DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
流通・鉄道・通信業界のお客様を担当し、技術ではMLOpsテクノロジーを中心に扱っているデータサイエンティストの濱上です
DataRobotは実務担当者がモデリングからモデル運用まで行うための機械学習・AIプラットフォームとして知られていますが、データサイエンティスト(DS)の業務を加速するためのエンジンにもなります。
今回は、DS向けにDataRobot×Papermill×MLflowを使うことで、どれくらい業務を加速し、チーム内のコラボレーションを高められるのかを紹介します。AIアクセラレーターにサンプルコードを公開していますので、実際にコードを動かしてもらえればその威力を感じていただけます。
機械学習モデル構築は実験の繰り返し
機械学習モデルのビジネス利用は、一回モデルを作成して終わりではありません。Kaggleなどのコンペティションでもトップクラスになるためには試行錯誤を自動化することが重要ですが、時間と共にデータが変わっていく実ビジネスでは、この試行錯誤を自動化することがより重要になってきます。データの変化に対応が遅れてしまうと、機械学習モデルのビジネス利用により得られるインパクトが消失してしまうからです。
試行錯誤の過程では、大量のコードとモデルとメトリクスが作成されます。これらのアセットの対応関係が明確にわかるように、実験ログを管理することもとても大切です。
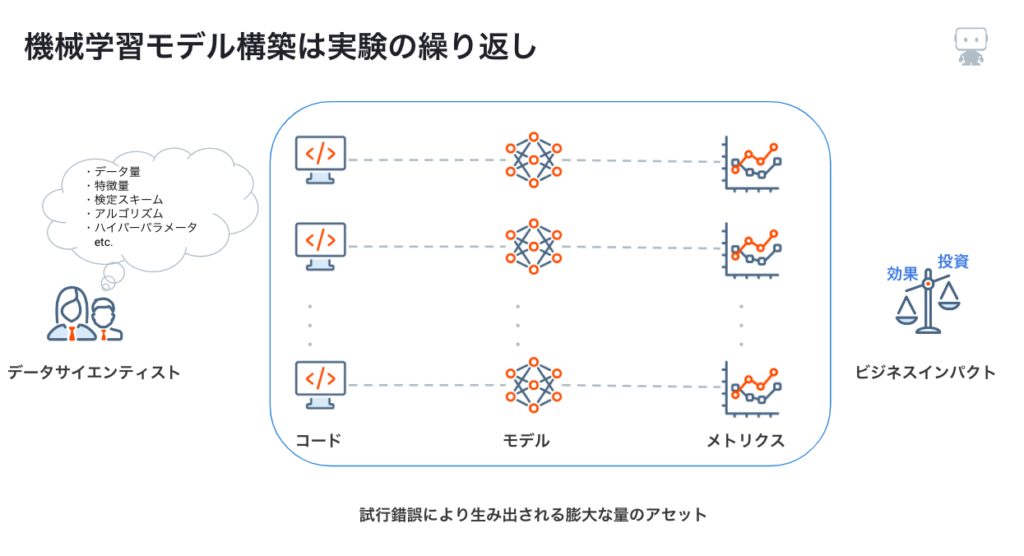
試行錯誤の自動化とログ管理が成功への近道
試行錯誤の自動化や実験ログの管理ができていれば、データサイエンティスト(DS)が陥りがちな失敗を防ぐこともできます。
多くのデータサイエンティスト(DS)にとって、機械学習の実験はゲーム感覚で楽しい瞬間であり、精度が良いモデルを作るために時間を忘れてコーディングしたなんていう経験がある人も多いのではないでしょうか。しかし、機械学習に没頭しすぎて、もしくは1人のDSの力量に依存しすぎて、機械学習プロジェクトが失敗するケースが多々あります。以下の失敗例は、そんな失敗の一部を集めたものです。
