信頼構築に必要な要素
人工知能(AI)はテクノロジーとして成熟しつつあります。現実の AI は SF のイメージとはまったく異なり、理論数学と高度なハードウェアが支配する排他的な世界から、日常生活へと活用の場が広がりました。ここ数年間で開発と普及が飛躍的に加速し、成熟した AI システムに対するニーズや要件が明らかになってきました。
DataRobot では、AI 成熟度のベンチマークを信頼できる AI として定義しています。信頼は、精度のような AI システムの内部的特性でもなければ、公平性でもありません。AI システムで形成される人間と機械の関係が持つ特性の 1 つです。始めから信頼性を備えた AI システムなど存在しません。信頼は、AI ユーザーとシステムの間で築いていかなければならないものです。
AI に対する信頼構築において最も高いハードルは、「AI システムに命を預けるには何が必要か?」という質問に集約できます。
自動運転車両や医学と人工知能の大規模な統合などの変革的な AI テクノロジーを実用化する際に、最大の障壁になっているのが、AI システムに対する信頼の醸成です。AI への信頼の必要性を軽視することは、AI システムが日常的な金融および産業プロセスにすでに組み込まれ、社会経済の健全性とアルゴリズムに基づいた意思決定がますます複雑に絡み合っている状況による影響を軽視することでもあります。このような高いハードルをクリアしなければならないテクノロジーは、AI が初めてではありません。AI の責任ある利用への道筋は、航空、原子力、生物医学など実に多様な業界によって切り開かれてきました。説明責任、リスク、メリットに対するこれらの業界のアプローチから当社が学んだことは、信頼できる AI のためのフレームワークの基礎となっています。
業界のリーダーと政策立案者は、信頼でき、責任を負える AI の共通要件に関して合意に近づき始めました。Microsoft 社は、公平性、信頼性と安全性、プライバシーとセキュリティ、包括性、透明性、および説明責任を、IBM 社は、説明可能性、公平性、堅牢性、透明性、およびプライバシーを求めています。米国下院決議第 2231 号(英語)は、アルゴリズムの説明責任の要件を確立し、偏見と差別、リスク便益分析とインパクト評価、およびセキュリティとプライバシーの問題に対処しようとするものです。カナダ政府は、独自のアルゴリズムインパクト評価ツール(英語)を発表し、オンラインで公開しています。これらの提言には、独自の原則よりも共通する原則のほうがはるかに多く含まれています。DataRobot ではこのビジョンを共有し、AI の責任ある利用について実践的な情報を提供するため、AI の信頼性構築に必要な 13 の要素を定義しました。
現在の課題は、指針となる原則や大きな目標を実行に移し、AI システムの設計と利用に携わるすべての人が利用でき、再現性があり、達成可能なものにすることです。これは大変なことですが、決して克服できない障害ではありません。本書では、信頼できる AI の原則を示すものではなく、実務上の問題や考慮事項、およびそれらに対処するためのフレームワークやツールについて詳しく説明します。まず、AI の信頼性構築に必要な各要素からこの原則に迫り、その後の各セクションで詳細な説明を行います。
「信頼構築に必要な要素」とは
DataRobot では、AI システムの信頼性を大きく 3 つに分類しています。
- AI/機械学習モデルのパフォーマンスに対する信頼。
- AI システムの運用に対する信頼。
- ワークフローの倫理に対する信頼(AI システムの設計、AI システムからビジネスプロセスに情報を提供する方法)。
DataRobot は、これらのカテゴリーのそれぞれにおいて、そのカテゴリーをさらに具体的に定義するための一連の要素を特定しました。信頼は包括的な概念であるため、MLOps など AI の既存の機能やベストプラクティスで全部または一部対応している要素もあります。各要素を総合的に組み合わせると、利用者の信頼を獲得できる 1 つのシステムが出来上がります。
ユーザーが異なれば AI システムに対する信頼の意味も異なってくるという現実を認めることが大切です。消費者向けのアプリケーションの場合、その AI アプリケーションを開発して所有する業務部門での信頼要件は、おそらく個人所有の家庭用デバイスでそのアプリケーションを操作する消費者にとっての信頼要件とは大きく異なります。どちらも、AI システムを信頼できることを知っておく必要がありますが、信頼の判断基準として何が必要で何を利用できるかは立場によってまったく異なります。
