


How to Improve Anti-Money Laundering Programs with AutoML
How big a problem is anti-money laundering (AML)? Worldwide, it costs businesses $2 trillion every year and is directly tied to an array of criminal activities. For financial organizations, AML can present a relentless hurdle. Among millions of transactions, AML teams must look for that small but mighty percentage of transactions that are problematic. And that takes plenty of time and resources.
The good news is that AI is a perfect antidote to money laundering. Even better news is that we’re not starting from scratch. Most financial institutions have an anti-money laundering (AML) process in place that AI can plug right into to enhance efficiencies.
Traditionally, transactions are run through a rules-based system, which will determine if a transaction is suspicious. If a transaction is deemed potentially suspicious, a suspicious activity report (SAR) is filed and it goes through a manual review process. This is an inefficient way to do things and creates a big pile of alerts that are generally unranked—a process that creates many false positives.
By inserting AI into the existing process, we can rank suspicious activity, determine which ones are actually worth investigating as a priority, and make the whole process more efficient, allowing the experts to focus their attention on the highest risk alerts first.
What Does the Model Building Process Look Like?
Speed. Quality. Transparency. These are the three criteria that are essential to any successful anti-money laundering program. Finding suspicious activity is like trying to hit a moving target. Data science teams need to move fast, and they need to find high priority suspicious activity without chasing after false positives. And because financial services is such a highly regulated industry, the explanations need to be fully transparent—ones that can be easily explained to regulators and stakeholders.
Enter DataRobot to speed up the process exponentially, reduce false positives, and automatically create compliance reports, saving data scientists hours of manual work. In our webinar, How to Improve Anti-Money Laundering Programs with Automated Machine Learning, I take a deep dive into how financial organizations can use DataRobot to win against money launderers.
Building Inside the DataRobot AI Platform
Start by selecting a data source. Once you go into the AI Catalog, you can see all the tables you’re already connected to. Here we are using Google BigQuery.
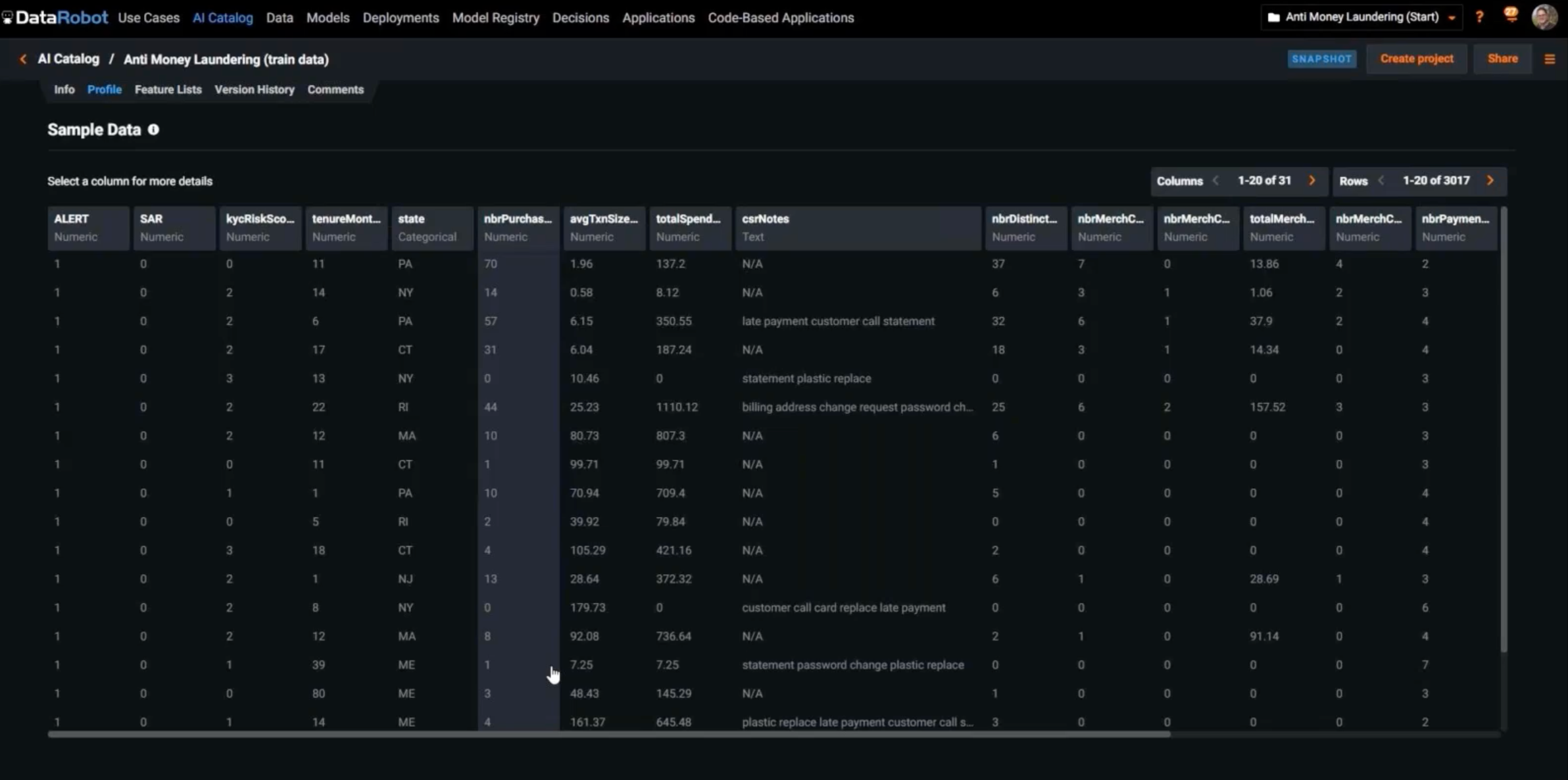
First, though, let’s look at the data. In this sample dataset, we see the historical data we used to train our models. We can see that alerts were generated some time ago, each of which may or may not have had a suspicious activity report (SAR) filed. There’s also a lot of other contextual data here–customer risk score, the date, total spend, and even the call center notes (text data).