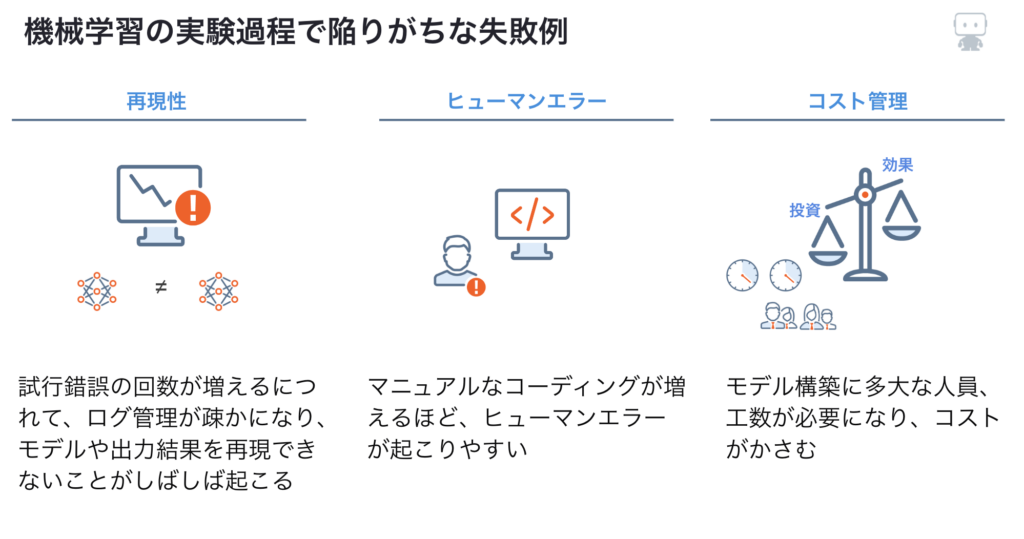
機械学習の実験過程の失敗例その1:再現性
- 膨大な試行錯誤により、実験ログの管理が疎かになり、モデルや出力結果を再現できない問題が発生
- 担当者が変更した際にログが残っておらず異常時に対応できないような最悪のケースも
機械学習の実験過程の失敗例その2:ヒューマンエラー
- コーディングはデータサイエンティストの経験や能力に依存するため、担当者レベルによってコードに技術的な誤りが発生することがある
- 経験のあるデータサイエンティストでも作業量が増えるほどヒューマンエラーによるミスが増える
機械学習の実験過程の失敗例その3:コスト管理
- モデル構築に膨大なリソースが発生し、投資対効果が悪化する
- モデル構築にリソースが偏り、課題定義やモデル運用の設計に投入するリソースが薄くなる
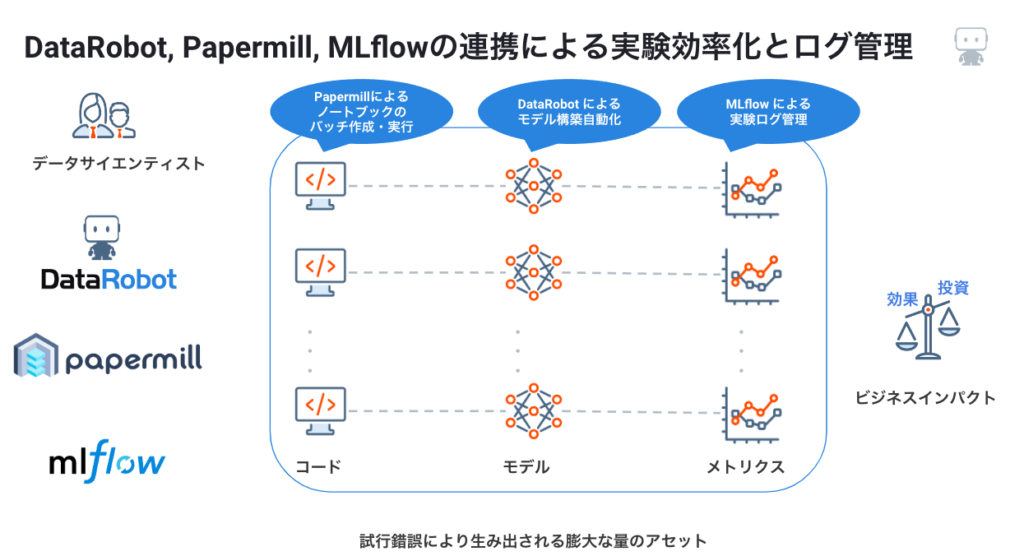
DataRobot, Papermill, MLflowの連携による実験効率化とログ管理
それでは、本稿で紹介するDataRobot、 Papermill、MLflowがどのように上記課題を解決するか解説します。まず、それぞれの道具の概要です。
データサイエンティストの道具その1:DataRobot
- DataRobotは、データサイエンティスト(DS)や開発者が機械学習モデルを迅速に開発、デプロイ、管理できるように設計された包括的かつオープンなエンドツーエンドのAIライフサイクル・プラットフォームです。
- GUIベースの操作だけでなく、Pythonクライアントを使うことができます。したがって、コードベースで、データの準備からモデルのトレーニング、評価、デプロイメント、モニタリングに至るまでのプロセスを自動化し、機械学習プロジェクトの複雑さと時間を大幅に削減します。
