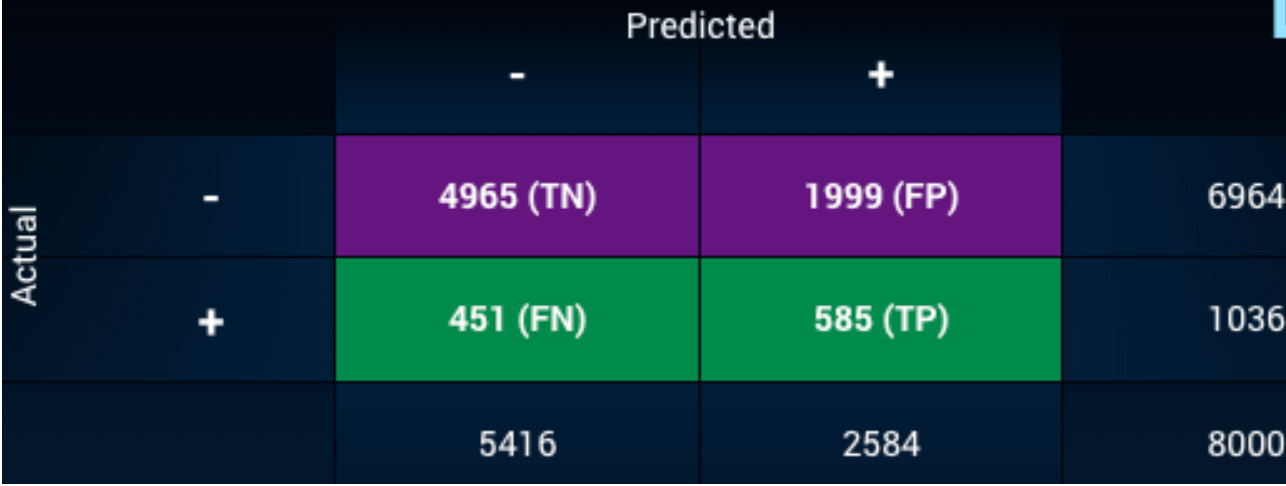
混同行列が重要である理由
混同行列は、モデルが繰り返し 2 つのクラスを混同している状況を明らかにすることによって、モデルの結果がどの程度の精度になるかをわかりやすく示します。これにより、分類モデルのパフォーマンスを評価し、ビジネスユーザーがモデルを使用して正しく分類できない可能性があるデータを特定できるようになります。
この情報は、モデルからのインサイトまたは予測を使用して実際のビジネス決定を下す際に非常に役に立ちます。たとえば、信用投資が債務不履行になるとモデルが予測しても、実際にはそうでない場合(偽陽性)と、貸し手が誤ってローンを資金提供したために債務不履行になる場合(偽陰性)では、その影響は大きく異なります。モデルがローンデータセットに対して偽陰性になる可能性があることをユーザーが混同行列から把握していれば、異なるモデルを使用するか、手動チューニングでモデルを改善する必要があるとわかります。
