

How to Tackle Imbalanced Data with DataRobot
This post was originally part of the DataRobot Community. Visit now to browse discussions and ask questions about the DataRobot AI Platform, data science, and more.
Even with imbalanced data, DataRobot can build a good model. In this article, we explain imbalanced data and share how to best attack imbalanced data with DataRobot.
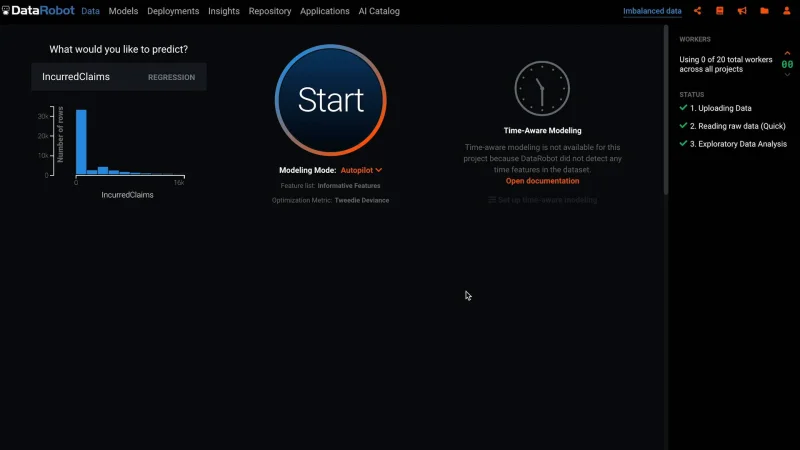
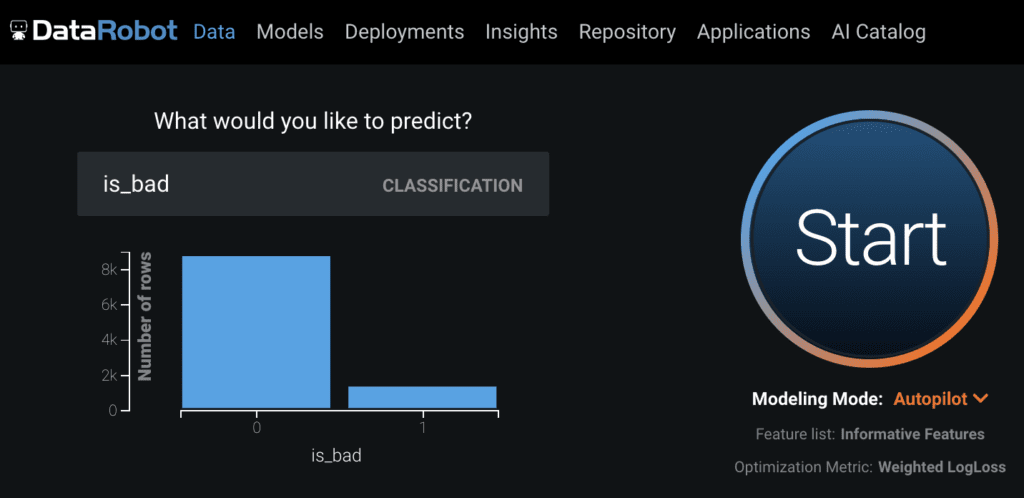
Imbalanced data occurs when there is an overrepresentation of a certain value inside the target variable. Imbalanced datasets for binary classification projects have an overrepresentation of the majority class compared to the minority class; for example, the target variable graph in Figure 1 shows the imbalance in is_bad. For regression projects, the imbalanced dataset tends to have an overrepresentation of zeros in the target variable as shown in the target variable graph for IncurredClaims (Figure 2). In these cases, when the minority class is significantly more important than the majority class, you need to take this imbalance into account when building models.