Next we create the modeling project.
Remember that my goals are threefold:
- Accelerate the process of identifying problematic transactions. (Speed)
- Be more accurate in identifying suspicious activity. (Quality)
- Explain and document each step. (Transparency)
Once you bring in the data, DataRobot will ask you what you want to predict. We’re selecting SAR, and DataRobot will first show you a quick distribution of SAR in your data. It’s telling you that this is what your target looks like.
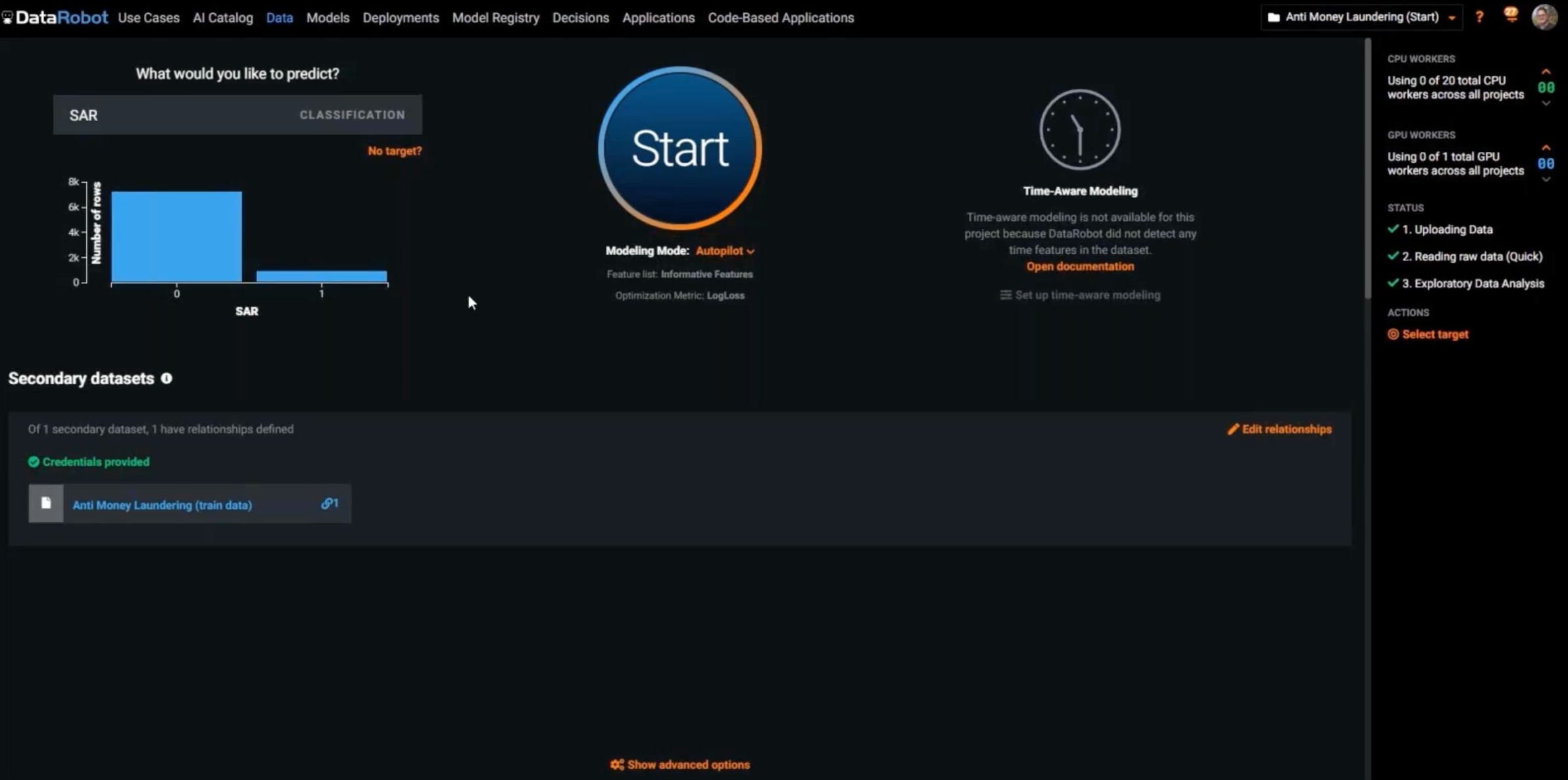
Secondary datasets. In addition to the primary dataset, DataRobot can easily automatically connect to new datasets that could enrich the training data. DataRobot automatically joins all input datasets and generates new features that can improve model accuracy.
DataRobot will also automatically identify any data quality issue–inliers, outliers, too many zeros, any potential problems—so that you stay on track with quality as you speed through the modeling process.
