
AI活用のさらなるステージ:バイアスと公平性 Part 1
はじめに
DataRobotで主に政府公共領域やヘルスケア業界のお客様を担当しているデータサイエンティストの若月です。
機械学習によるAIが普及する中で、AIが倫理的な、公平な判断をしているかという観点にも焦点があてられるようになってきました。2020年に公開されたドキュメンタリー映画「CODED BIAS」では、白人男性より黒人女性の方が顔認識の精度が低くなってしまう例などをあげ、AIに関する社会問題を紹介しています。バイアスと公平性は、AIが社会に浸透してきた今こそ注目をしなければならない領域です。
本稿Part 1ではバイアスと公平性がなぜ重要なのか、その発生要因、機械学習モデルのバイアスをどのように評価するのかについて解説します。(Part 2では具体的にどのように機械学習モデルのバイアスを軽減するのか、機械学習プロジェクトにおいてどういった点に留意する必要があるのか、そしてDataRobotでどのようなことができるのかについて解説します)
バイアスと公平性とは
実証実験段階をクリアしたAIの社会実装が進む昨今、AIガバナンスの重要性が叫ばれるようになってきています。日本においても内閣府による「人間中心のAI社会原則」[1](2019年)や、経済産業省による「我が国のAIガバナンスの在り方」[2](2021年ver1.1に更新)「AI原則実践のためのガバナンス・ガイドライン」[3](2022年ver1.1に更新)が発表されています。このようにAIの社会実装のガイドライン整備が進んできているのは、AIがただの実証実験にとどまらず、実際のビジネス・業務において当たり前のように活用されるようになったことの証左と言えるでしょう。一方で、筆者の所見ではAI活用のあり方を十分に設計・検討した上で実践できている組織は、2022年現在においてはまだ多いとは言えないように見受けられます。
AIガバナンスは非常に広範に渡る概念ではありますが、中でもモデルの公平性についてはモデル開発者・利用者含むステークホルダー全員がしっかりと意識する必要があります。先述の「人間中心のAI社会原則」においても、「公平性、説明責任及び透明性の原則」が定められており、AIの利用によって人々が不当な差別・不当な扱いを受けないように説明責任・信頼性が担保される必要があるとされています。
なぜAIの利用による差別が発生しうるのでしょうか。機械学習では過去のデータに基づいて将来の予測を行うので、学習したデータに意図的か意図的でないかにかかわらずバイアスが含まれていた場合、そこから得られる予測結果は偏見・ステレオタイプを含んだ不公平なものになっている恐れがあります。
たとえば、採用活動における書類選考過程をAIを用いて効率化しようとするプロジェクトがあったとします。データサイエンティストは過去の履歴書データなどを使ってモデルを作成しますが、もし過去の応募者・内定者の男女比に偏り(バイアス)があった場合、そのデータから作成した機械学習モデルは男女のどちらか一方に有利な評価を行う不公平なものになってしまっている可能性があります。無論「不公平な」モデルを実際に使用して意思決定を行うのは男女雇用機会均等の観点から望ましくないといえます。