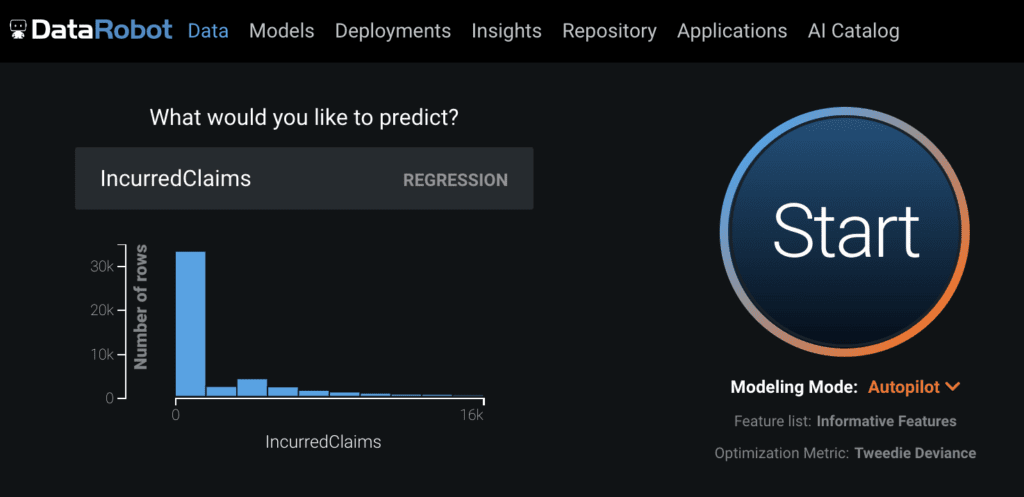
DataRobot automatically handles imbalanced data during its model building process by picking the best model optimization metric given the distribution of the values in the target variable.
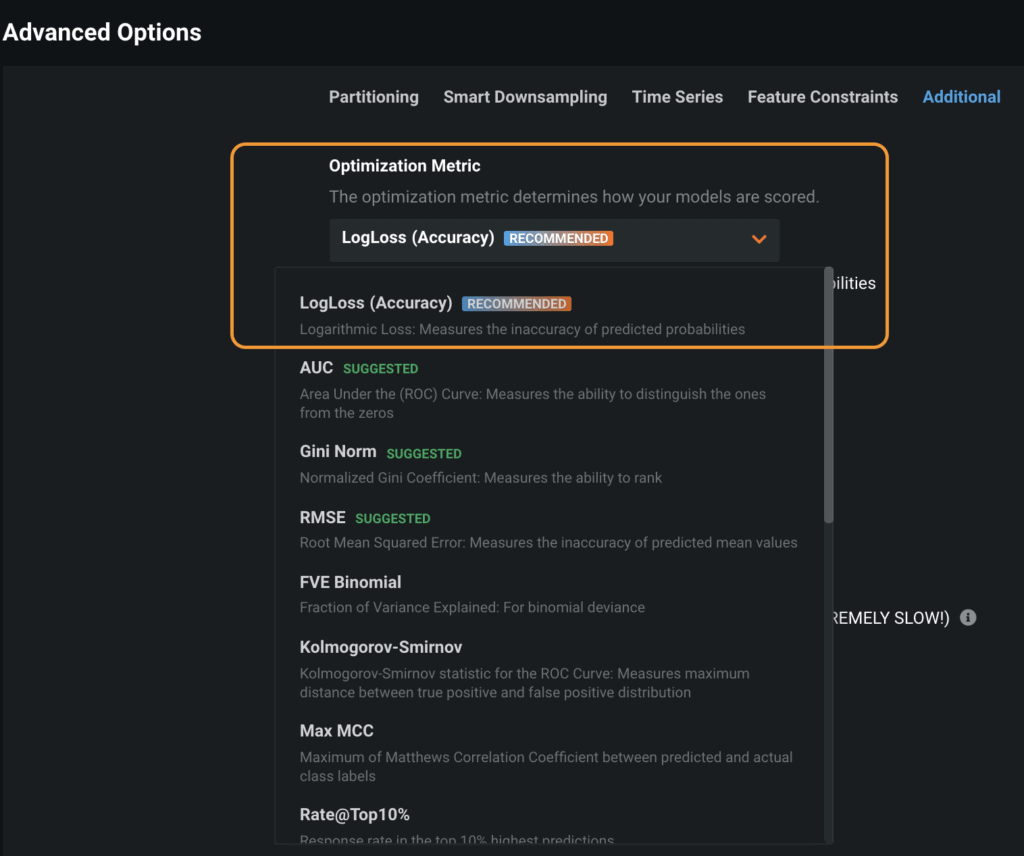