データサイエンティストの道具その2:Papermill
- Papermillは、ノートブックをパラメータ化して実行するためのオープンソースのツールであり、データサイエンスや機械学習のワークフローを自動化するために広く使用されています。
- ノートブックを入力として受け取り、実行時にパラメータを渡すことで、ノートブック内のコードを動的に実行することができます。これにより、異なるデータセットやパラメータで同じ分析を繰り返し実行する際の効率が大幅に向上します。
データサイエンティストの道具その3:MLflow
- MLflowは機械学習のライフサイクルを管理するためのオープンソースプラットフォームです。
- 機械学習の実験管理、モデルのトラッキング、デプロイメント、およびワークフローの全体を通しての管理を簡素化することを目的としています。
DataRobot、Papermill、MLflowを使うメリット
この3つの道具を使うメリットは、実験効率化とログ管理です。DataRobotは、GUI操作だけではなく、コードベースでモデルのトレーニングを自動化することができます。モデルのトレーニングには特徴量やアルゴリズムの選定も含まれ、その機能だけでもDSにとって鬼に金棒です。
さらに、Papermillを使うことでノートブックをバッチ実行できるため、DataRobotを用いた実験を効率化できます。たとえば、需要予測などの時系列分析では、学習データの期間や検定期間や特徴量セットについてさまざまなパターンを試します。学習データの期間で3種類、検定期間で2種類、特徴量セットで3種類あるケースでは、合計で3×2×3の18回分の実験をする必要があり、DataRobotでは18のエクスペリメント(プロジェクト)を作成することに対応します。その都度、毎回ノートブックを手動で作成していては大変ですし、ヒューマンエラーも多くなります。そこで、Papermillを使うことで、18のノートブックを自動で作成し、バッチ実行することができます。