このように単純に精度のみを追い求めて(知らず知らずのうちに)公平性を欠いたAIモデルを作ってしまい、もし将来不公平なモデルが作られていたこと/運用されていたことが発覚すればプロジェクトの中止、最悪の場合企業・組織の社会的信用にまで影響を与えてしまう可能性があります(米国における再犯予測システムの事例)。したがってプロジェクトに携わる全員が正しくモデルの公平性を理解し、推進する必要があります。
バイアス発生の根本原因
不公平なAIモデルが作られる原因となるバイアスはデータそのものに内在しますが、バイアス発生の根本原因はデータの収集・生成プロセスにあると言えるでしょう。具体的にまとめると以下3つの根本原因が考えられます。
データ量
データ量が少ない、もしくは全体としてはデータ量が多くても特定の属性に関するデータ量が少ないという状況では、属性によっては適切な予測ができないかもしれません。
例えば、国政選挙において誰が当選するかを予測するAIを仮想的に考えてみましょう。日本では2022年現在も、女性の政治参加率の低さがたびたび指摘されています。実際にそれを裏付けるデータとして女性国会議員の割合をみると2018年2月現在で衆議院10.1%(47人)、参議院20.7%(50人)と報告されています(内閣府による発表[4])。
女性が少ない過去の実績データを使って作成したモデルによって国会議員全体の当選予測をしようとすると、データ数の多い男性候補者に比べて女性候補者の適切な予測ができない可能性があります。このように、社会的・歴史的背景によってそもそも特定の属性のデータが少ない、というバイアスは様々な分野で見られます。
サンプリング
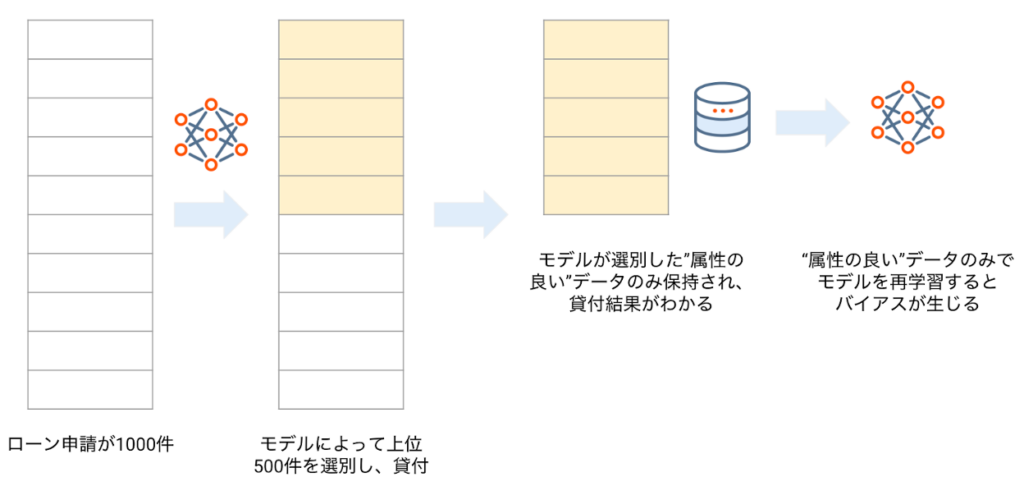
データ量の例とも一部共通しますが、本来の母集団から特定の属性のみを抽出しているような状況では選択(セレクション)バイアスが発生します(参考:機械学習を用いた要因分析 – 理論編 Part 2)。例えば金融機関における与信審査において機械学習モデルを使って判定を行っている場合、モデルによって選別された”属性の良い”グループのみのデータが収集されることになるので、これもセレクションバイアスといえます。
ラベルづけ等、意思決定におけるバイアス
ビジネスデータにおいては人がラベルづけすることも多いですが、その人の判断そのものにバイアスが含まれていた場合、生成されたラベルにもバイアスが入り込むことになります。仮に、ある企業で男性の方が採用時に優遇されているという慣行(逆も然り)があったなら、採用予測モデル構築のために使われるトレーニングデータにはバイアスが含まれていると言えます。
公平性の考え方:公平性指標
モデルの公平性はどのように判断できるでしょうか。実はモデルの公平性を定量的に測定する指標がいくつか提案されていますが、どの指標を選択するかはプロジェクトによって変わってきます。例えば採用活動において男女の公平性を担保しようとしても、採用する男女の絶対数を合わせるのか、応募者に対する採用人数の比率を男女で合わせるのか、それは組織の方針によって決まってくるでしょう。以下では公平性指標の概要をご紹介します。(詳細は、DataRobotの公式ドキュメントもご参照ください)