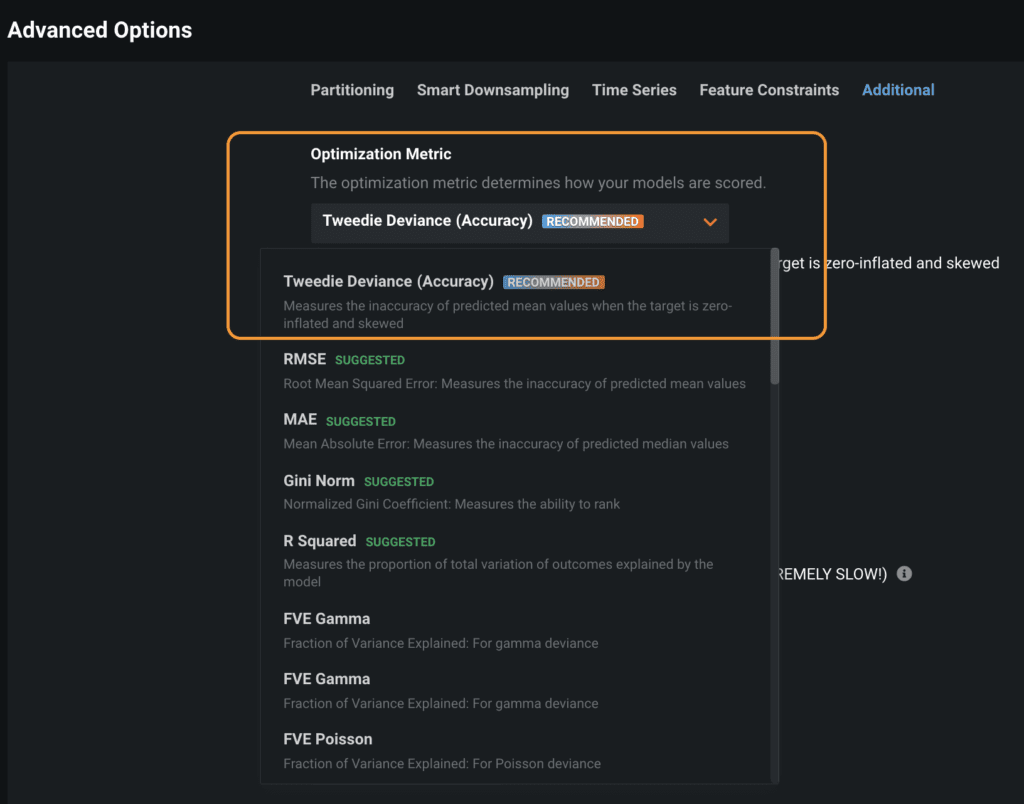
For imbalanced binary classification datasets, DataRobot uses the LogLoss metric which is known to be robust to imbalanced data (Figure 3). For zero-inflated regression datasets, DataRobot uses Tweedie Deviance (Figure 4).