同時に、MLflowを使うことで、18の実験結果を1つのダッシュボードで表示できます。
AIアクセラレーターのサンプルコード
それでは、AIアクセラレーターに公開されているサンプルコードを紹介します。サンプルコードでは、時系列モデルの作成を効率化しています。
以下の内容がシナリオです。
——-シナリオ——-
時系列モデルの作成では、試みるべき多くの実験があります。最も基本的なものには、複数の特徴量派生ウィンドウ(fdws)を試すことや、事前に既知の特徴量(kias)を有効にすることが含まれます。
<用語説明>
- 特徴量派生ウィンドウ(fdws):DataRobotの時系列モデリングにおいて、DataRobotが自動で派生する特徴量のローリングウィンドウ(fdws= -28 ~ 0 daysと指定すれば、過去28日間の移動平均、ラグ、差分などの特徴量が自動で生成される)
- 事前に既知の特徴量(kias):DataRobotの時系列モデリングにおいて、予測時点で値がわかっている特徴量のこと(休日やキャンペーンなど)
サンプルコードでは、実験を効率化するために、Papermillを用いてパラメータ(fdwsとkias)を変更しノートブックをバッチ実行します。パラメータを設定し、バッチ実行を指示するノートブックがバッチ実行用ノートブック(orchestration_notebook.ipynb)であり、その指示により複数の実験用ノートブック(experiment_notebook.ipynb)が作成され、バッチ実行が走るという関係になっています。機械学習モデル作成のエンジンはDataRobotを利用しており、実験ログはMLflowで管理します。
DataRobot、Papermill、MLflow連携の流れ
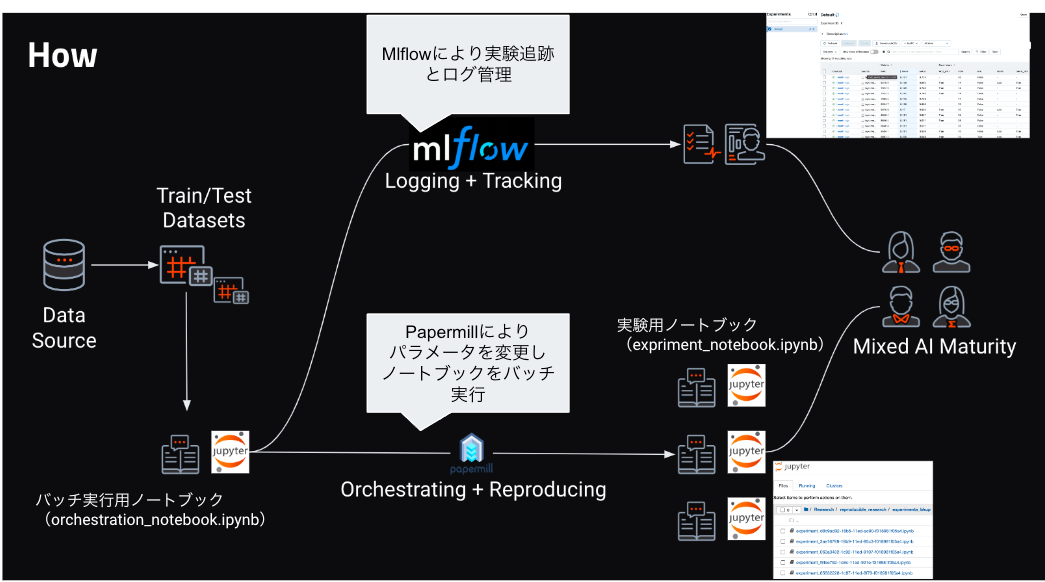