具体例を示しながら説明するため、本章ではある従業員の賃金が一定金額以上かどうか(高いか低いか)を予測する二値分類モデルを仮想例として取り上げます。また、”好ましい”あるいは”好ましくない”という用語が出てきますが、この例では賃金が高いのが”好ましい”予測で、賃金が低いのが”好ましくない”予測とします。
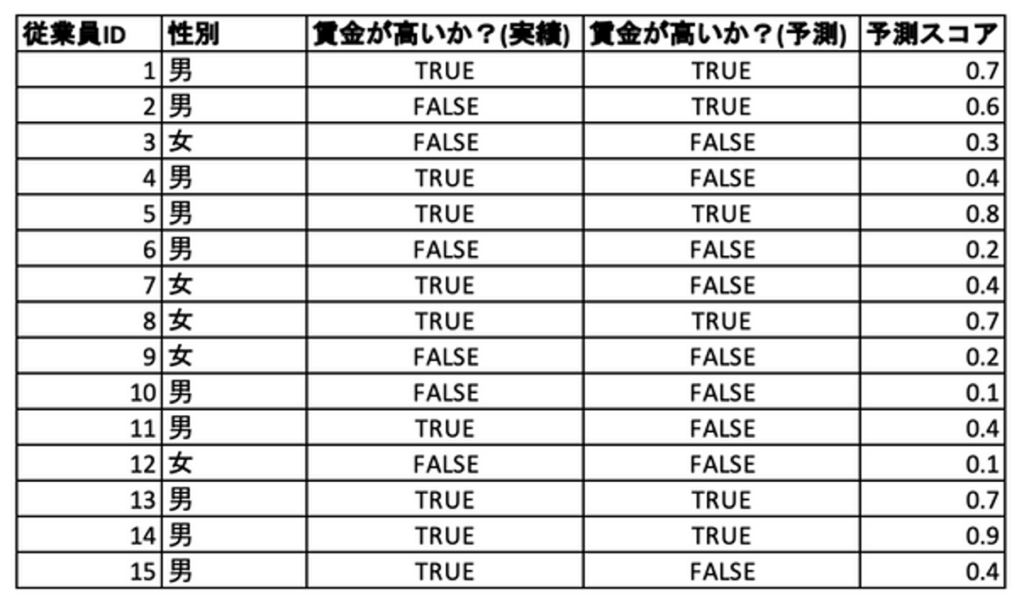
それでは、以下のような男性10名、女性5名のデータをもとにいくつかの公平性指標を算出してみましょう。いずれの指標も男女間で値が近いほど公平である、と判断します。 本例ではモデルを性別に対して公平にしていきたいので、特徴量「性別」を予測結果に対して公平性を担保したいカテゴリ特徴量(以下”保護された特徴量”)と考えます。
公平性指標の一覧
各公平性指標の具体的な説明に入る前に、どのようなものがあるのか一覧で見てみましょう。
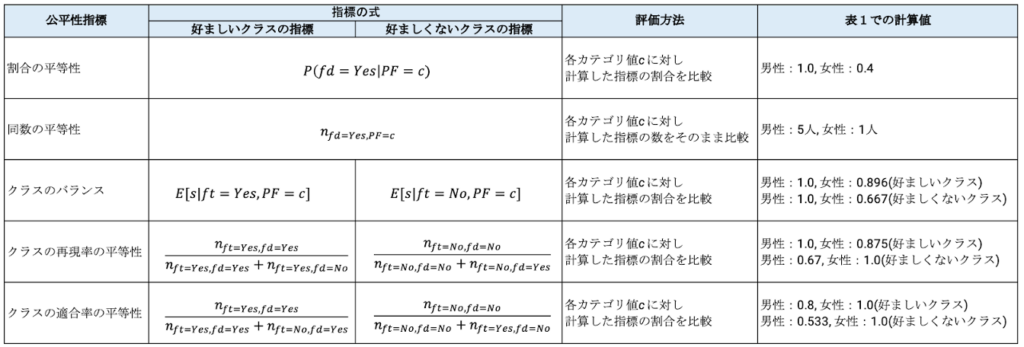
また、数式の表現については以下をご参照ください。

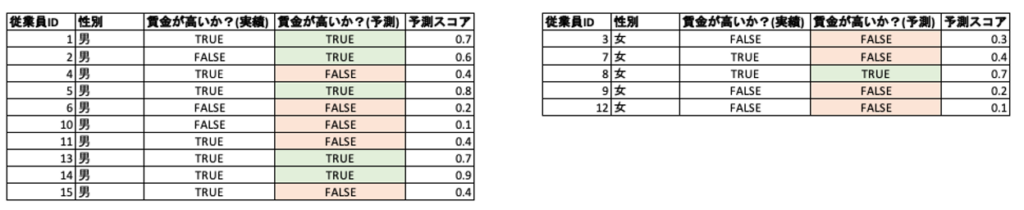
割合の平等性(Proportional Parity)
定義: 保護された特徴量の各クラス(男女)について、好ましい(賃金が高い)予測がなされたデータの全体に対する割合。
イメージ: 賃金が高いと予測した割合が男女で公平であるかどうかを確認します。
計算: 表1のデータでは、賃金が高いと予測されているのが男性だと10人中5人なので0.5になるのに対して、女性は5人中1人なので0.2です。なお、DataRobotでは最も値が高くなるクラスで正規化した値がデフォルトで表示されるので、男性だと0.5/0.5 = 1.0, 女性だと0.2/0.5 = 0.4となります。(この表示ルールは他の指標でも同様です)
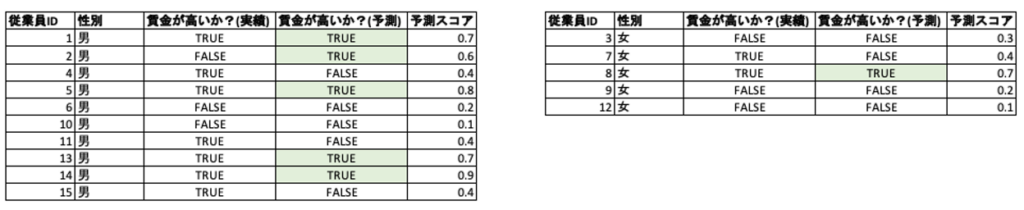
同数の平等性(Equal Parity)
定義: 保護された特徴量の各クラス(男女)について、好ましい(賃金が高い)と予測された数。
イメージ: 賃金が高いと予測した数(割合ではない)が男女で公平であるかどうかを確認します。
計算: 表1の例では、賃金が高いと予測されているのが男性5人に対して、女性は1人です(正規化すると男性1.0, 女性0.2)。分類結果の絶対数を合わせたいときはこの指標を使うのが良いでしょう。
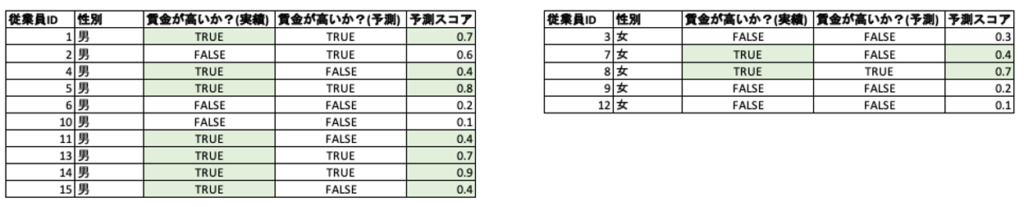
好ましいクラスのバランス(Favorable Class Balance) / 好ましくないクラスのバランス(Unfavorable Class Balance)
定義: 好ましいクラスのバランスは、保護された特徴量の各クラス(男女)について、実績として好ましい(賃金が高い)クラスに属するデータの予測スコアの平均。
イメージ: 賃金が高いと予測したラベルの割合ではなく、賃金が高いと予測する確率に公平性があるかどうかを確認します。予測する確率でランキングを作る際に用いられます。
