

Forecast Daily Demand by Store
Overview
Business Problem
Having the right products in the right place at the right time has been one of the most challenging aspects of retail. If a store has too much inventory on hand, oftentimes it needs to be deeply discounted in order to sell it, resulting in lower profit margins, or possibly selling that merchandise at a loss. And, if these are perishable goods, there are additional costs associated with their disposal. Purchasing more inventory than needed is a poor use of working capital; however, if the store doesn’t have enough inventory, there may be lost sales as well as customer frustration. Current solutions to try and solve this problem often involve using spreadsheets or classical statistical methods such as ARIMA models. These solutions are limited to aggregated levels such as by department or category. In addition, these methods fail to capture the nuances in the data such as holidays, special events, and sales resulting in over stocks and out of stocks.
Intelligent Solution
Through automation, advanced machine learning, and deep learning algorithms, AI can solve out of stock and overstock issues by forecasting, at scale, the demand required for products. Machine learning models can create forecasts for up to 1 million series in each project. In some circumstances, different products will have vastly different sales history, seasonality, and trends. It can be a challenge to predict future sales for products that have very distinct sales patterns using a single model. To overcome this challenge, automated machine learning can automatically perform unsupervised clustering to find like-groups of products, and model each cluster separately (e.g., by store, region, category, correlation, etc.).
Value Estimation
What has ROI looked like for this use case?
ROI will depend on forecasting level (store, category, SKU, etc.), the size of the business, accuracy of current forecasts, and rate of inventory turnover, among other things.
A 9.5% improvement in demand forecast accuracy increased profit by an estimated $400 million per year for a global fashion retailer.
Technical Implementation
About the Data
For illustrative purposes, this tutorial uses a synthetic dataset that resembles a retailer’s historical sales from 10 separate stores, located in different regions around the United States.
Problem Framing
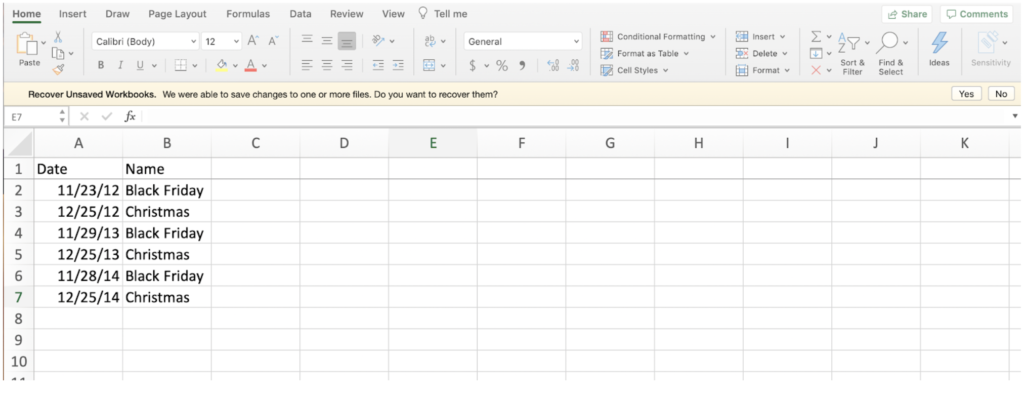
To perform demand forecasting for the 10 stores, we will need to make sure the data is in the proper format. The required format is what is known as the “long” format, where stores’ data is stacked on top of each other, as seen in the picture below.
Our target will be Sales, the date column will be Date, and our series id will be “Store.”
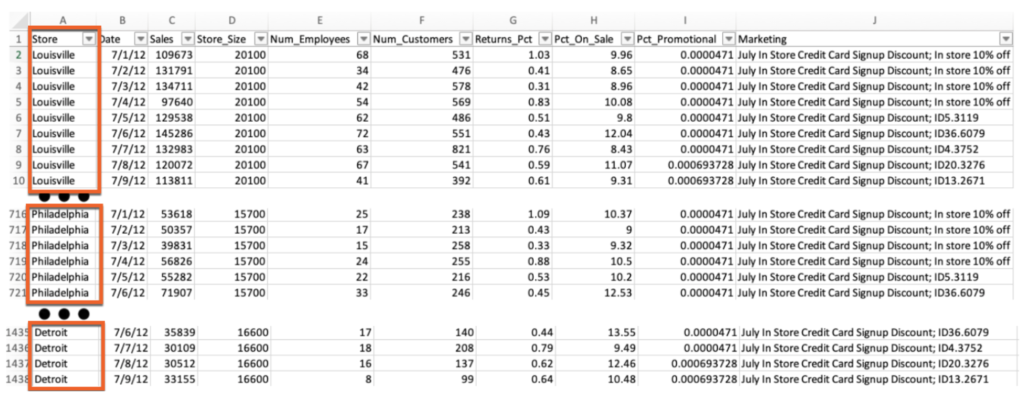
The feature list in this dataset contains information from several different areas of the business such as Marketing, Finance, Infrastructure, HR, IT, and Point of Sale/Accounting. This information will be joined and put into a tabular format so we have all the necessary information about store characteristics, marketing promotions, store staffing, customer foot traffic, sales, etc., which will be used in the modeling process.