以下、バッチ実行用ノートブック(orchestration_notebook.ipynb)のコードの中身を詳しく解説します。
①パラメータの設定
シナリオに沿って、特徴量派生ウィンドウ(fdws)と事前に既知の特徴量(kias)に異なるパラメーターを与えて実験します。以下のセルの例に示されているように、3(fdwsが35,70,14の3種類)×2(kiasがFalseとTrueの2種類) = 6の異なる実験を行います。

②ノートブックのバッチ実行
①で定義したパラメータを実験用ノートブック(experiment_notebook.ipynb)に与え、バッチ実行します。for文でループ実行しており、ここでは6回分ループ実行が行われます。pmはPapermillのことで、引数として、
- input_path: 実験用ノートブックのパス
- output_path: 実験実行後のノートブックのパス
- parameters: 実験用ノートブックに与えるパラメータ
を指定します。
以下のセルを実行すると、自動でノートブックが6つ作成されて、バッチ実行が動きます。
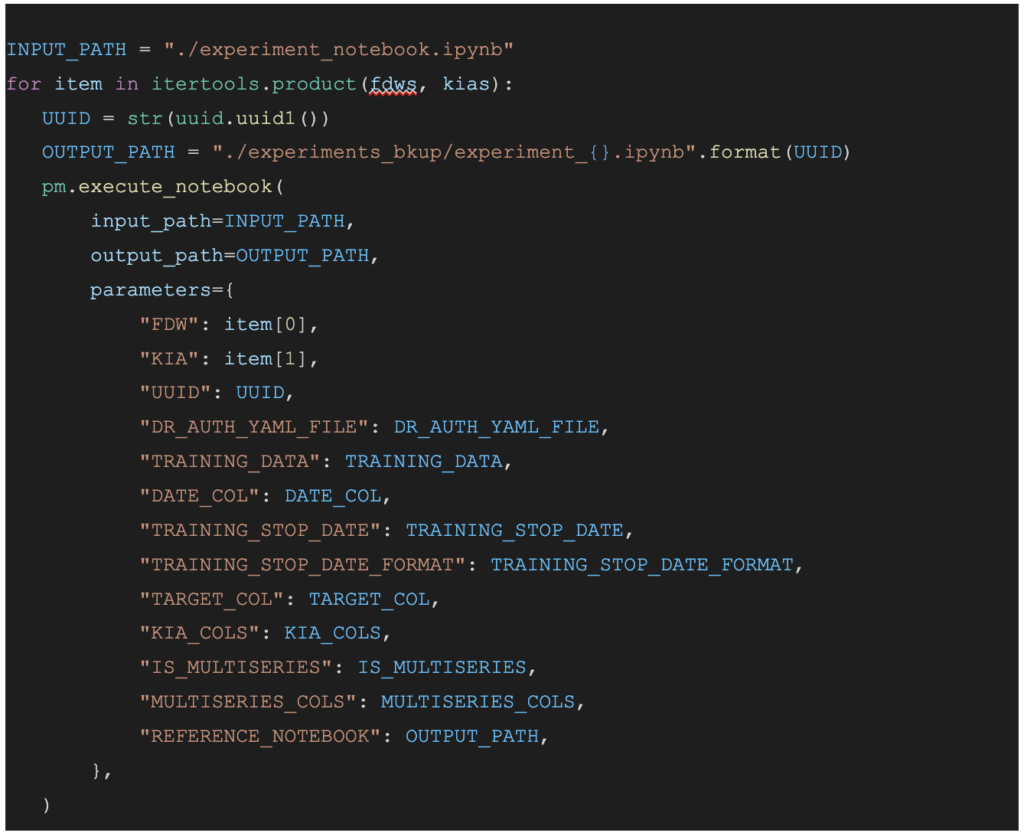
それでは、次に、実験用ノートブック(experiment_notebook.ipynb)の中身を見てみましょう。
①機械学習モデルの作成
機械学習モデルの作成にはDataRobotを用います。以下のセルは、検定スキー(time_partition)や特徴量セットの設定をしています。特徴量ウィンドウ(FDW)と事前に既知の特徴量(KIA)は、バッチ実行用ノートブック(orchestration_notebook.ipynb)から与えられたパラメータです。
以下のセルを実行すると、自動で複数のモデルが構築され、最も精度が良いモデルをDataRobotが選択してくれます。
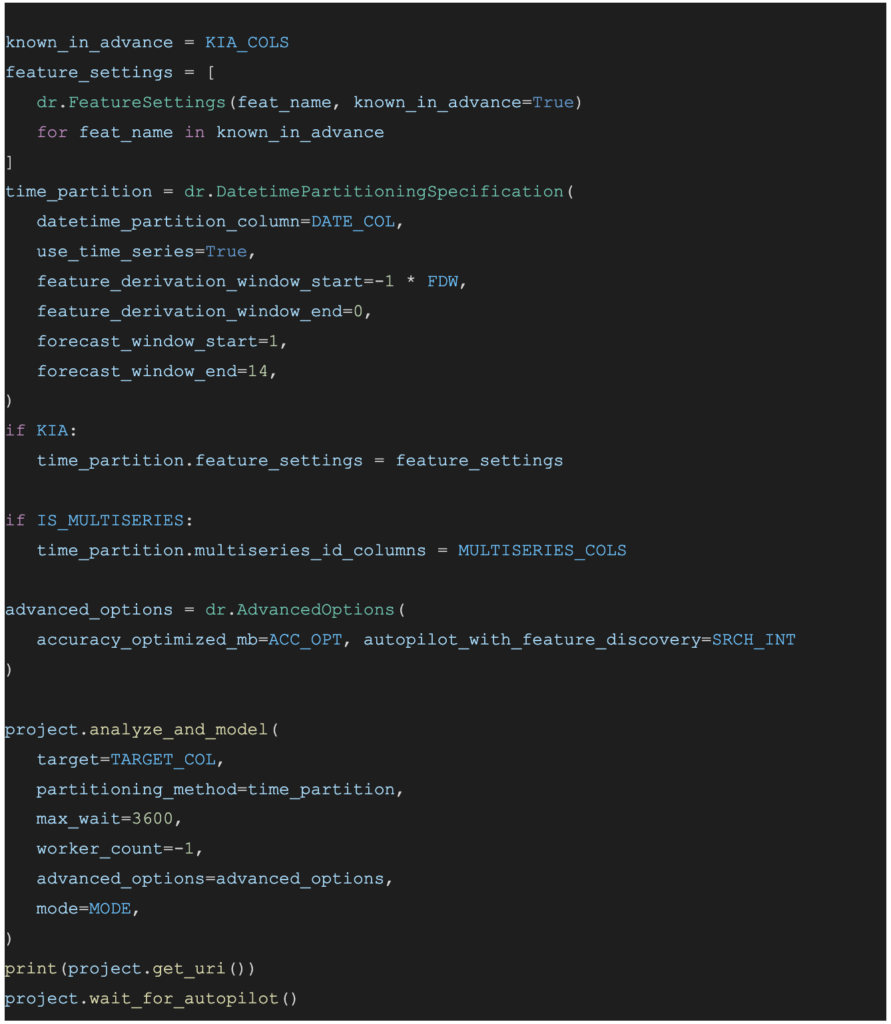
②予測の実行
最も精度が良いモデルを使って予測を実行します。