計算: 表1の例では、「好ましいクラスのバランス」は正規化前の値が男性は0.614に対して女性は0.55です。「好ましくないクラスのバランス」では逆に、実績として賃金が低いクラスに属するデータの予測スコアの平均になります。
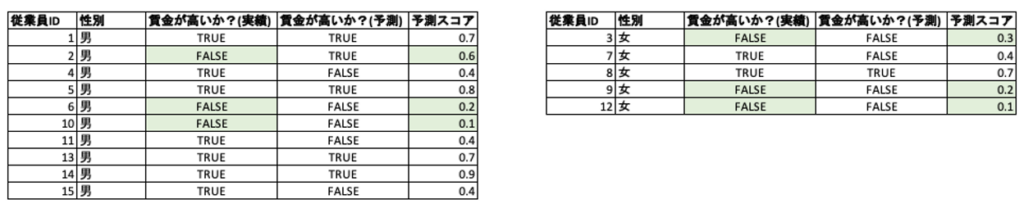
好ましいクラスの再現率の平等性(True Favorable Rate Parity) / 好ましくないクラスの再現率の平等性(True Unfavorable Rate Parity)
定義: 好ましいクラスの再現率の平等性は、保護された特徴量の各クラス(男女)について、好ましい(賃金が高い)クラスの再現率(Recall)。
イメージ: 精度評価指標として再現率を重視するようなプロジェクト(例えば医療業界における疾患の判定など)において、男女間での差が少ないモデルであることを担保したいときに用いられます。
計算: 「好ましいクラスの再現率の平等性」は表1の例では、正規化前の値が男性は4/7 = 0.57に対して女性は1/2 = 0.50です。
「好ましくないクラスの再現率の平等性」では逆に賃金が低いクラスの再現率を確認します。
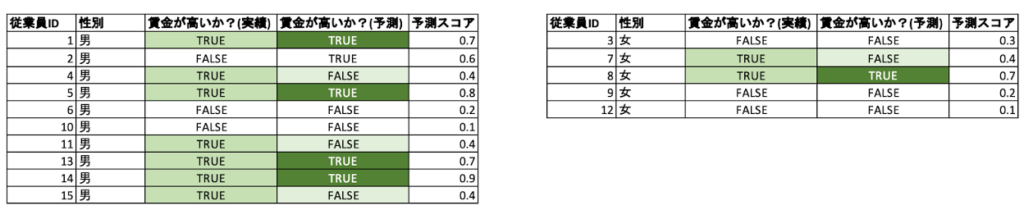

好ましいクラスの適合率の平等性(Favorable Predictive Value Parity) / 好ましくないクラスの適合率の平等性(Unfavorable Predictive Value Parity)
定義: 好ましい予測値の平等性は、保護された特徴量の各クラス(男女)について、好ましい(賃金が高い)クラスの適合率(Precision)。
イメージ: 好ましいクラスの再現率の平等性と同じ発想ですが、精度評価指標として適合率を重視するようなプロジェクト(例えば児童虐待やハラスメントの判別など、モデルが検知した結果が間違っていたときに大きな問題になりかねないために偽陽性をなるべく少なくしたいテーマ)において、男女間での差が少ないモデルであることを担保したいときに用いられます。
計算: 「好ましいクラスの適合率の平等性」は、表1を例にすると、正規化前の値が男性は4/5 = 0.8に対して女性は1/1 = 1.0です。
「好ましくないクラスの適合率の平等性」では逆に賃金が低いクラスの適合率を確認します。


繰り返しになりますが、どういった指標を用いるかはプロジェクトによって変わってきますし、実際の計算例をみても男女間での差異が指標によってもかなり異なってくることが見て取れます(指標次第で男女間での値の大小が逆転しているものすらあります!)。従って、「〇〇を選べば良い」といった類のものではなく、ユースケースやドメイン知識、組織のポリシーに基づいて適切な指標をプロジェクトの担当者が選択する必要があります。
別の仮想例として「採用時の応募者一次スクリーニングプロジェクト」を考えてみましょう。もし組織の採用ポリシーが「応募人数に対する採用人数の割合について、男女間で大きな差が生じないようにする」であれば、公平性の指標は「割合の平等性」を採用するのが適正と考えられます。しかし、もし採用ポリシーが「応募者の男女比に関係なく、男女同数の内定者をだす」であれば、「同数の平等性」を採用するのが適正と考えられます。