Sample Feature List
| Feature Name | Data Type | Description | Data Source | Example |
|---|---|---|---|---|
| Store | Categorical | Name of the Store | Infrastructure | Louisville |
| Date | Date stamp | Date sales occurred | POS | 01 July 2012 |
| Sales | Float | Daily Sales (Target) | POS | 20801.16 |
| Store_Size | Int | Store size in square feet | Infrastructure | 20100 |
| Num_Employees | Int | Number of Employees that worked that day | HR | 72 |
| Num_Customers | Int | Number of customers that came in store that day | IT | 612 |
| Returns_Pct | Float | Percent of items returned to what was sold | POS | 0.80 |
| Pct_On_Sale | Float | Percent of items on sale in the store | Marketing | 0.50 |
| Pct_Promontional | Float | Percent of items with active promotions | Marketing | 0.0003 |
| Marketing | Text | Marketing campaign information | Marketing | 10% off accessories |
| TouristEvent | Binary | Indicator for whether or not there is a local event near the store, eg Sports event/Concert, etc | HR | No |
| Econ_Change_GDP | Float | Change in Gross Domestic Product for the locality the store is in | Finance | 0.5 |
| EconJobsChange | Float | Change in jobs for the location the store is in | Finance | 700 |
| AnnualizedCPI | Float | Consumer Price Index | Finance | 0.02 |
Data Preparation
To create the dataset that will be used for modeling, we need to join the required tables from marketing, sales, infrastructure, and others. In the event that products are sold out, you need to be able to record or estimate what the “likely” demand was, and then fill in the target values with those “likely demand” values; otherwise, the models will start to learn to forecast those days where sales were 0, because the item was sold out.
When all of the data is in one place, we need to “stack” the stores on top of each other in a long format like in the image above. Once the data is correctly structured we can write it to a table or view, log in to DataRobot, and set up a connection to that table or view to pull in the data automatically.
Once the dataset is prepared, if you have series with different seasonalities you should implement clustering as part of the data preprocessing phase. This will put similar series in the same project, thereby improving accuracy by forecasting similar items together. Also, if you have a large dataset this helps by breaking it up into smaller ones.
Model Training
DataRobot automates many parts of the modeling pipeline, so for the sake of this tutorial we will be more focused on the specific use case rather than the generic parts of the modeling process. Feel free to refer to this DataRobot documentation on our modeling process if you’d like to learn more about the methodologies behind its automation. Here, we highlight the specific configurations you need to apply in DataRobot to train the demand forecasting model.
For this use case we are going to model daily Sales for each store. To do this we are going to upload the dataset, which in this case is a CSV file. Once the dataset is uploaded, we are going to select our target, Sales. Then we are going to select Set up time-aware modeling and select Date as our Date/Time feature.
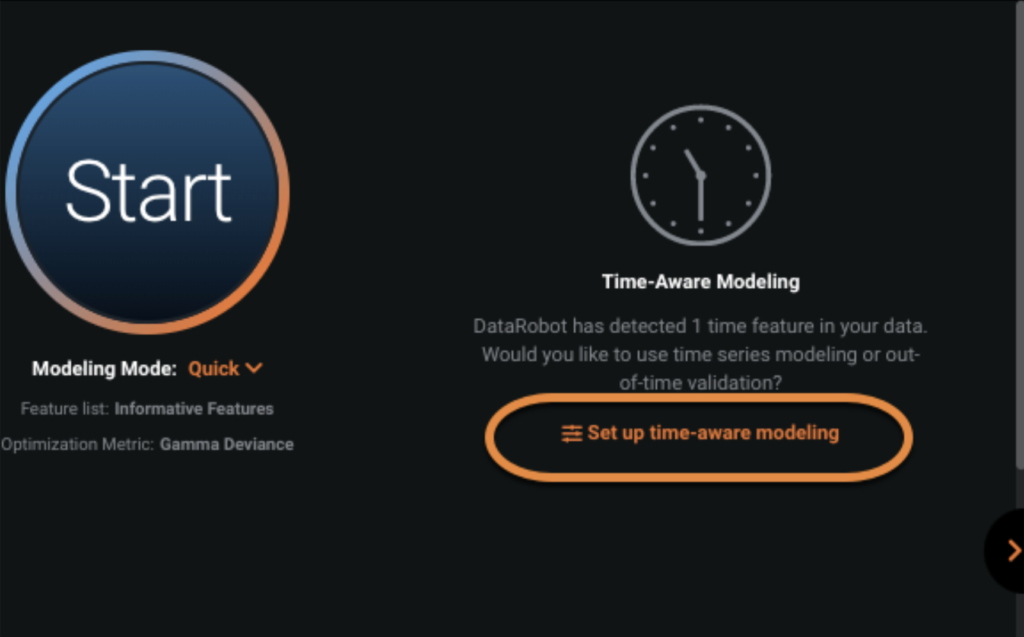
Next, we select Time Series Modeling. Within Show Advanced Options, we set the Series ID, which in this case is Store.

For this use case we are forecasting Sales for the next seven days. So we will leave the Forecast Distance at 1 to 7 Days. The Feature Derivation Window, or rolling window, is the amount of time we want to use to create rolling features and lags, such as Sales 7 days ago, 28 day mean of Sales, etc. We will leave this at the default of 35.
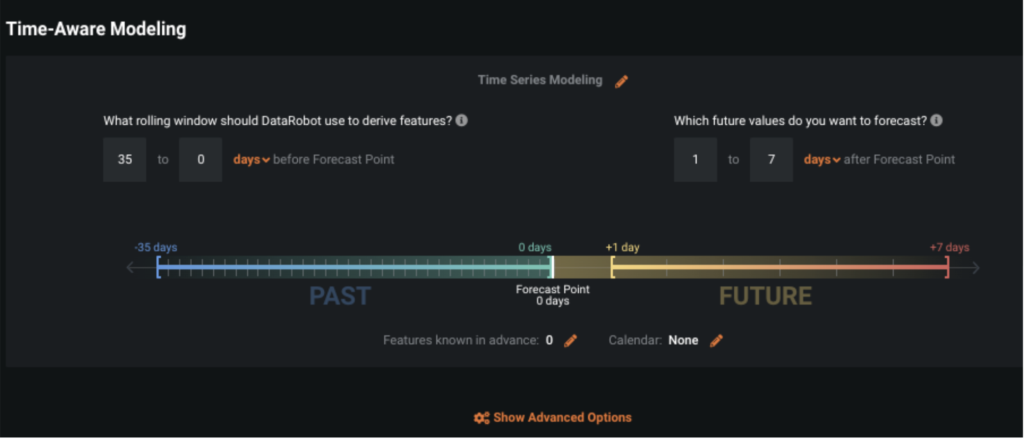
Next we will identify features that we know in advance: since we are forecasting seven days, any features that we will know in the next seven days we include to be flagged as “known in advance.” These features are: Store_Size, Marketing, and TouristEvent.