ユーザーは、しきい値、つまり「はい」の結果と「いいえ」の結果を分ける確率のカットオフ値を変更することで、偽陽性と偽陰性のバランスを変更できます。偽陽性と偽陰性を少なくしたい場合は、他のモデル、特徴量エンジニアリング、または追加データを検討できます。
DataRobot + 混同行列
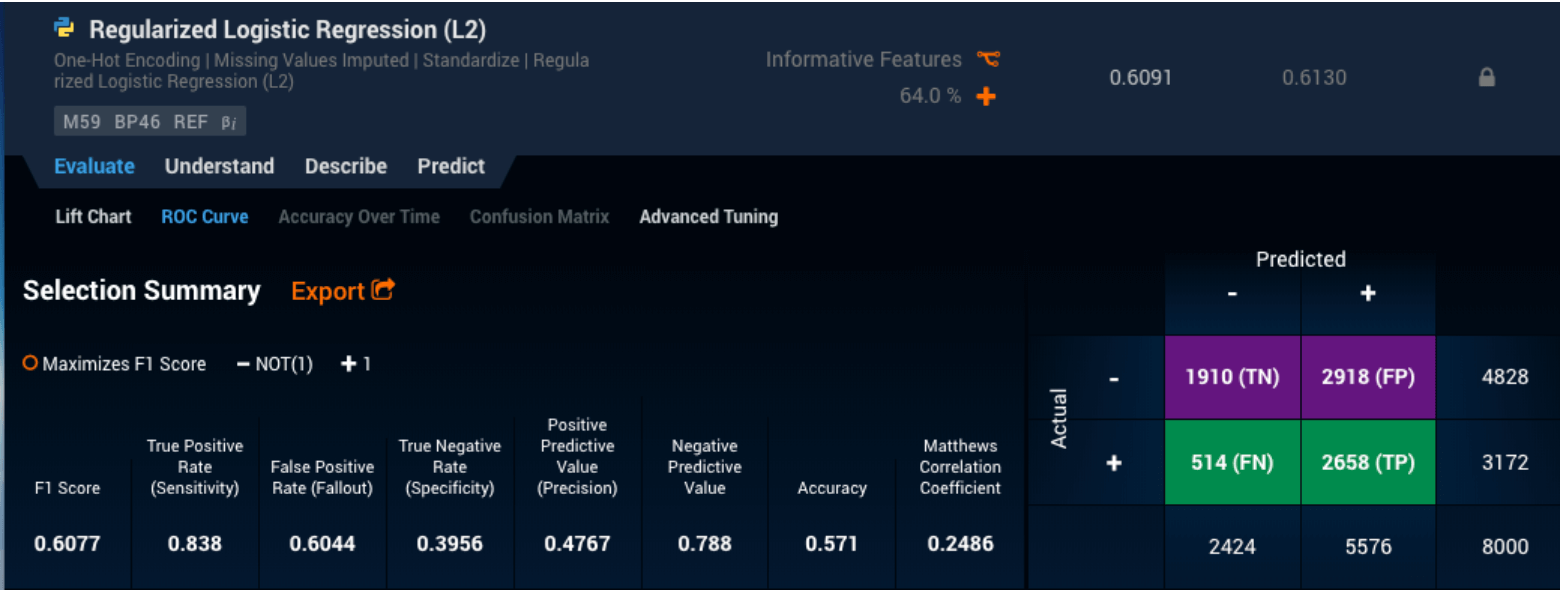
二値分類問題(各エントリに対して考えられるグループが 2 つしか存在しない場合)では、DataRobot は、個々のモデルがクリックされたときに[Evaluate(評価)]->[ROC Curve(ROC 曲線)]メニューオプションで混同行列を自動的に生成します。
多値分類問題(各レコードが複数の異なるグループに分類されるとモデルが判断する可能性がある場合)では、より包括的な混同行列専用のタブが表示されます。
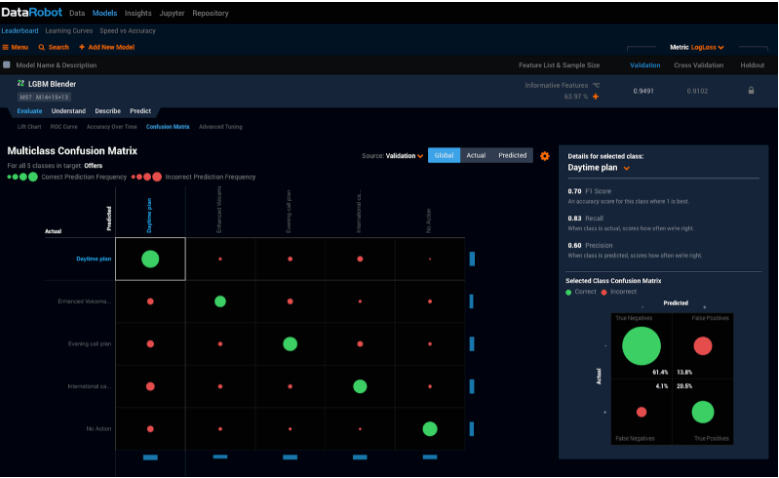
ユーザーは DataRobot が生成する各モデルの混同行列を比較できるため、特定のビジネス課題に対して偽陽性と偽陰性のレベルが最も許容可能であるものを選択できます。