③実験ログ管理
予測値と実測値を比較して、精度を算出し、MLflowを使って実験ログを記録します。ここでは、変更したパラメータと各種精度指標のスコアを記録しています。
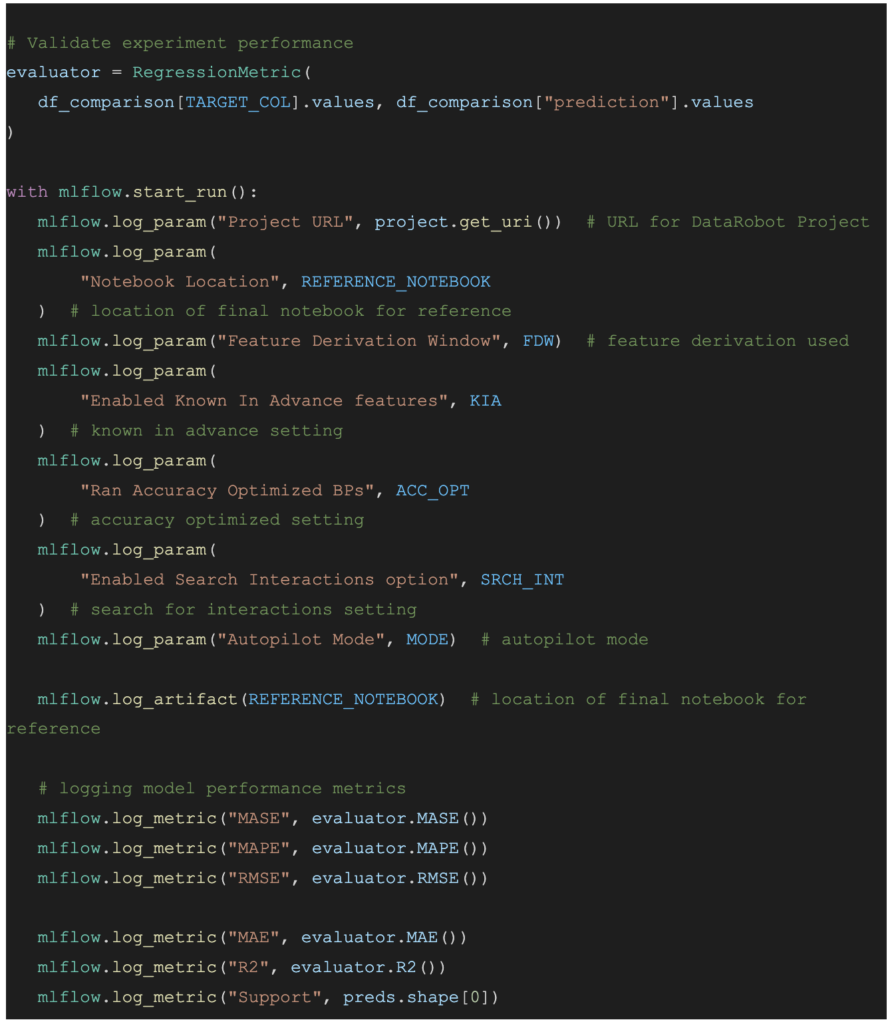
サンプルコードを実行すると以下のようなアウトプットが得られます。アウトプットからわかるように、この3つの道具を使うことで、実験を効率化できるだけでなく、コードとモデルとメトリックスを実行後にアセットとしてそれぞれ残すことができ、後任者がコードとモデルの中身を再確認することもできます。

機械学習の実験効率化とログ管理を両立させる方法
今回は、実験効率化とログ管理のために、以下の方法をご紹介しました。
- DataRobotとMLflowを使用して、機械学習の実験を追跡およびログする方法
- 利点:実験間での結果の一貫した比較が可能
- DataRobotとPapermillを使用して、機械学習の実験からアーティファクトを作成し、共同作業に必要な作業量を減らす方法
- 利点:エラーを回避し、手動の作業量を減らすための実験の自動化が可能
ぜひサンプルコードを参考に、皆さまのプロジェクトにご活用ください。具体的な実装などでお困りの際は弊社までお問い合わせください。

DataRobot データサイエンティストとして、小売・流通業界のお客さまの AI 活用/推進を支援。博士(工学)修了後、大手電機メーカーにて研究開発に従事。AIを用いた需要予測や材料の配合最適化シミュレーションに取り組んだ経験を有する。現在は、小売・流通業界を中心に複数のプロジェクトに従事し、AIによる継続的な価値創出を支援。
-
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分 -
DataRobot Summer Launchから生成AIによるAI消費の進歩を紹介
2023/10/10· 推定読書時間 1 分
最近のブログ記事