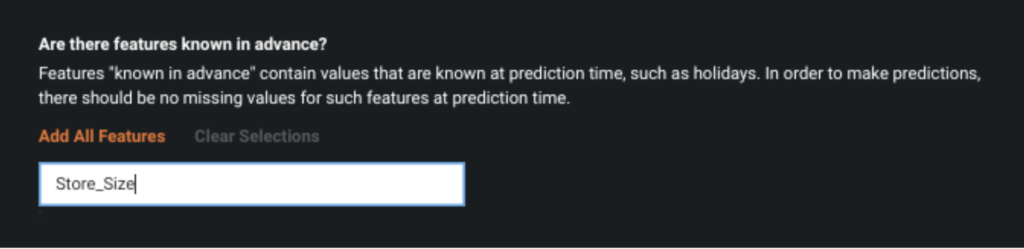
After we identify the known in advance features, we need to add in our events calendar. Our calendar file contains the date and name of each event. This calendar file will be used in the creation of the forward-looking features. Along with traditional feature engineering, where we create lags of the input variables, we will also create forward-looking features to more accurately capture special events.
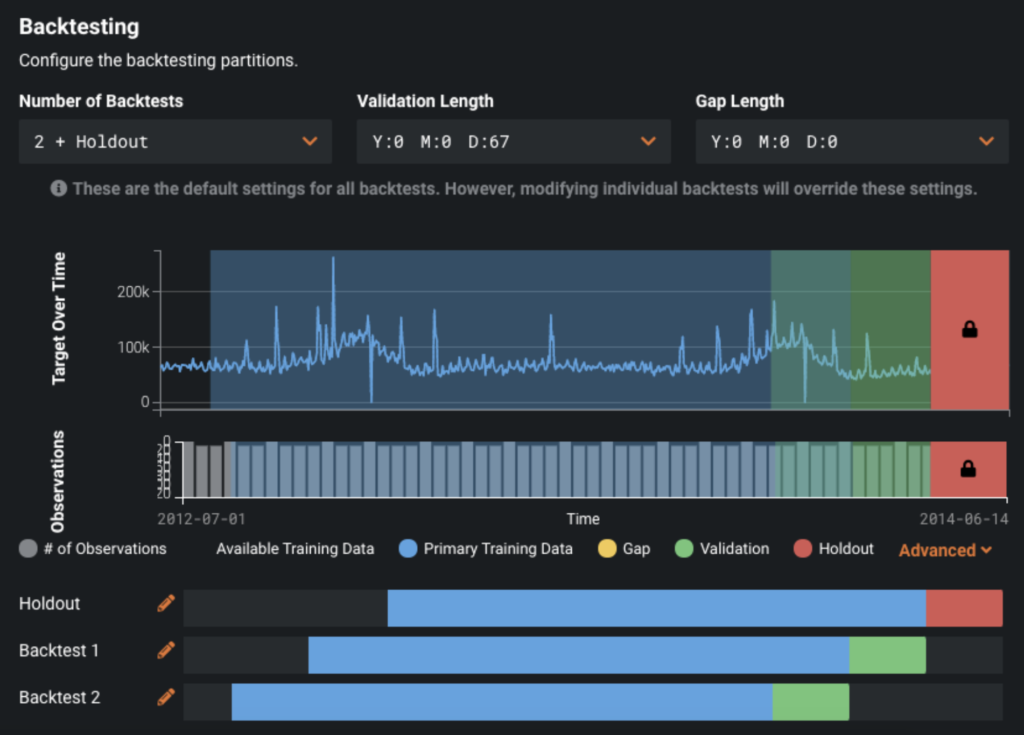
One other setting we might need to adjust is the backtesting. This is where the model trains on historical data and validates on recent data, and DataRobot does this multiple times to ensure we have a stable model. You can adjust the validation periods and number of backtests to suit your needs. If you have a period of interest such as the winter holiday shopping season, you can specify your holdout period to be this exact period so the model will be optimized specifically for this time region. In the default backtesting setup below, you can see Backtest 2 starts about halfway into the holiday shopping season.
If you want a model that is optimized for this, we can modify the backtests. You can adjust the Holdout period to be November 15th to January 1st as shown in the image below.
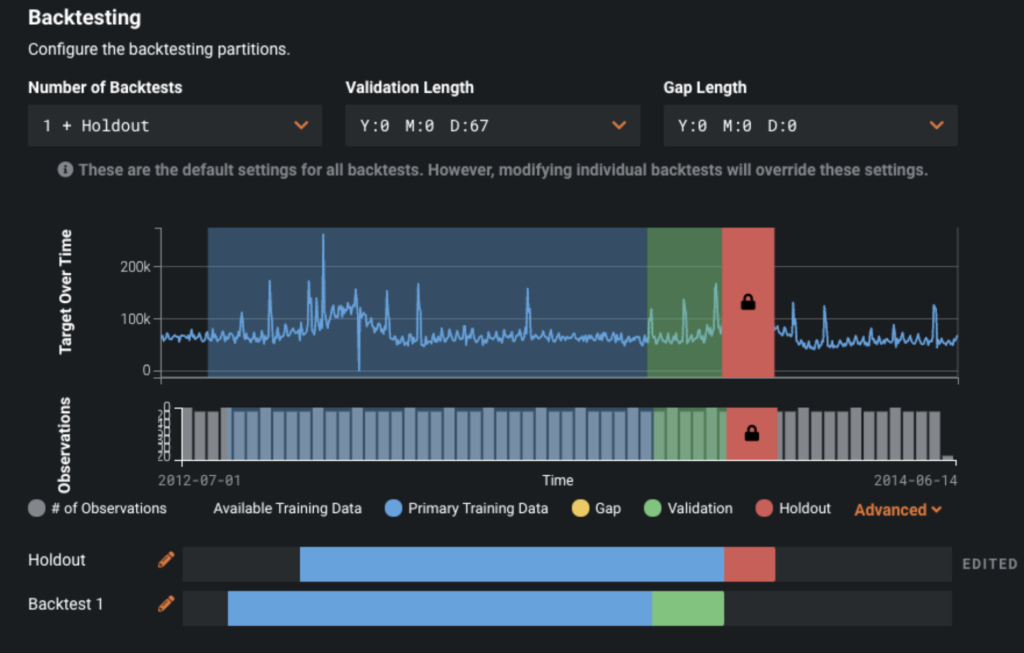
Once you complete adjusting your backtests, you can click the Start button to create your models.