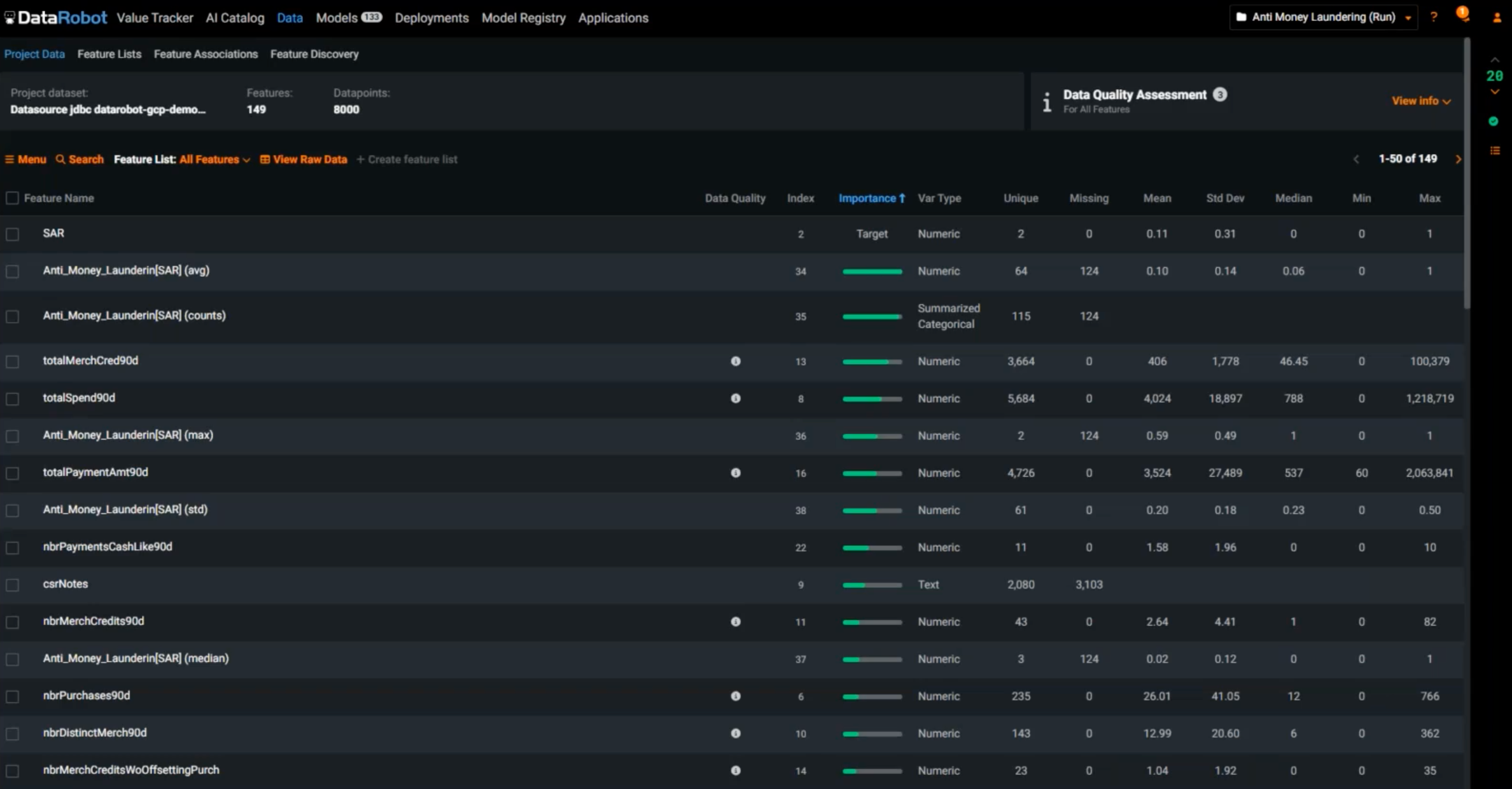
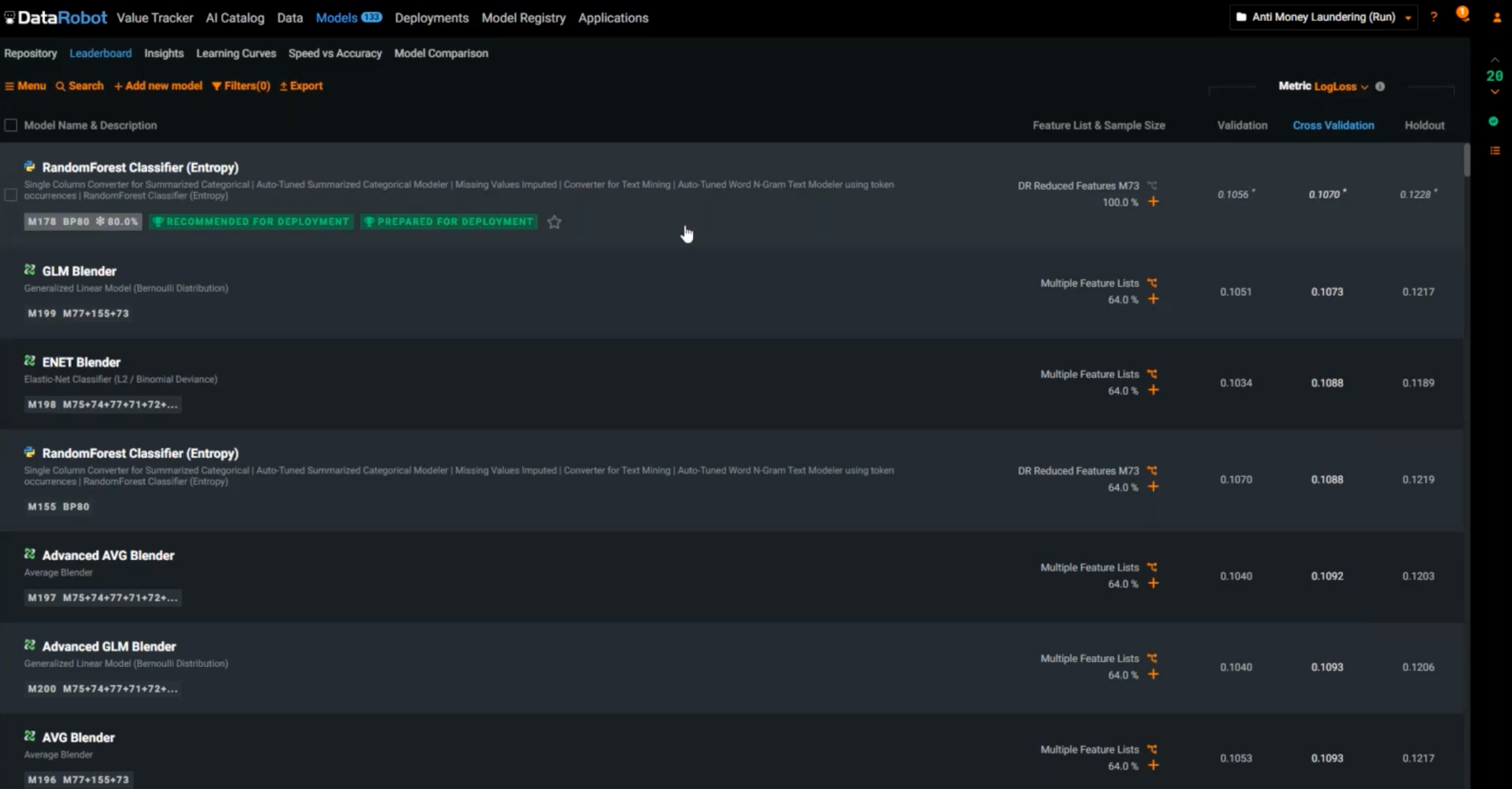
Once you click the Start button, DataRobot initializes the rapid experimentation process—experimenting with feature engineering and data enrichment stats. It’s going to start training hundreds of models, searching for the best model, the champion model that will give the best chance of success. At this stage, you are presented with new insights, including how important an input feature is to our target, ranked in order of importance.
