

End-to-End Time Series Demand Forecasting What-If App
This demand forecasting what-if app allows users to adjust certain known in advance variable values to see how changes in those factors might affect the forecasted demand.
Build with Free TrialSome examples of factors that might be adjusted include marketing promotions, pricing, seasonality, or competitor activity. By using the app to explore different scenarios and adjust key inputs, users can make more accurate predictions about future demand and plan accordingly.
Additional Resources
- This app is a third instalment of a three-part series on demand forecasting. Previous accelerators can be used as a starting point to create a model deployment for the app.
- The first accelerator focuses on handling common data and modeling challenges, identifies common pitfalls in real-life time series data, and provides helper functions to scale experimentation.
- The second accelerator provides the building blocks for cold start modeling workflow on series with limited or no history.
- DataRobot’s API reference documentation
App overview
The following steps outline how to run the app.
- Install the packages according to the configuration file
requirements.txt:pip install -r requirements.txt - Update the
config/config.tomlfile with:API_KEY: In DataRobot, navigate to Developer Tools by clicking on the user icon in the top-right corner. From here you can generate a API Key that you will use to authenticate to DataRobot. You can find more details on creating an API key in the DataRobot documentation.ENDPOINT: Determine your DataRobot API Endpoint. The API endpoint is the same as your DataRobot UI root. Replace {datarobot.example.com} with your deployment endpoint. API endpoint root:https://{datarobot.example.com}/api/v2. For users of the AI Cloud platform, the endpoint ishttps://app.datarobot.com/api/v2DATE_COL: The datetime partition column defined before the project creation.SERIES_ID: The multiseries ID column defined before the project creation.TARGET: The target column defined before the project creation.KA_COLS: A list of KA features.DEPLOYMENT_ID: The deployment ID to use for making predictions. It can be created with the previous accelerator. If you used the above accelerator to generate the deployment ID, you can use this prediction file to test the app.
- Run the app with the command:
streamlit run demand_forecasting_app.py. - The Streamlit app should be available in your browser: http://localhost:8501.
How to use the app
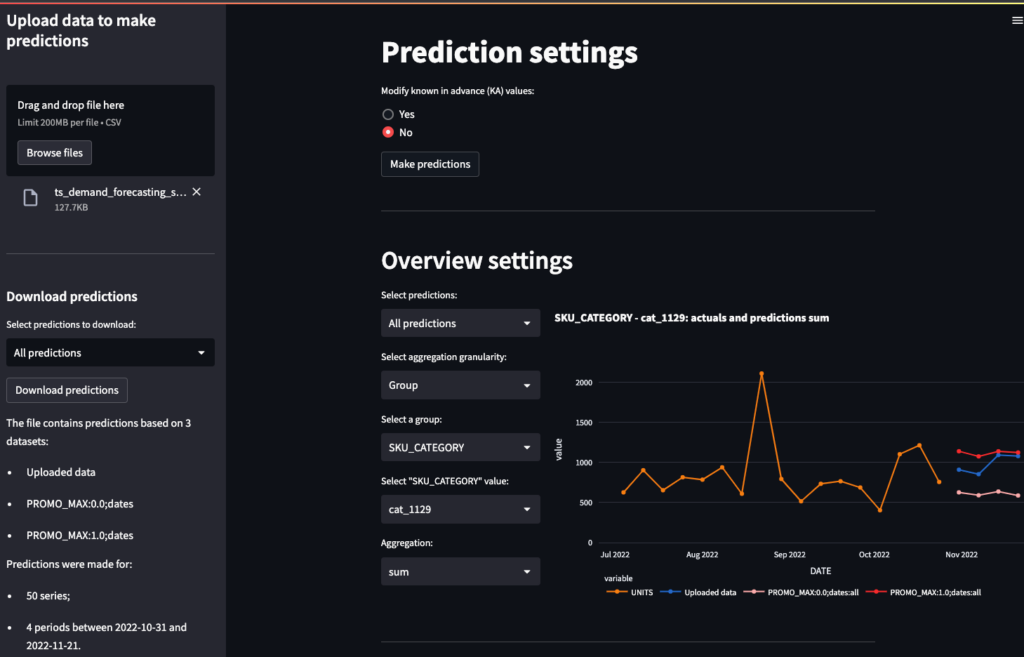
- Upload the scoring dataset.
- Update KA features or use the uploaded data as-is.
- Run predictions.
- Plot results: total, per group, or individual series.
- Download predictions per scenario or all runs together.
Get Started with Demand Forecasting

Related AI Accelerators
End-to-End Time Series Demand Forecasting WorkflowIn this first installment of a three-part series on demand forecasting, this accelerator provides the building blocks for a time-series experimentation and production workflow.
End-to-End Time Series Cold Start Demand ForecastingThis second accelerator of a three-part series on demand forecasting provides the building blocks for cold start modeling workflow on series with limited or no history. This notebook provides a framework to compare several approaches for cold start modeling.
Explore more AI Accelerators
-
HorizontalObject Classification on Video with DataRobot Visual AI
This AI Accelerator demonstrates how deep learning model trained and deployed with DataRobot platform can be used for object detection on the video stream (detection if person in front of camera wears glasses).
Learn More -
HorizontalPrediction Intervals via Conformal Inference
This AI Accelerator demonstrates various ways for generating prediction intervals for any DataRobot model. The methods presented here are rooted in the area of conformal inference (also known as conformal prediction).
Learn More -
HorizontalReinforcement Learning in DataRobot
In this notebook, we implement a very simple model based on the Q-learning algorithm. This notebook is intended to show a basic form of RL that doesn't require a deep understanding of neural networks or advanced mathematics and how one might deploy such a model in DataRobot.
Learn More -
HorizontalDimensionality Reduction in DataRobot Using t-SNE
t-SNE (t-Distributed Stochastic Neighbor Embedding) is a powerful technique for dimensionality reduction that can effectively visualize high-dimensional data in a lower-dimensional space.
Learn More