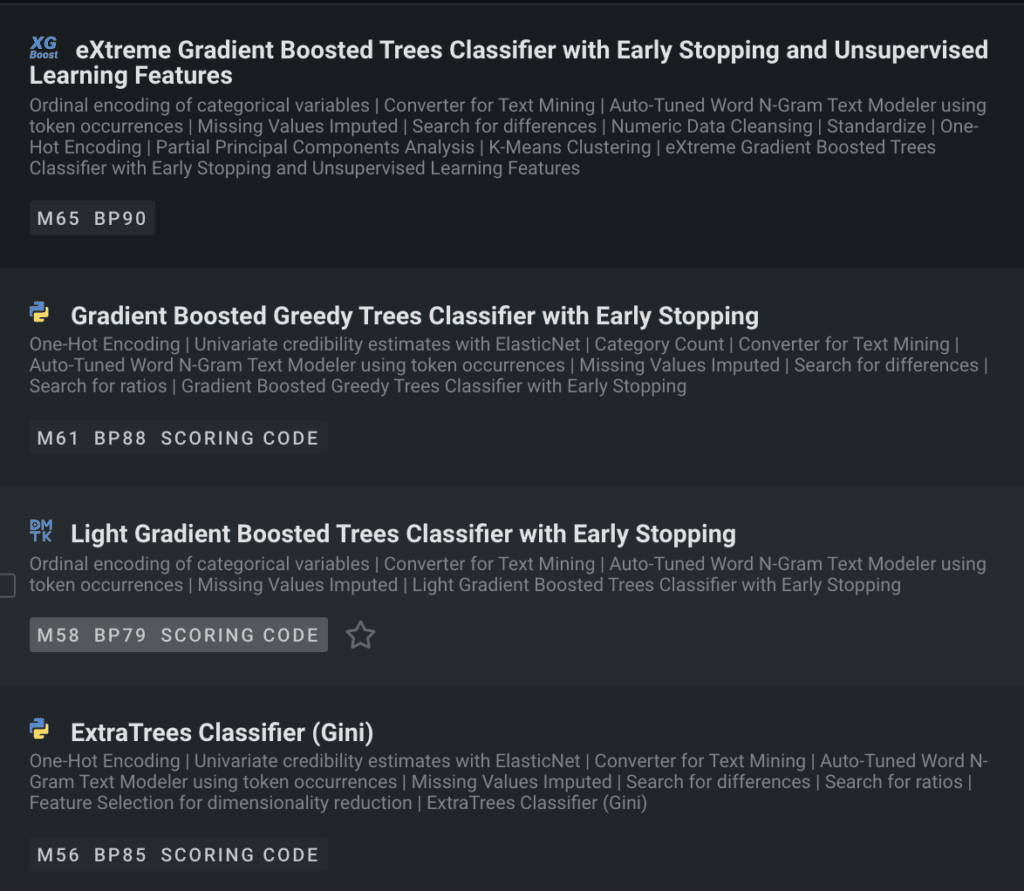
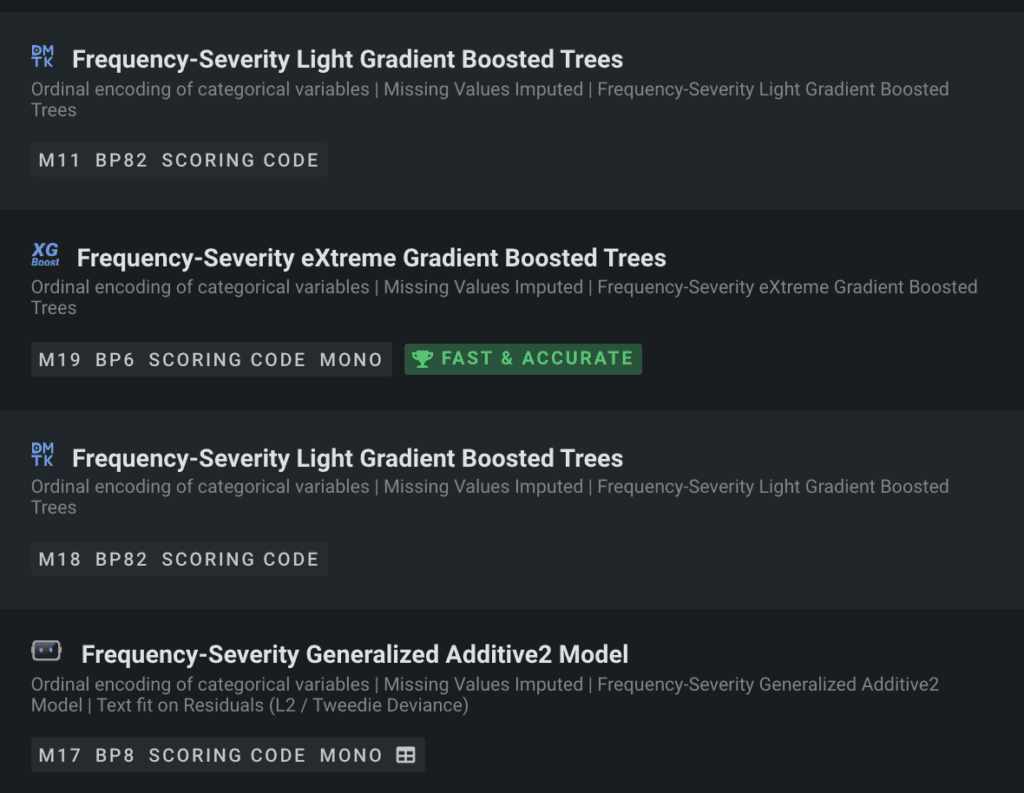
Additionally, DataRobot includes a variety of modeling algorithms which are robust to imbalanced data, such as the different kinds of Tree-based models (Figure 5) and the frequency-severity models (Figure 6).