You’ll also see new features that were not there in the original primary dataset. This means that DataRobot did find value in the secondary dataset and automatically generated new features across all our input data.
To be fully transparent in this tightly regulated industry, you can click in and look at feature lineage. It will take you all the way back to where each feature was pulled from and what transformations were done. For any new feature, you can look at the lineage and explain how this feature was generated.
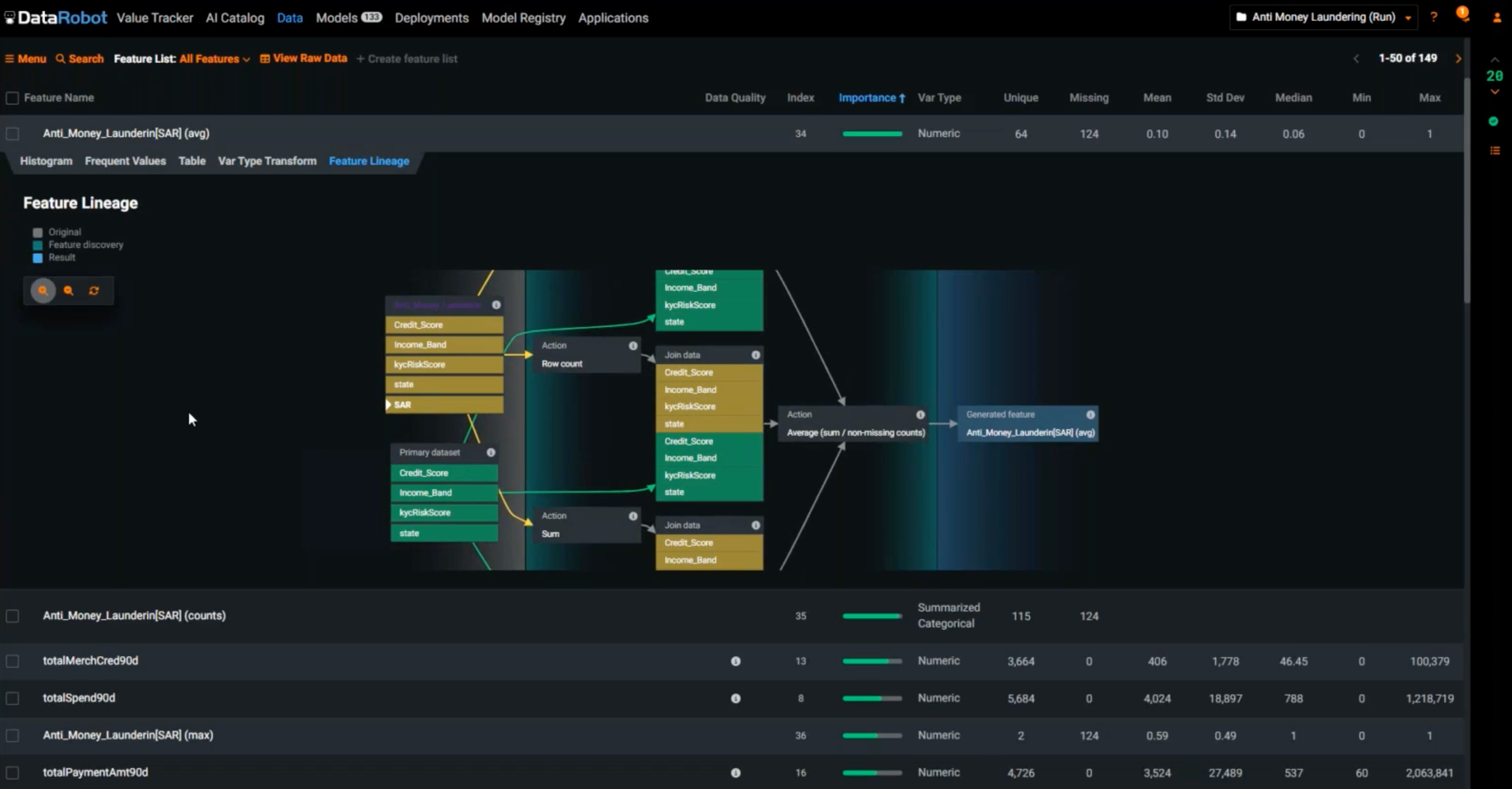
Speed
We’ve gotten the champion model quickly, but we need to check the quality and the transparency of the model. By drilling down into it, we can see what algorithms and techniques were used. It also shows all the steps that were taken along the way. You can further fine-tune the parameters you want and compare it with the original model.