信頼の判断基準とは、対象の AI システムの品質を各要素に基づいて評価するために見つけ出せる指標を指します。と言っても、信頼の判断基準は AI 固有のものではありません。人と人とのつながりを評価するときにも使われるものです。新しいビジネスパートナーと出会うときに、どのような基準を意識的に用いて信頼性を判断しているか考えてみてください。もちろん人によって異なりますが、特に、自分が話しているときに相手がどれくらい注意を払っているかを示すしるしとして、アイコンタクトが重要であることに異論はないでしょう。固い握手を重視する人もいれば、時間厳守が絶対という人もいます。その人にとって、1 分の遅刻は思いやりや敬意のなさの証拠になります。思慮深い言葉は、自分が相手の話に耳を傾けていることを伝える強力な方法です。次に、もう少し複雑にして、新しく知り合った人と友達になれるかどうかを評価する際の信頼の判断基準が、ビジネスパートナーになる場合とどのように異なるかを考えてみてください。いくらか重複する部分はありますが、相手に求めるのは共通の目標や動機というよりも、関心事の共有やユーモアのセンスが似ていることになるはずです。では、新しい担当医には何を求めますか。患者に対する接し方に加えて、病院内に飾られた証書をチェックしたり、ネットでクリニックを検索して評価、レビュー、患者の口コミを調べたりするかもしれません。
これは AI システムとどう関係しているでしょうか。用途にもよりますが、AI システムも上記の人間関係のいずれかと似ていると考えられます。パーソナルバンキングに組み込まれた AI は、ビジネスアドバイザー並みに信頼できるものでなければなりません。テレビのストリーミングサービス向け提案アルゴリズムが動作する AI システムには、好きなジャンルが一緒で、あなたの好みを知っている友達のような信頼感が必要です。また、診断アルゴリズムには、あなたがその分野の専門医に求めるような資格と基準を満たし、あなたの質問、疑問、心配を何でも受け付け、隠し立てしない資質が要求されます。
AI システムからは、アイコンタクトや病院内に飾られた証書のような信頼の判断基準は得られませんが、同じニーズを満たしています。固有の指標、可視化、認証、そしてツールを活用すれば、システムを評価し、それが信頼できることを実証できます。
続くセクションでは、パフォーマンス、運用、および倫理のカテゴリーごとに、AI の信頼性構築に必要な各要素を取り上げます。
AI のパフォーマンス
パフォーマンスは、「このモデルは、データに基づく予測をどの程度正確にできるか?」という問いと関係しています。信頼できる AI を実現するために、パフォーマンス面で重視している要素は以下のとおりです。
- データの品質 – AI システムで使用されるデータの出所や品質を検証するために、特にどのような推奨事項や評価内容を使用できるでしょうか?データのギャップや食い違いを特定して、より信頼性の高いモデルを構築するにはどうすればよいでしょうか?
- 精度 – 機械学習では、どのような方法で「精度」を測定しますか?モデルのパフォーマンスを明確にして伝達するには、どのような信頼の「合図」(ツールや可視化)が適切でしょうか?
- 堅牢性と安定性 – データの変化や混乱に直面したときにも、モデルの動作が一貫していて予測可能であることを保証するには、どうすればよいでしょうか?
- スピード – 機械学習モデルのスピードは、モデルの選択基準や AI システムの設計にどの程度反映されるべきでしょうか?
AI の運用
運用は、「このモデルがデプロイされるシステムはどの程度信頼できるか?」という問いと関係しています。AI の運用面においては、モデルだけでなく、ソフトウェアインフラストラクチャやモデルにかかわる人々にまで視野を広げ、以下のことに重点的に取り組みます。
- コンプライアンス – AI に関して規制遵守が求められている業界では、AI システムの検証と検定を最も効果的に推進し、意図通りの価値を企業にもたらすにはどうすればよいでしょうか?
- セキュリティ – AI システムでは膨大な量のデータが分析されたり、送信されたりします。AI を構築して運用する際に、どのようなインフラストラクチャとベストプラクティスを用いれば、データとモデルのセキュリティを維持できますか?
- 謙虚さ – AI システムの予測は、どのような条件のときに不確かになる可能性がありますか?システムは不確かな予測にどう対応すればよいでしょうか?
- ガバナンスと監視 – AI におけるガバナンスとは、人間と機械の対話を管理する正式なインフラストラクチャです。AI システムの管理で開示や説明責任などの原則に対応するには、どうすればよいでしょうか?また、モデルを継続的に監視する責任は誰にありますか?
- ビジネスルール – AI システムを大切なチームメンバーとして、ビジネスプロセスにシームレスに組み込むにはどうすればよいでしょうか?