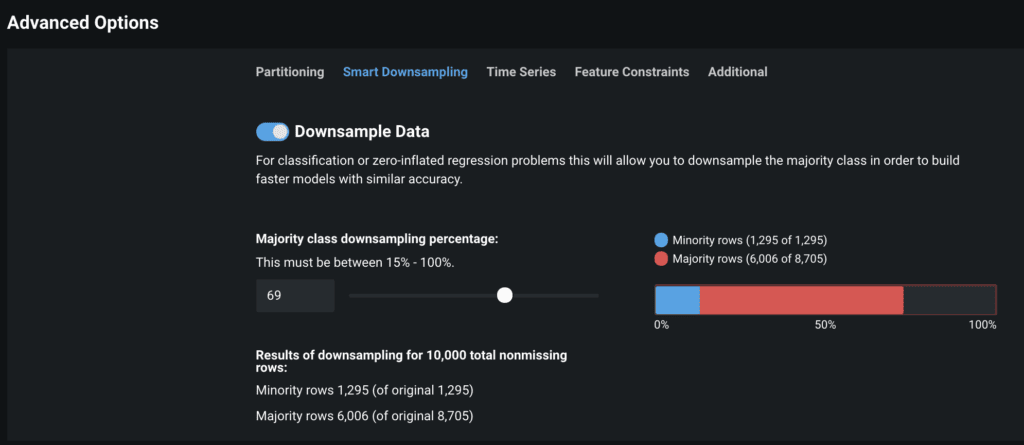
You can also use the Smart Downsampling technique (from the Advanced Options tab) to intentionally downsample the majority class in order to build faster models with similar accuracy (Figure 7). This can be done for both classification or zero-inflated regression problems.