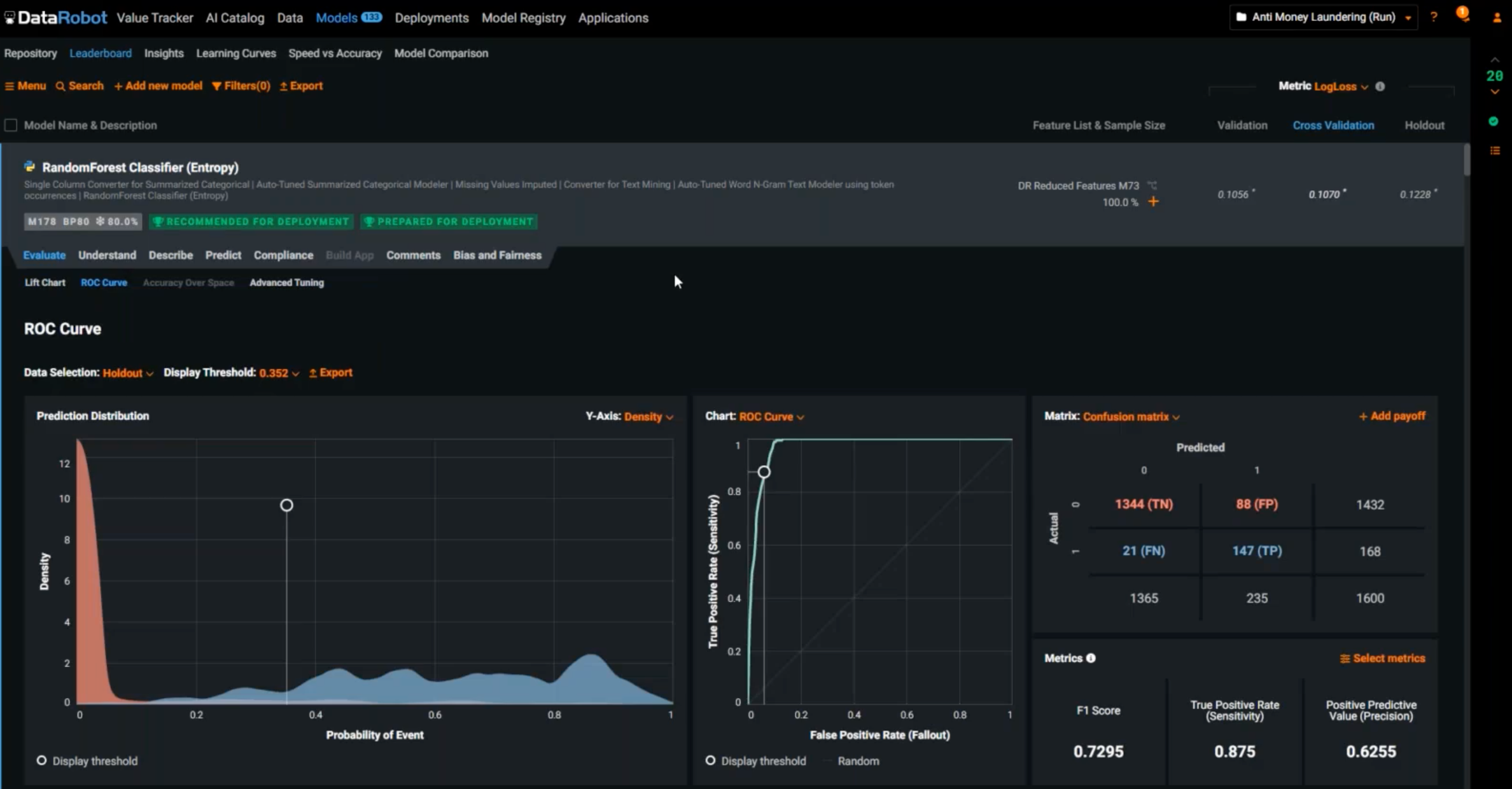
Evaluate the quality
How good or bad is this model at actually predicting an outcome? You can click on Evaluate to look at the ROC curve or the lift chart. This is the point where you decide what the threshold is for suspicious activity. Don’t just think of it from the data science point of view. Remember what the model is going to be used for within the context of the business, so keep in mind the cost and benefit of each outcome to the business. As you interactively test for different thresholds, the numbers for the confusion matrix change in real time, and you can ask the business about the cost they assign to a false positive to help determine the optimal threshold.