AI の倫理
倫理は、「このモデルは、自分の価値観とどの程度一致しているか?このモデルは、実際に社会にどのような影響を与えるか?」という問いと関係しています。倫理には本来、複雑さと主観性が伴うものですが、AI における倫理には、具体的で体系的なアプローチが有効です。AI の倫理面については、以下の要素を取り上げます。
- プライバシー – 個人のプライバシーは基本的な権利ですが、データの利用と交換によって複雑にもなっています。機密データの管理において、AI はどのような役割を果たすのでしょうか?
- バイアスと公平性 – AI システムをどのように利用すれば、公平かつ公正な意思決定を促進できるでしょうか?また、どのようなツールを使えば、AI システムに反映させたい価値観を明確にできるでしょうか?
- 説明可能性と透明性 – この 2 つの特性をどのように組み合わせば、機械と人間の意思決定者の間で共通の理解を生み出せるでしょうか?
- インパクト – 機械学習によってユースケースに付加される実際の価値をどのように評価すればよいのでしょうか?そうした評価はなぜ有用あるいは必要ですか?また、組織、および組織による意思決定の影響を受ける個人にどのようなインパクトがありますか?
AI を慎重かつ責任を持って利用するには、技術モデル、モデルを収容するインフラストラクチャ、およびモデルのユースケースのコンテキストを包括的に理解する必要があります。これまでに示した信頼構築のための要素は、単なるチェックリストではなく、極めて重要な指標です。DataRobot は、これらの要素に基づいて AI プロジェクトを注意深く評価すれば、想定外の影響を受けることなく、意図した効果を達成できる可能性が大幅に高まると考えています。当社は、すべてのユーザーが AI システムへの信頼を確立する面で最善の支援ができるように、DataRobot プラットフォームの機能と設計にこのフレームワークを反映させています。それだけにとどまらず、当社は DataRobot プラットフォームに依存しない推奨事項と共にこの情報を公開しました。AI への信頼と理解のために利用できるツールを見つけることは、AI のすべての開発者、運用者、利用者にとって極めて重要だからです。
DataRobot – 信頼できる AI プラットフォーム
DataRobot のエンタープライズ AI プラットフォームは、エンドツーエンドのモデリングライフサイクルをサポートし、AI および機械学習システムの開発、デプロイ、監視の全ステップを促進する機能を備えています。AI の責任ある利用に関して、DataRobot は「AI システムに命を預けるには何が必要か?」という質問に答えるべく努力しています。DataRobot の「信頼できる AI」チームは、機能とツールをプラットフォームおよびモデリングワークフローに組み込むことに専心しています。その目標は、信頼できて頼りになり、責任を負える倫理的な AI を利用しやすくし、標準化することです。
モデル開発でガードレール機能を自動適用
ターゲットリーケージの検出 – 予測の時点ではモデルで利用できないはずの情報が特徴量から分かってしまう、ターゲットリーケージを自動的に検出します。DataRobot では、モデリングに推奨される「リーケージ除去」特徴量セットが自動的に生成されます。