Interpret Results
This shows the Feature Impact of the original features. Here, we can see the relative impact of each feature on the specific model.
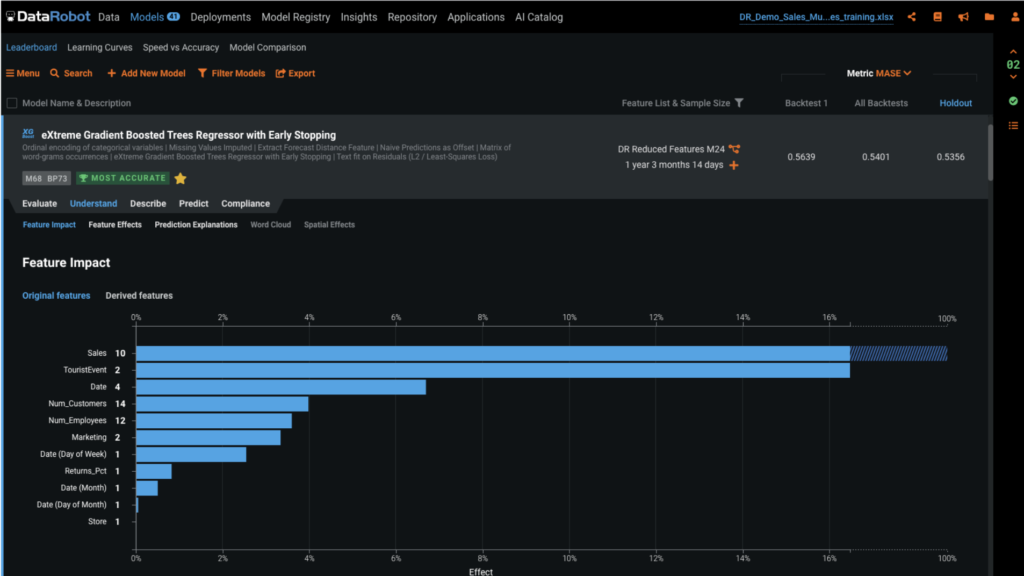
Here we can see the feature importance of all of the derived features DataRobot generated. Notice Sales (7 day average baseline) is a lag based on historical data and is the most important feature. This is followed by TouristEvent (actual) which is an indicator for that day, or a present time indicator. The third most important feature is Date (calendar event type) (actual), which is one of our forward-looking features that tells the model when important calendar events are coming up, such as Black Friday, and other sales events. These are the historical, present, and forward-looking features (respectively) that we discussed earlier.
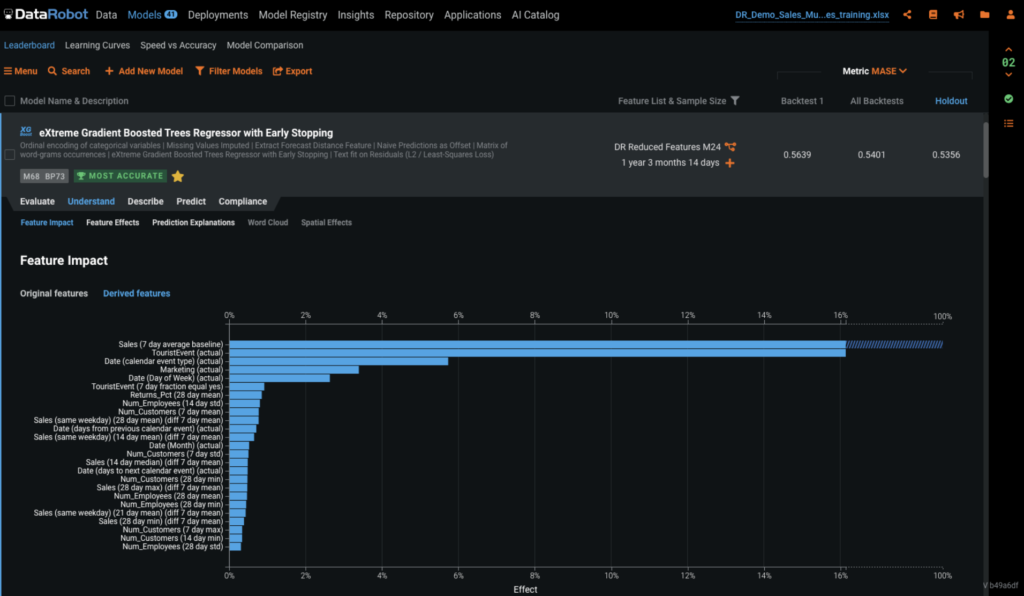
In addition to viewing feature importance on the macro level, DataRobot also gives prediction explanations on the micro level where it provides the top statistical driver behind each prediction. Below, you can see that Savannah is predicted to perform well, primarily because there will be a tourist event.