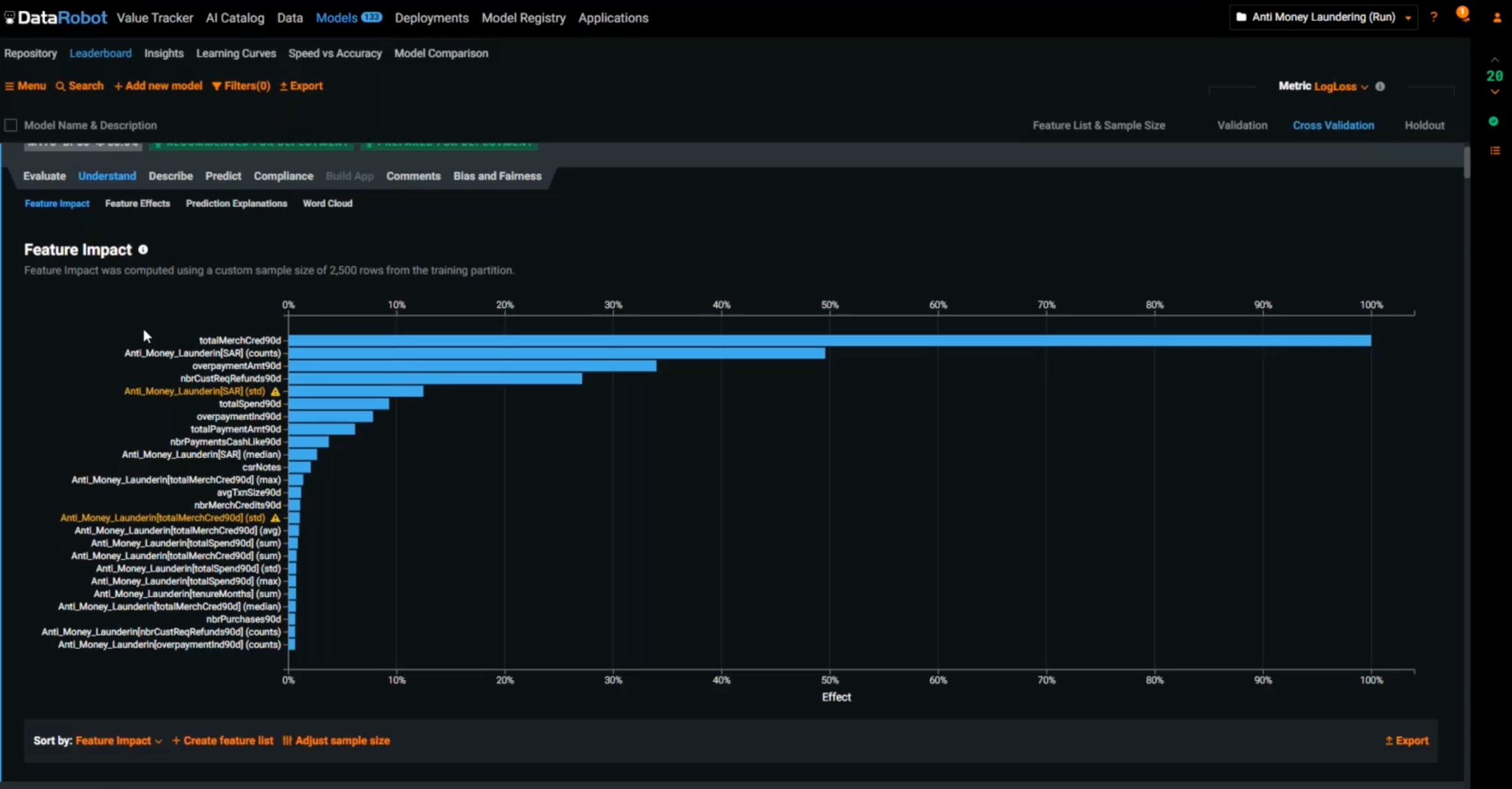
Transparency
As noted, in a highly regulated industry, transparency is of paramount importance. Click the Understand button. Feature Impact can tell you which features have the greatest impact on model’s accuracy and what is really driving behavior. Maybe you use this information to understand customer behavior and improve your KYC score (Know Your Customer score). Maybe you use it for process improvement, such as asking customers the right questions when they’re opening an account.
You can also explore how a model’s input can change the output. Go to Feature Effects where you can check how a model’s output changes when one particular parameter is changed. This enables you to look at a model’s blind spot.
Explainability. So far, you can see the effects of one feature, but in real life, your model is going to be driven by multiple features at the same time. If you want to understand why one prediction