


Choosing the Right Database for Your Generative AI Use Case
Ways of Providing Data to a Model
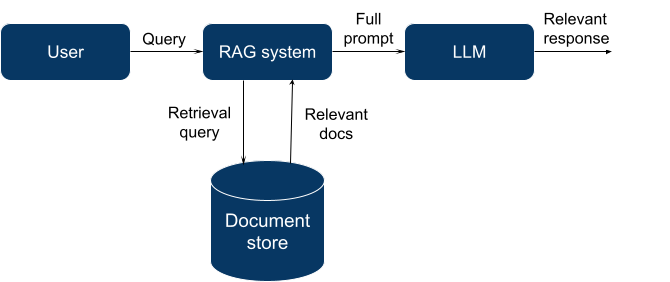
Many organizations are now exploring the power of generative AI to improve their efficiency and gain new capabilities. In most cases, to fully unlock these powers, AI must have access to the relevant enterprise data. Large Language Models (LLMs) are trained on publicly available data (e.g. Wikipedia articles, books, web index, etc.), which is enough for many general-purpose applications, but there are plenty of others that are highly dependent on private data, especially in enterprise environments.
There are three main ways to provide new data to a model:
- Pre-training a model from scratch. This rarely makes sense for most companies because it is very expensive and requires a lot of resources and technical expertise.
- Fine-tuning an existing general-purpose LLM. This can reduce the resource requirements compared to pre-training, but still requires significant resources and expertise. Fine-tuning produces specialized models that have better performance in a domain for which it is finetuned for but may have worse performance in others.
- Retrieval augmented generation (RAG). The idea is to fetch data relevant to a query and include it in the LLM context so that it could “ground” its own outputs in that information. Such relevant data in this context is referred to as “grounding data”. RAG complements generic LLM models, but the amount of information that can be provided is limited by the LLM context window size (amount of text the LLM can process at once, when the information is generated).
Currently, RAG is the most accessible way to provide new information to an LLM, so let’s focus on this method and dive a little deeper.
Retrieval Augmented Generation
In general, RAG means using a search or retrieval engine to fetch a relevant set of documents for a specified query.
For this purpose, we can use many existing systems: a full-text search engine (like Elasticsearch + traditional information retrieval techniques), a general-purpose database with a vector search extension (Postgres with pgvector, Elasticsearch with vector search plugin), or a specialized database that was created specifically for vector search.
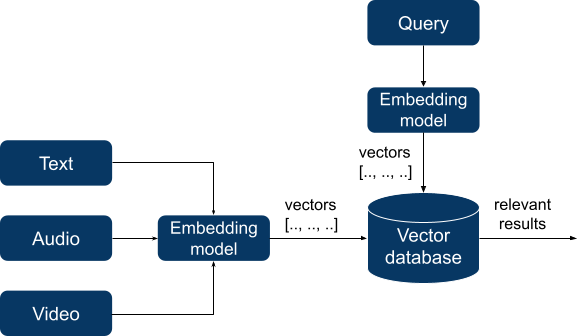
In two latter cases, RAG is similar to semantic search. For a long time, semantic search was a highly specialized and complex domain with exotic query languages and niche databases. Indexing data required extensive preparation and building knowledge graphs, but recent progress in deep learning has dramatically changed the landscape. Modern semantic search applications now depend on embedding models that successfully learn semantic patterns in presented data. These models take unstructured data (text, audio, or even video) as input and transform them into vectors of numbers of a fixed length, thus turning unstructured data into a numeric form that could be used for calculations Then it becomes possible to calculate the distance between vectors using a chosen distance metric, and the resulting distance will reflect the semantic similarity between vectors and, in turn, between pieces of original data.
These vectors are indexed by a vector database and, when querying, our query is also transformed into a vector. The database searches for the N closest vectors (according to a chosen distance metric like cosine similarity) to a query vector and returns them.
A vector database is responsible for these 3 things:
- Indexing. The database builds an index of vectors using some built-in algorithm (e.g. locality-sensitive hashing (LSH) or hierarchical navigable small world (HNSW)) to precompute data to speed up querying.
- Querying. The database uses a query vector and an index to find the most relevant vectors in a database.
- Post-processing. After the result set is formed, sometimes we might want to run an additional step like metadata filtering or re-ranking within the result set to improve the outcome.
The purpose of a vector database is to provide a fast, reliable, and efficient way to store and query data. Retrieval speed and search quality can be influenced by the selection of index type. In addition to the already mentioned LSH and HNSW there are others, each with its own set of strengths and weaknesses. Most databases make the choice for us, but in some, you can choose an index type manually to control the tradeoff between speed and accuracy.
At DataRobot, we believe the technique is here to stay. Fine-tuning can require very sophisticated data preparation to turn raw text into training-ready data, and it’s more of an art than a science to coax LLMs into “learning” new facts through fine-tuning while maintaining their general knowledge and instruction-following behavior.
LLMs are typically very good at applying knowledge supplied in-context, especially when only the most relevant material is provided, so a good retrieval system is crucial.
Note that the choice of the embedding model used for RAG is essential. It is not a part of the database and choosing the correct embedding model for your application is critical for achieving good performance. Additionally, while new and improved models are constantly being released, changing to a new model requires reindexing your entire database.