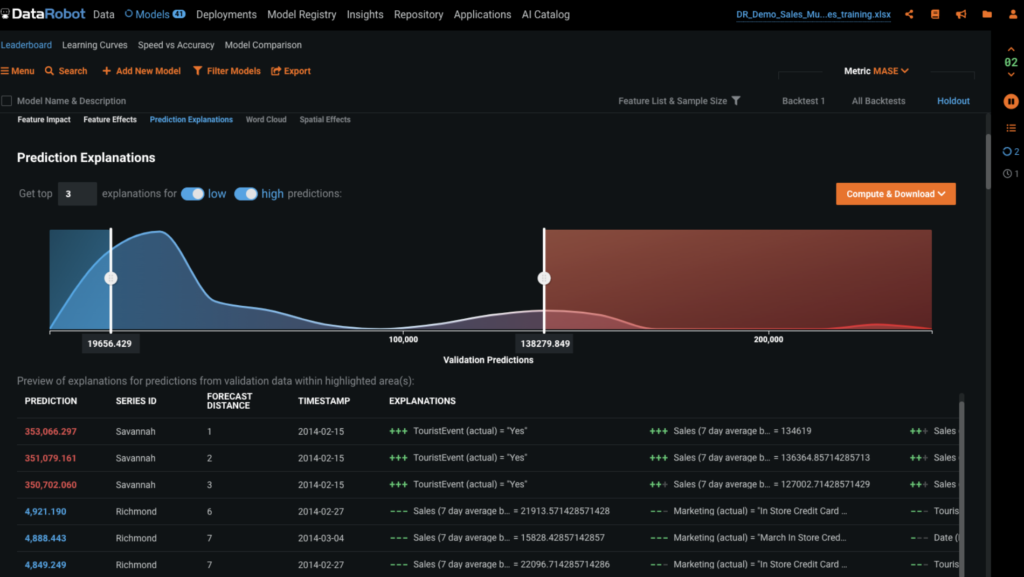
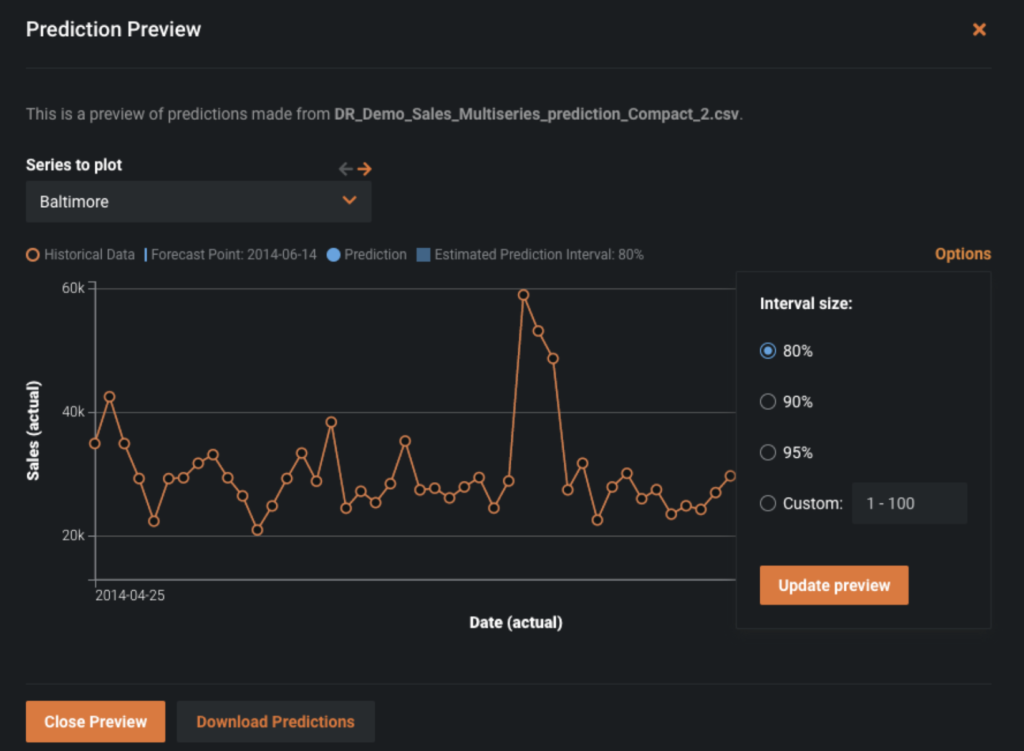
When generating forecasts we have the ability to adjust the prediction intervals. As we can see in the figure below, we can add on prediction intervals to the prediction output; this will allow us to set the upper and lower bounds to better suit our business problem.
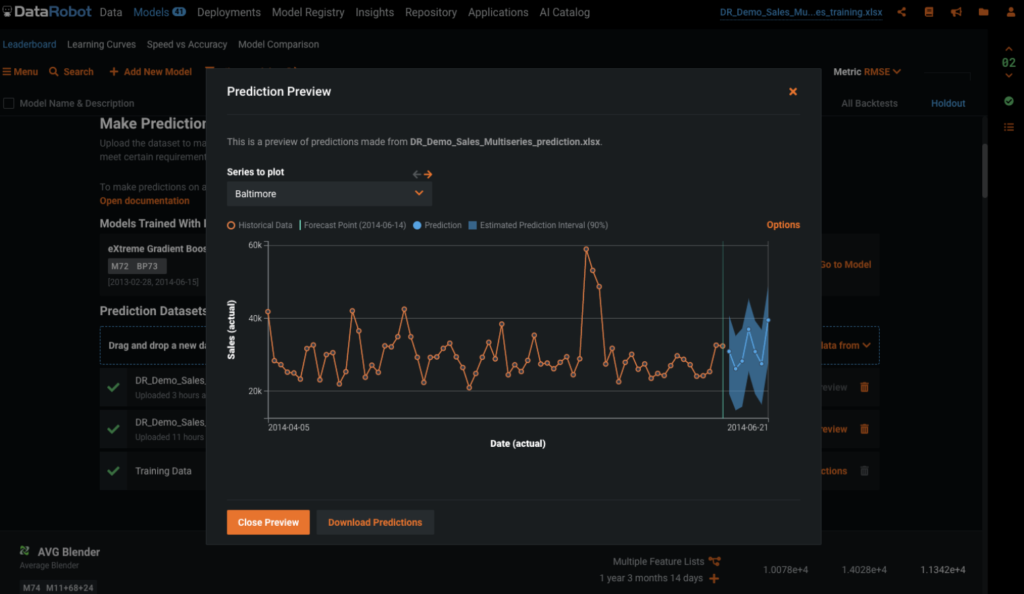
Being able to adjust and even set customized prediction intervals enables you to have control over the upper and lower bounds in the forecasts. Prediction intervals are extremely useful in situations where you want to ensure that you have enough product, but not too much (i.e., overstock). To ensure you have enough stock on hand, you can use the upper bound of the prediction interval instead of the prediction.