このように、公平性指標の選択には絶対基準が存在するわけではなく、機械学習モデルで解決しようとしている課題(ユースケース)やそのモデルの運用ポリシー、組織のポリシー・ルールを反映させた指標を柔軟に選ぶ必要があります。
まとめ
以上、本稿Part1では以下のトピックに注目して解説しました。
- バイアスと公平性とは、その重要性
- バイアスの発生原因
- 公平性指標
本稿で述べた通り、バイアスと公平性はAIが組織的に活用されるようになった今こそ、改めてその重要性を認識する必要があります。AIの活用が実証実験にとどまっていた段階ではあまり意識が向けられていなかったかもしれませんが、これからますますAIの活用が広がる中でデータサイエンティストはもちろん、意思決定者からAIのユーザーに至るまで全員の理解は必須と言っても過言ではないでしょう。まずは読者の皆様が携わられている機械学習プロジェクトにおいて公平性を欠いたモデルが作られていないか、考えてみてはいかがでしょうか。
次回、本稿Part 2では以下を解説します。2023年1月に公開予定です。
- バイアス軽減のさまざまな手法
- 実際の機械学習プロジェクト推進における留意点
- モデルのバイアスに対してDataRobotができること
参考文献
[1] 「人間中心のAI社会原則」(内閣府) (https://www8.cao.go.jp/cstp/ai/ningen/ningen.html) (2022年11月7日に利用)
[2] 「我が国のAIガバナンスの在り方 ver1.1」 (経済産業省)(https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/2021070901_report.html) (2022年11月7日に利用)
[3]「AI原則実践のためのガバナンス・ガイドライン ver. 1.1」 (経済産業省)(https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20220128_report.html) (2022年11月7日に利用)
[4]「男女共同参画白書(概要版) 平成30年版」(内閣府) (https://www.gender.go.jp/about_danjo/whitepaper/h30/gaiyou/html/honpen/b1_s01.html) (2022年11月7日に利用)

大学・大学院で航空宇宙工学を専攻したのち証券会社に新卒入社。エンジニアチームリードとして社内のデジタル化を推進する一方で、データ分析組織の立ち上げにおいてDataRobotの導入・活用推進に取り組む。その後国内ベンチャー企業でテレビ広告の分析に従事したのち、2022年1月から現職。DataRobotではデータサイエンティストとして主に官公庁・自治体やヘルスケア業界のお客様のAI活用と変革を支援。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事