was made, you can see all the variables that affected the prediction as a combination. How much did each of these variables contribute to the outcome?
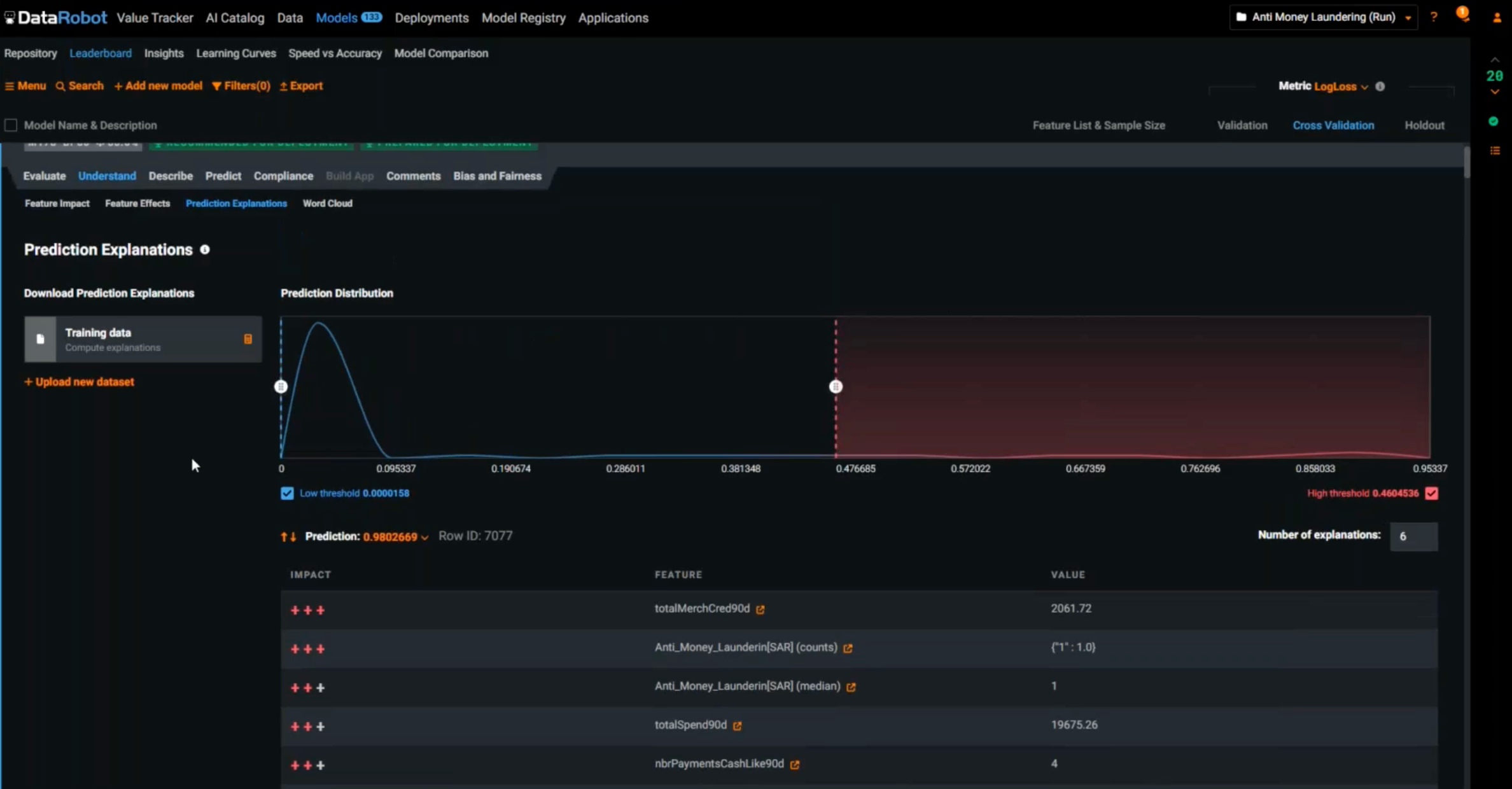
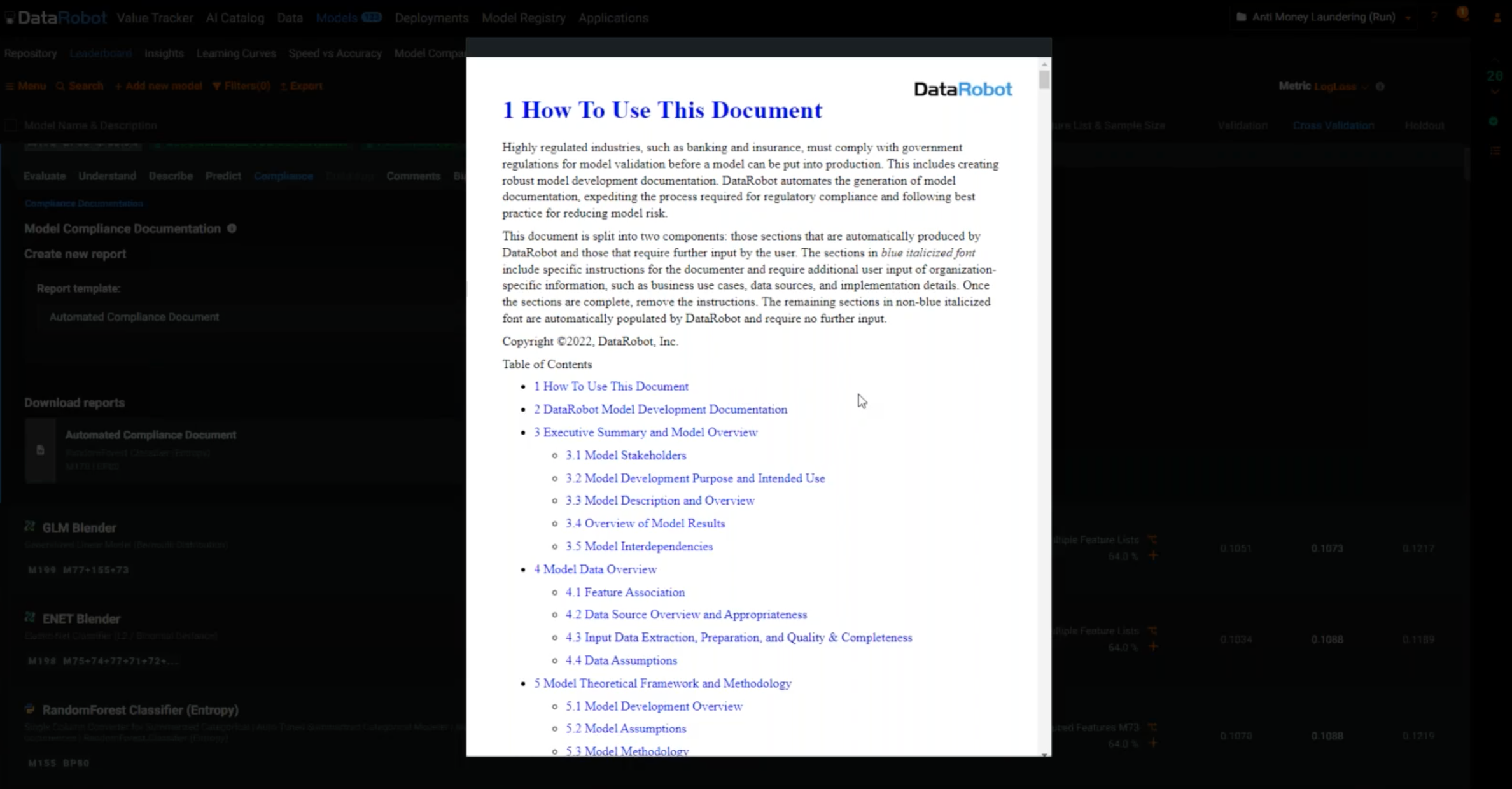
Because this is a use case for a regulated industry, you need to document all of this for your compliance team. Under the Compliance tab, with the click of a button, it will automatically generate a 60-page compliance report that captures all of the assumptions, the feature engineering steps, the secondary tables, and everything that was done to get to the final model.
It’s a simple Word document that saves you hours and hours of compliance work if you are a data scientist in a regulated industry.
Predict tab. There are a lot of options to deploy the model. With one click, I can deploy it to a predictions server and then it will be added to the MLOps dashboard, which you can see under the Deployments tab.