Evaluate Accuracy
Once the modeling process is complete, we can go to the Models tab and examine the Leaderboard. The results are sorted in order of the Metric by All Backtests. DataRobot will sort by the optimization that was chosen automatically (or if you set it manually before hitting Start).
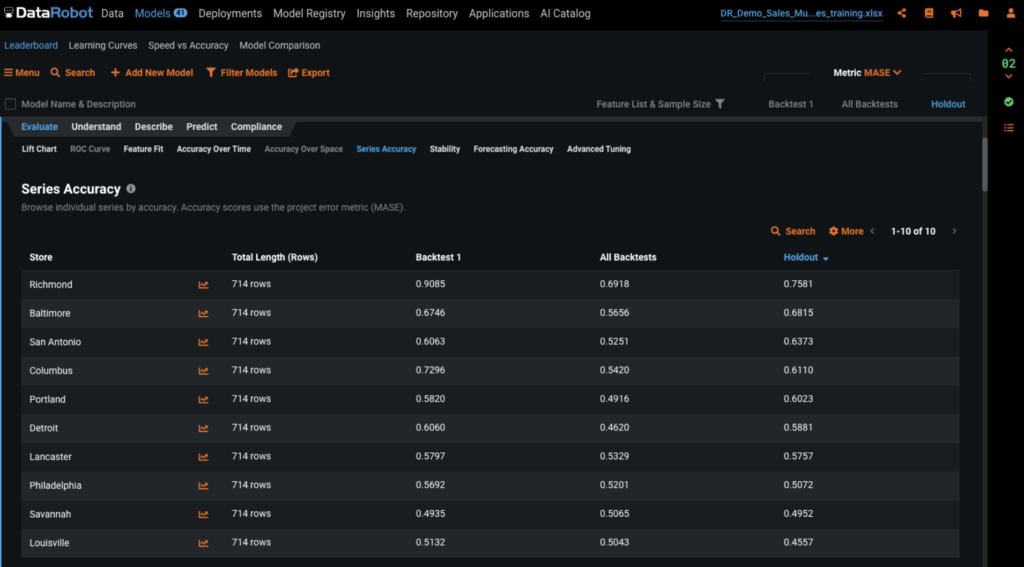
We can change the metric from RMSE, in this case, to one of many others. Because RMSE is scale variant, it can be difficult to evaluate the accuracy of different series that have different scales, such as stores that have $500,000 in daily sales vs those stores with $10,000 in daily sales. To overcome this difference in scale, we can use the MASE metric which is scale invariant. MASE compares the model accuracy against the baseline model, or naive model. With MASE, the lower the score the better the model; and the higher the score the closer to the naive model, the worse the model is.
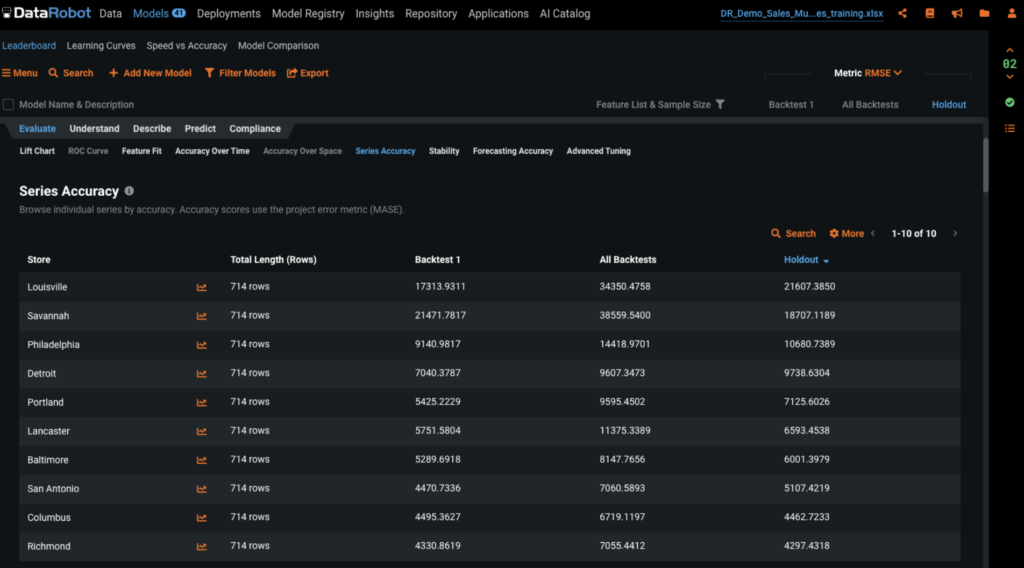
The Series Accuracy tab provides the accuracy of each series based on the metric we choose which is MASE in our image. This is a good way to quickly evaluate the accuracy of each individual series.