Evaluating Your Options
Choosing a database in an enterprise environment is not an easy task. A database is often the heart of your software infrastructure that manages a very important business asset: data.
Generally, when we choose a database we want:
- Reliable storage
- Efficient querying
- Ability to insert, update, and delete data granularly (CRUD)
- Set up multiple users with various levels of access for them (RBAC)
- Data consistency (predictable behavior when modifying data)
- Ability to recover from failures
- Scalability to the size of our data
This list is not exhaustive and might be a bit obvious, but not all new vector databases have these features. Often, it is the availability of enterprise features that determine the final choice between a well-known mature database that provides vector search via extensions and a newer vector-only database.
Vector-only databases have native support for vector search and can execute queries very fast, but often lack enterprise features and are relatively immature. Keep in mind that it takes years to build complex features and battle-test them, so it’s no surprise that early adopters face outages and data losses. On the other hand, in existing databases that provide vector search through extensions, a vector is not a first-class citizen and query performance can be much worse.
We will categorize all current databases that provide vector search into the following groups and then discuss them in more detail:
- Vector search libraries
- Vector-only databases
- NoSQL databases with vector search
- SQL databases with vector search
- Vector search solutions from cloud vendors
Vector search libraries
Vector search libraries like FAISS and ANNOY are not databases – rather, they provide in-memory vector indices, and only limited data persistence options. While these features are not ideal for users requiring a full enterprise database, they have very fast nearest neighbor search and are open source. They offer good support for high-dimensional data and are highly configurable (you can choose the index type and other parameters).
Overall, they are good for prototyping and integration in simple applications, but they are inappropriate for long-term, multi-user data storage.
Vector-only databases
This group includes diverse products like Milvus, Chroma, Pinecone, Weaviate, and others. There are notable differences among them, but all of them are specifically designed to store and retrieve vectors. They are optimized for efficient similarity search with indexing and support high-dimensional data and vector operations natively.
Most of them are newer and might not have the enterprise features we mentioned above, e.g. some of them don’t have CRUD, no proven failure recovery, RBAC, and so on. For the most part, they can store the raw data, the embedding vector, and a small amount of metadata, but they can’t store other index types or relational data, which means you will have to use another, secondary database and maintain consistency between them.
Their performance is often unmatched and they are a good option when having multimodal data (images, audio or video).
NoSQL databases with vector search
Many so-called NoSQL databases recently added vector search to their products, including MongoDB, Redis, neo4j, and ElasticSearch. They offer good enterprise features, are mature, and have a strong community, but they provide vector search functionality via extensions which might lead to less than ideal performance and lack of first-class support for vector search. Elasticsearch stands out here as it is designed for full-text search and already has many traditional information retrieval features that can be used in conjunction with vector search.
NoSQL databases with vector search are a good choice when you are already invested in them and need vector search as an additional, but not very demanding feature.
SQL databases with vector search
This group is somewhat similar to the previous group, but here we have established players like PostgreSQL and ClickHouse. They offer a wide array of enterprise features, are well-documented, and have strong communities. As for their disadvantages, they are designed for structured data, and scaling them requires specific expertise.
Their use case is also similar: good choice when you already have them and the expertise to run them in place.
Vector search solutions from cloud vendors
Hyperscalers also offer vector search services. They usually have basic features for vector search (you can choose an embedding model, index type, and other parameters), good interoperability within the rest of the cloud platform, and more flexibility when it comes to cost, especially if you use other services on their platform. However, they have different maturity and different feature sets: Google Cloud vector search uses a fast proprietary index search algorithm called ScaNN and metadata filtering, but is not very user-friendly; Azure Vector search offers structured search capabilities, but is in preview phase and so on.
Vector search entities can be managed using enterprise features of their platform like IAM (Identity and Access Management), but they are not that simple to use and suited for general cloud usage.
Making the Right Choice
The main use case of vector databases in this context is to provide relevant information to a model. For your next LLM project, you can choose a database from an existing array of databases that offer vector search capabilities via extensions or from new vector-only databases that offer native vector support and fast querying.
The choice depends on whether you need enterprise features, or high-scale performance, as well as your deployment architecture and desired maturity (research, prototyping, or production). One should also consider which databases are already present in your infrastructure and whether you have multimodal data. In any case, whatever choice you will make it is good to hedge it: treat a new database as an auxiliary storage cache, rather than a central point of operations, and abstract your database operations in code to make it easy to adjust to the next iteration of the vector RAG landscape.
How DataRobot Can Help
There are already so many vector database options to choose from. They each have their pros and cons – no one vector database will be right for all of your organization’s generative AI use cases. That is why it’s important to retain optionality and leverage a solution that allows you to customize your generative AI solutions to specific use cases, and adapt as your needs change or the market evolves.
The DataRobot AI Platform lets you bring your own vector database – whichever is right for the solution you’re building. If you require changes in the future, you can swap out your vector database without breaking your production environment and workflows.
Nick Volynets is a senior data engineer working with the office of the CTO where he enjoys being at the heart of DataRobot innovation. He is interested in large scale machine learning and passionate about AI and its impact.
-
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read -
6 Reasons Why Generative AI Initiatives Fail and How to Overcome Them
February 8, 2024· 9 min read
Latest posts