No matter how good your model was when you trained it, it’s going to degrade over time. Data and external factors are going to change. Businesses change. You will want to monitor your model over time. At the top, I can see how all my deployed models are doing in terms of data drift, accuracy and even service health. Have risk factors changed? How are my models holding up in the long run?
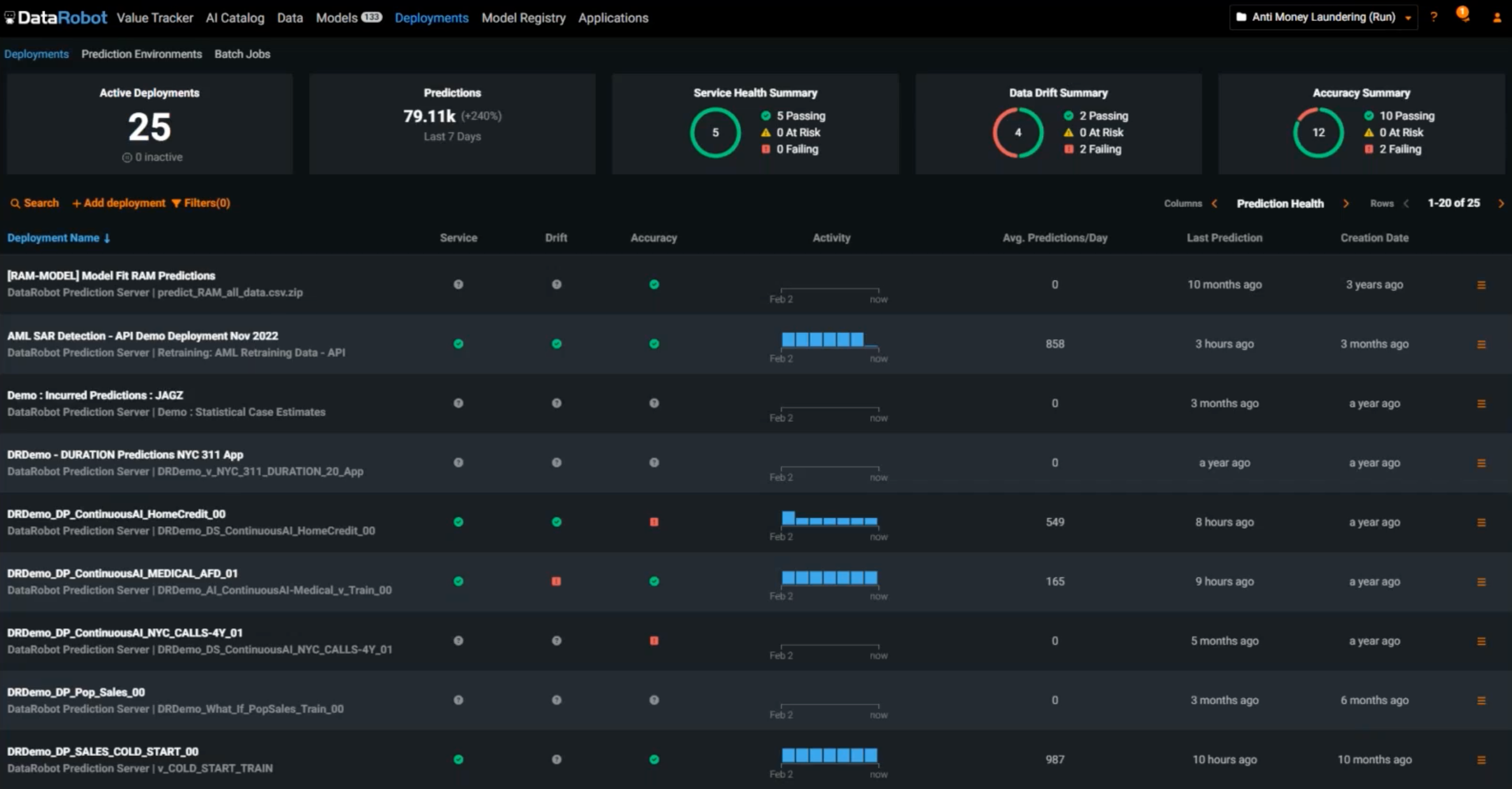
I can also see where these models were deployed. Models can be built and hosted elsewhere, but they can still be managed and tracked in this dashboard. DataRobot is a central location to govern and manage any and all models, not just models created in DataRobot.
DataRobot Brings You Speed, Quality, and Transparency Automatically
To stay ahead of money laundering, financial institutions need the features that DataRobot brings to the table:
- Automated Feature Engineering takes care of tedious, manual processes.
- Rapid Experimentation allows you to fine tune models and make additional enhancements.
- The user-friendly interface allows you to solve problems quickly and find blind spots.
- Data Quality Assessment helps you understand how healthy your data is, a key metric in highly regulated industries.
- The Interactive Model Threshold allows you to set the right thresholds for your business. It checks for false positives and negatives and shows what the effect on the business is, thereby ensuring the quality of the model.
- Automated monitoring and retraining allows you to maintain the quality of your model.
- Feature lineage, explainability, and automated compliance documentation is mandatory for transparency in financial services industries, and DataRobot does that automatically.

May Masoud is a data scientist, AI advocate, and thought leader trained in classical Statistics and modern Machine Learning. At DataRobot she designs market strategy for the DataRobot AI Platform, helping global organizations derive measurable return on AI investments while maintaining enterprise governance and ethics.
May developed her technical foundation through degrees in Statistics and Economics, followed by a Master of Business Analytics from the Schulich School of Business. This cocktail of technical and business expertise has shaped May as an AI practitioner and a thought leader. May delivers Ethical AI and Democratizing AI keynotes and workshops for business and academic communities.
-
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read -
6 Reasons Why Generative AI Initiatives Fail and How to Overcome Them
February 8, 2024· 9 min read
Latest posts