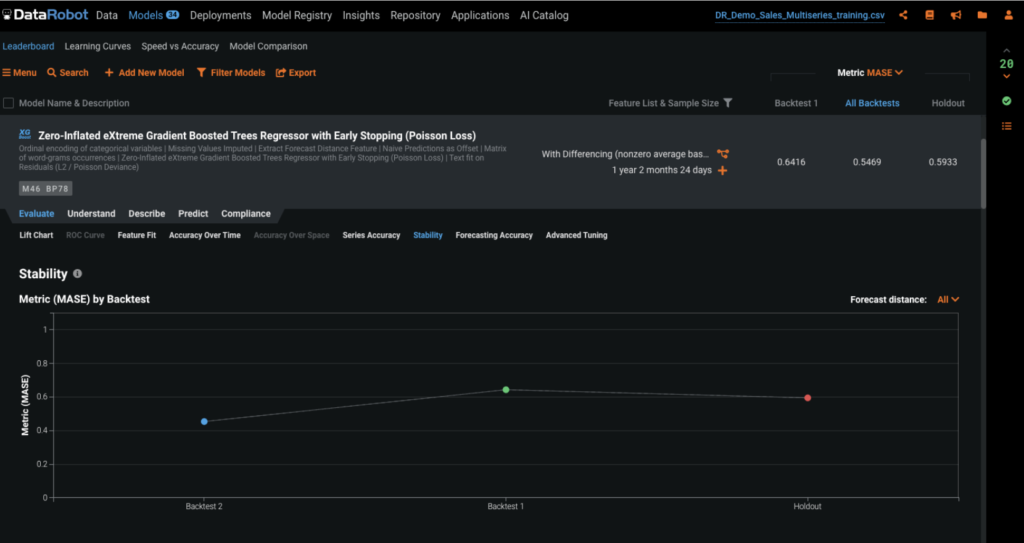
The Stability tab provides a summary of how well a model performs on different backtests to determine if it is consistent across time.
The Forecast Accuracy tab explains how accurate the model is for each forecast distance, enabling you to evaluate model accuracy as you forecast further out.
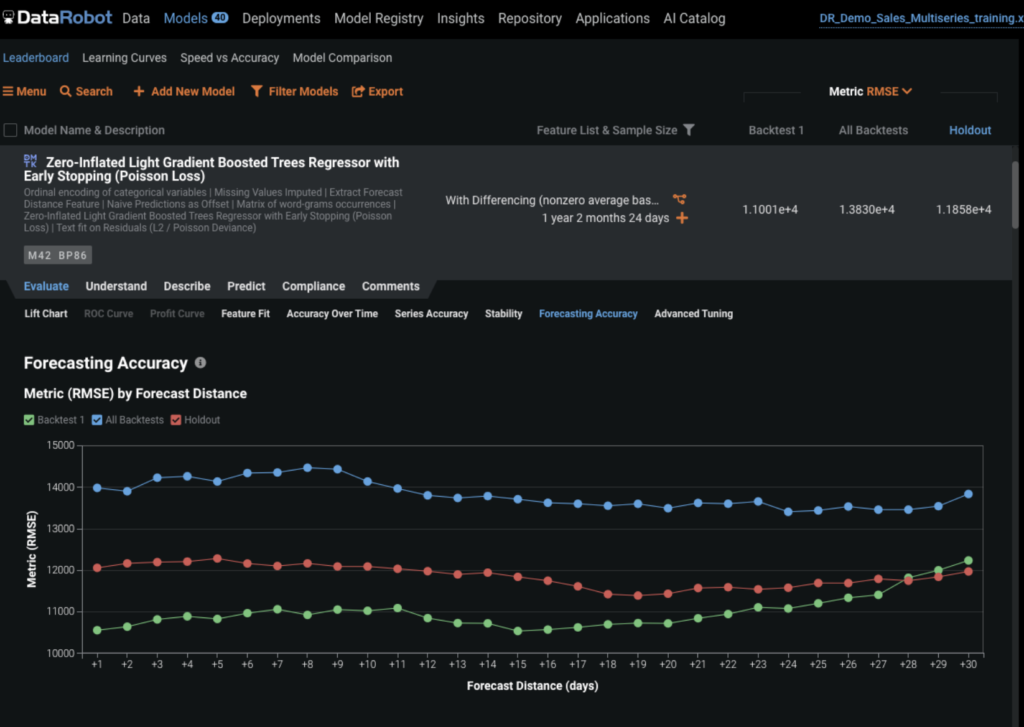
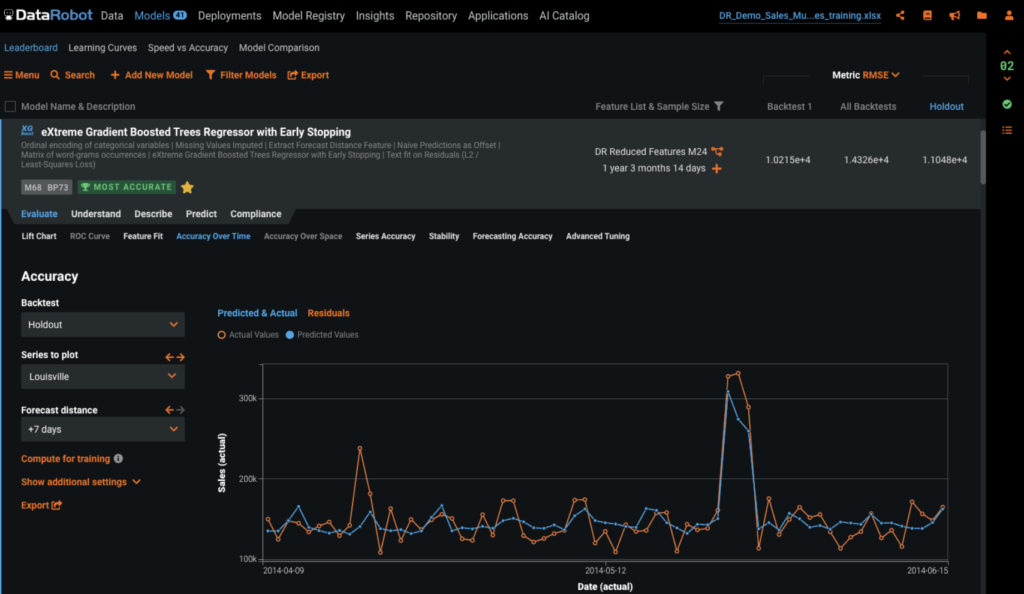
Below is the Accuracy Over Time tab, where we can see the actual and predicted values plotted over time. We can also change the backtest and forecast distances, so that we can evaluate the accuracy at different forecast distances across the validation periods.