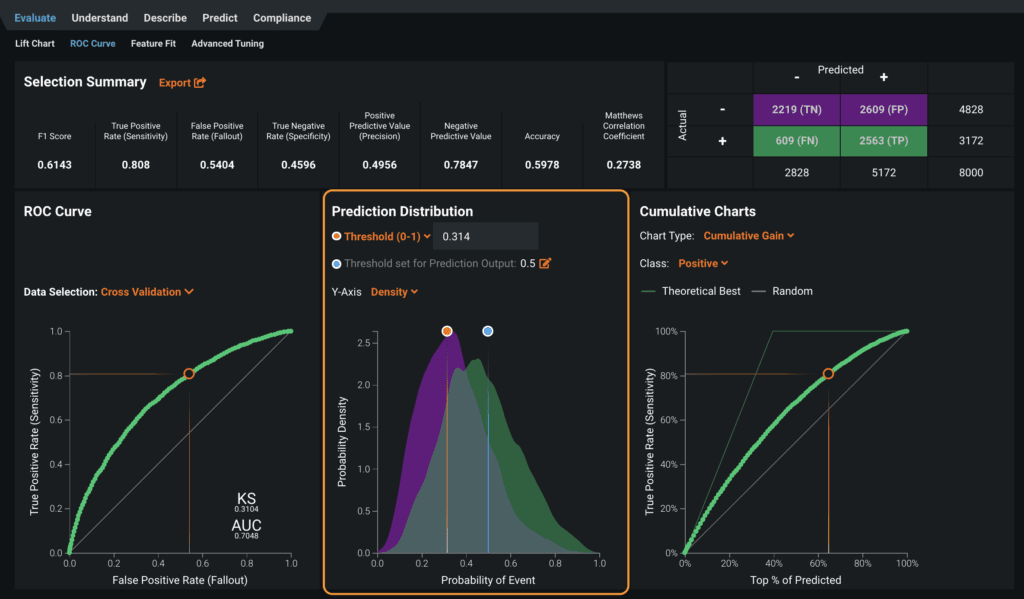
Finally, you could leverage information provided in the ROC curve to minimize the effect of imbalanced data to model performance. For instance, depending on the level of tolerance your business has for false positives versus false negatives, you could use the Prediction Distribution graph (Figure 8 ) to adjust the prediction thresholds for your classifiers. This could improve the predictions of the minority class.
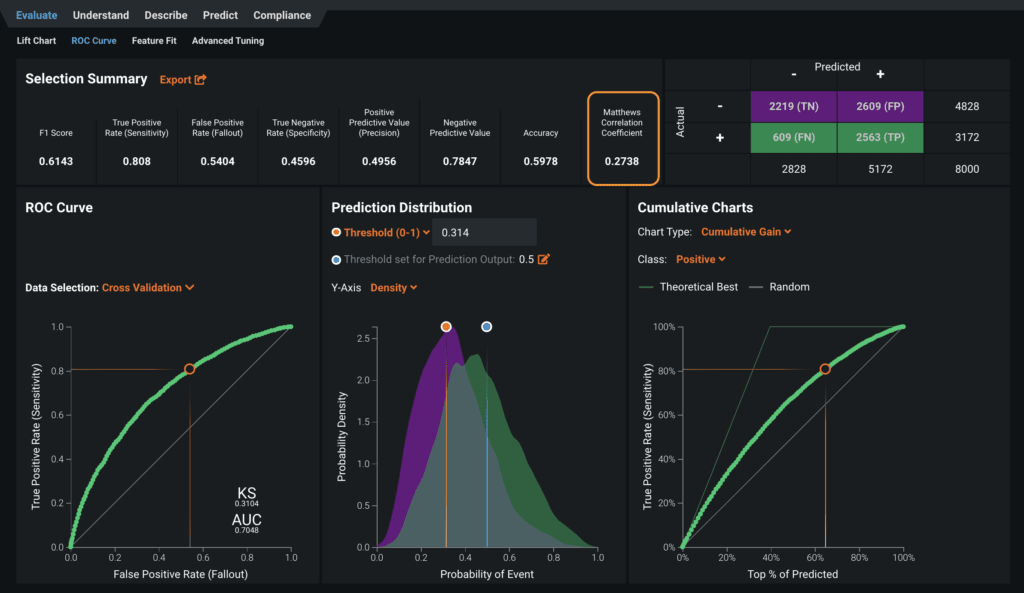
You could also pay more attention to the Matthews Correlation Coefficient (Figure 9) for model evaluation because it will give you a better sense of the model’s performance over the other metrics in that tab. The Mathews Correlation Coefficient was specifically designed to evaluate models built from imbalanced datasets.
More Information
Wikipedia: Matthews correlation coefficient
DataRobot documentation portal: Smart Downsampling

-
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read -
6 Reasons Why Generative AI Initiatives Fail and How to Overcome Them
February 8, 2024· 9 min read
Latest posts