堅牢なテストおよび検定のスキーマ – 自動的に推奨されるだけでなくカスタマイズも可能な k 分割交差検定およびホールドアウト、時間外検定、バックテストパーティショニングスキームをリーダーボード上の競合モデルすべてに実装し、同じ条件で比較することで、モデルのパフォーマンスを安定的に評価します。リーダーボード全体で、外部のテストセットに基づいてパフォーマンスをランク付けすることもできます。
説明可能な AI – 特徴量のインパクト、特徴量ごとの作用、行レベルの予測の説明などのインサイトを使用して、モデルの動作を理解し、検証します。
バイアスと公平性
適切な公平性指標の定義 – 特定のユースケースにおいて何が公平であるかを定義する方法を決めることは、互換性のない指標がある場合は特に複雑になる可能性があります。DataRobot では、一連の質問に回答することで、サポートされている 8 つの指標のうちどれがユースケースに最も適切かを判断できます。
バイアスの自動的な検出と測定 – DataRobot では任意のモデルに対し、定義済みの指標を使って、モデル内にある定義された保護クラス(人種、年齢、性別など)全体にわたって計算されたバイアステストの結果を自動的に表示します。
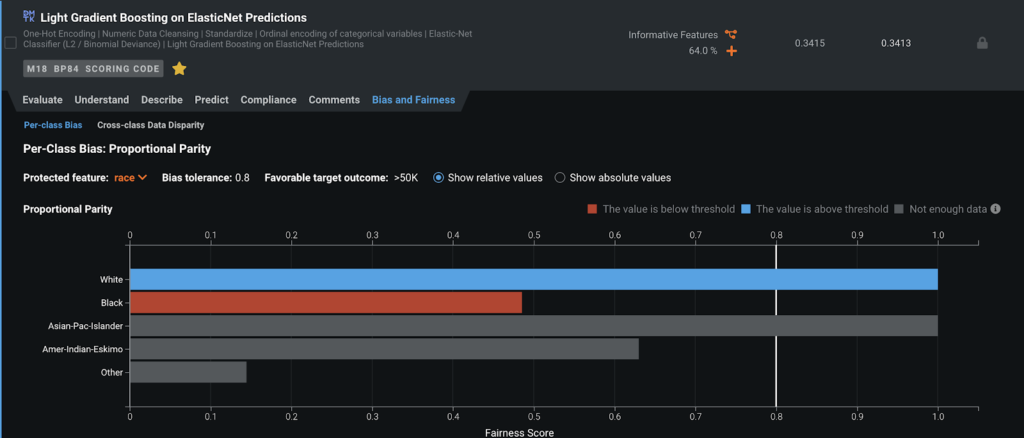
バイアスの原因の調査 – クラス間の相違ツールを使用すると、保護クラスごとに特徴量の基本的な分布を詳細に調査して、データがどの程度観察されたバイアスの原因になっているかを特定できます。
バイアスと精度のトレードオフの調整 – バイアス対精度のグラフは、リーダーボードを 2 次元のグラフに置き換えたもので、選択したバイアス指標を新しい横軸として使用します。このグラフを見て、パフォーマンスとバイアスの可能性の両方を同時に考慮しながら、デプロイするモデルを選択できます。
コンプライアンスの確保
コンプライアンス文書の自動作成 – DataRobot は、適切に書式設定されたコンプライアンス文書を自動的に出力します。データとモデリングの手法を高い透明性で詳述し、リフトチャートや特徴量のインパクトなどの UI 可視化ツールを取り入れることで、規制当局がモデルの設計と運用について明確に理解できるようにしています。コンプライアンス文書をカスタマイズして、ユースケースに応じて適切なテンプレートにすることもできます。
承認ワークフローおよびユーザーベースの権限設定 – AI および機械学習モデルの開発とデプロイでは、ユーザーベースの権限設定でガバナンスを維持します。
謙虚さを取り入れた予測
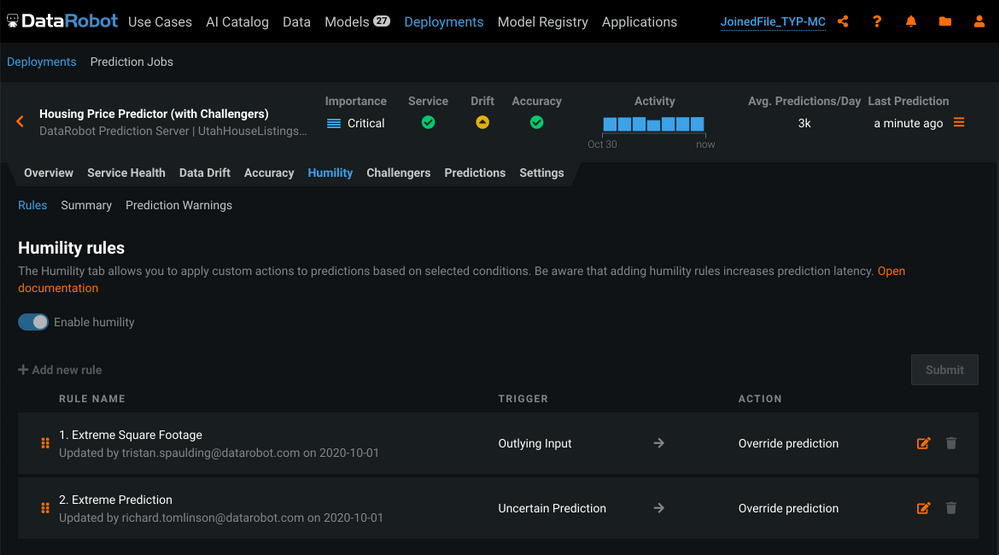
モデルの予測が不確かである状況の特定 – 確実性のレベルは、すべての予測で同じとは限りません。Humble AI(予測の信頼性)では、新しいスコアリングデータとモデルの予測結果に一定の特徴があることをリアルタイムで検出し、予測が不確かである可能性が高いことを示すフラグを設定できます。
ビジネスプロセスを保護する自動アクションのトリガールールの作成 – Humble AI(予測の信頼性)を使用してトリガー条件を特定することで、予測をオーバーライドしたり、エラーを返したりといった自動アクションに条件を関連付けるルールを確立できます。