Post-Processing
Post-processing steps that might be needed include rounding the prediction field that is output when running predictions. This field is a float but may need to be converted to an integer.
If your demand forecast is a range, there will be various forecast distances output in the prediction file as well. In this use case, we will have seven forecast distances: ranging from tomorrow to one week from now. How you use the forecast distances will depend on your specific use case.
Business Implementation
Decision Environment
After you finalize a model, DataRobot makes it easy to deploy the model into your desired decision environment. Decision environments are the methods by which predictions will ultimately be used for decision making.
Decision Maturity
Automation | Augmentation | Blend
In this use case, we will be utilizing DataRobot Automated Time Series (AutoTS) to do demand forecasting for each store. This solution is able to be fully automated, or augmented with a human in loop if desired.
Model Deployment
The majority of demand forecasting models are deployed and referenced via API. This makes it easy to generate the forecasts, then write the results to a table, or a similar structure in your current environment. Typically these results are written to a SQL table in a database that is already being referenced by logistics planning software and other BI tools; this way it is extremely easy to use these forecasts for logistics planning, as well as present them in BI tools that your organization is already using.
Decision Stakeholders
Decision Executors
Inventory planners, business analysts, and logistics analysts.
Decision Managers
Inventory, logistics, and finance managers
Decision Authors
Data scientists and analysts
Decision Process
These predictions will help inventory planners have a more accurate understanding of expected demand, giving them the ability to optimize inventory levels ahead of time.
Users responsible for managing inventory will also be able to output not only the forecasts, but also the Prediction Explanations and prediction intervals (for those forecasts). Prediction intervals are extremely useful for situations in which you want to ensure that you have enough product on hand, without suffering from overstock. To ensure you don’t run out of stock you can use the upper bound of the prediction interval.
Model Monitoring
Models can be monitored by MLOps for service health, and accuracy. This monitoring is extremely important to ensure your models are outputting accurate forecasts and to identify if early retraining is necessary. In the presence of black swan events, MLOps is crucial for identifying what series need to be retrained and how often to retrain.
Predictions for demand forecasting are typically made every week.
For time series models, a heuristic for how often to rebuild is to use the length of your validation period as the number of days between model rebuilds. If your validation period is 65 days, then you should rebuild your model(s) every 65 days.
Implementation Risks
From a business perspective, risk can vary from low to high when implementing demand forecasting. At an aggregate level, such as forecasting overall demand at the store level, the risk is relatively low. As you begin to forecast more granular, such as by category or sub-category, the risk can become moderate. When forecasting at SKU level, which is the most granular level, the risk is going to be high, because it is now on a much larger scale and there are more things that need to be taken into consideration.
To break down why the risk increases as we go more granular, consider the example of a retailer with 1,000 stores, 20 categories, 180 sub categories, and 50,000 SKUs. For a reference, citing Forbes, WalMart now sells approximately 70 Million SKUs. (How Much Of Wal-Mart’s Revenue Will Come From E-Commerce In 2020?)
Forecasting level
Store – 1,000 = 1,000 Series to forecast
Store & Category – 1,000 x 20 = 20,000 Series to forecast
Store & Sub-category – 1,000 x 180 = 180,000 Series to forecast
Store & SKU – 1,000 x 50,000 = 50,000,000 Series to forecast
As you see, when forecasts become more granular, the number of series to forecast grows exponentially. Through its automation, DataRobot can handle the use cases above from a technical perspective; however to successfully implement demand forecasting at the SKU level, proper change management should be in place and all stakeholders should be included on the project. In the end, it is critical for all stakeholders to approve and support the project. Forecasting demand at the store level can give you a noticeable ROI through proper staffing and capital management. As you begin to forecast more granularly the ROI increases, but so does the complexity and scope of the project.
From a technical perspective, implementing demand forecasting with DataRobot can range from low to high risk: the actual risk factor will be dependent upon how granular you will be forecasting. As we saw in the example above, creating demand forecasts for stores results in 1,000 series to forecast. As we move to SKU-level forecasting it could increase to 50,000,000 series to forecast. With this many series to forecast, the compute resources needed to generate the models—along with the storage needed to house the predictions—will be substantially more than the store level. It is important to keep in mind the compute and storage resources needed, their costs, and having a system in place to track SKUs and projects.

Experience the DataRobot AI Platform
Less Friction, More AI. Get Started Today With a Free 30-Day Trial.
Sign Up for Free
Explore More Use Cases
-
RetailPredict Customer Lifetime Value (CLV)
Understand the long-term value of your customers to make better-informed, short-term decisions on which customers to prioritize.
Learn More -
RetailVendor Invoice Fraud
Predict the likelihood that a vendor invoice is fraudulent.
Learn More -
RetailForecast Demand for Staffing in Retail / DC / Warehouse
Forecast the volume of inbound shipments required over the next month to allocate the right levels of staffing.
Learn More -
RetailPredict Performance of Sellers
Maximize the productivity of your sellers by predicting the performance of each seller throughout the determined selling period.
Learn More