

AI Use Cases for Insurance: Part III
This post was originally part of the DataRobot Community. Visit now to browse discussions and ask questions about DataRobot, AI Platform, data science, and more.
Make sure to check out Part I and Part II in this Insurance Series to understand the use case we’re addressing.
There are many approaches which can be implemented for modeling insurance losses. We’re going to use the DataRobot platform to evaluate three different model setups for predicting losses:
- Frequency-Severity
- Tweedie
- Frequency-Cost
Let’s discuss each of these methodologies.
Note: The following calculations are used when determining insurance losses:
- Claim Frequency = Claim Count / Exposure
- Claim Severity = Total Loss / Claim Count
- Pure Premium = Total Loss / Exposure = Claim Frequency x Claim Severity
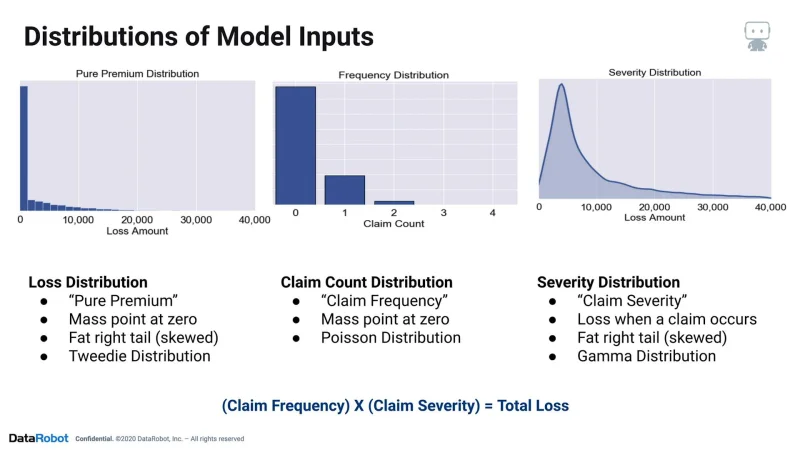
To understand why there are multiple approaches to modeling insurance losses, let’s break down the distributions of our model inputs.
First, we have our total loss distribution for each of our policyholders. This is the main distribution we’re interested in predicting when building pricing models. The Total Loss Amount / Exposures calculation is often referred to as pure premium, and this distribution is famously characterized by its mass point at zero and high amount of skew. A statistical distribution often used for modeling this distribution directly is the Tweedie distribution.
The total loss distribution can be broken further into two main components. The first component, the claim count distribution, reflects how many claim events occurred while a policyholder was insured. Claim Count / Exposure is often referred to as claim frequency and is also characterized by a mass point at zero. A common statistical distribution for modeling claim counts or claim frequency is the Poisson distribution.
The second component which can be broken out from the total loss distribution would be the severity distribution. This distribution entails the loss amounts conditional upon a claim occurring. The severity distributions are often fat tailed as well, exhibiting rightward skew. A commonly used statistical distribution for modeling claim severity is the gamma distribution; however, others including weibull (Y-BULL) and pareto distributions have been known to be used as well.
If you combine the claim frequency and claim severity distributions through multiplication, you will end up with a total loss distribution. Let’s talk about how we can model these components for building pricing models.
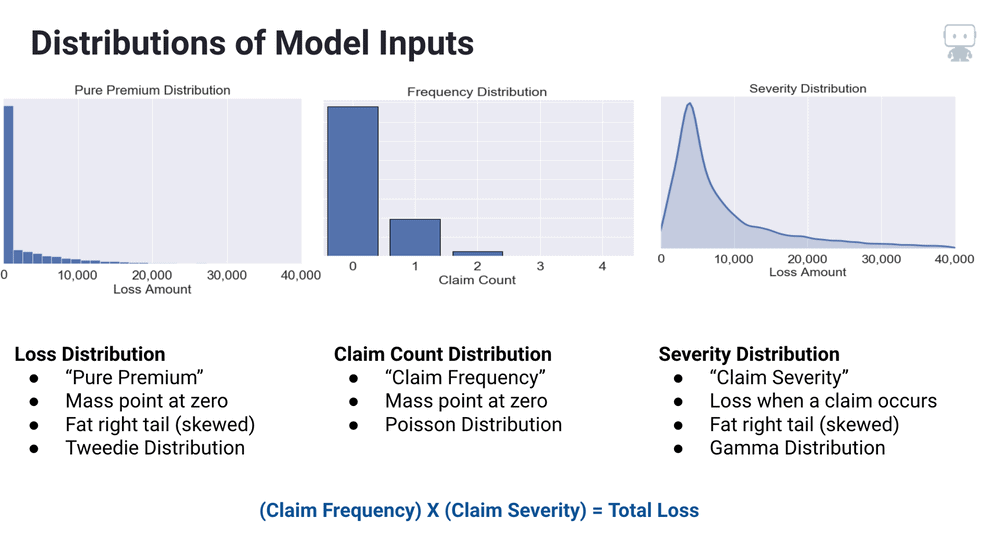
Frequency-Severity Approach
The first approach is the renowned frequency-severity model setup. This approach consists of building two models—one for each of the frequency and severity distributions—then combining predictions from each of the models through multiplication in order to yield a loss prediction ready for use.
The Frequency-Severity approach is often merited for its ability to break down both the frequency and severity components separately, which can be influenced by different factors in the real world.
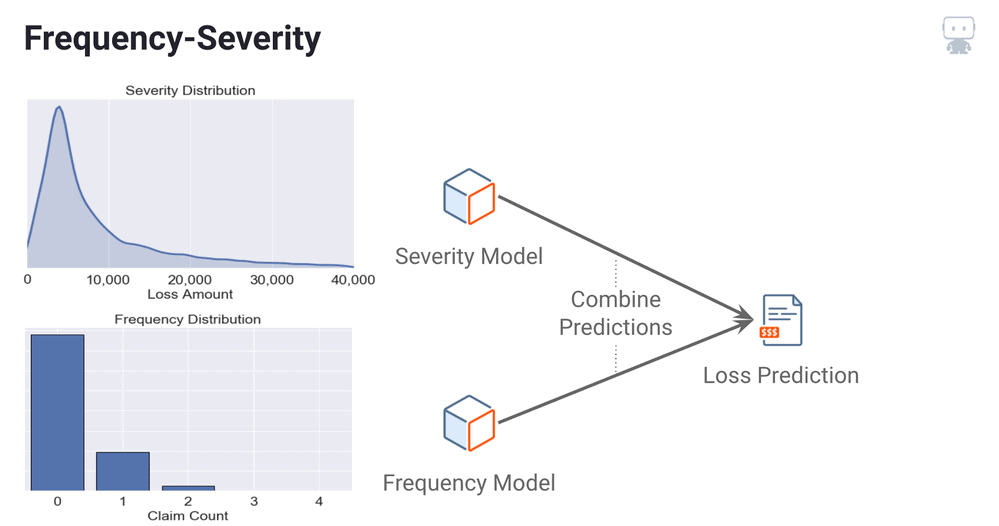
Tweedie Approach
The second approach is referred to as the Tweedie approach or pure premium approach. This model setup consists of a single model which fits to the total loss distribution directly.
This setup is convenient since only a single model is required; however, the approach can result in a lack of predictive accuracy if the frequency and severity distributions are characterized by extremely high variability. This model often requires tuning of its tweedie variance power parameter in order to yield optimal results.
Frequency-Cost Approach
The third and final approach which DataRobot will evaluate is Frequency-Cost.
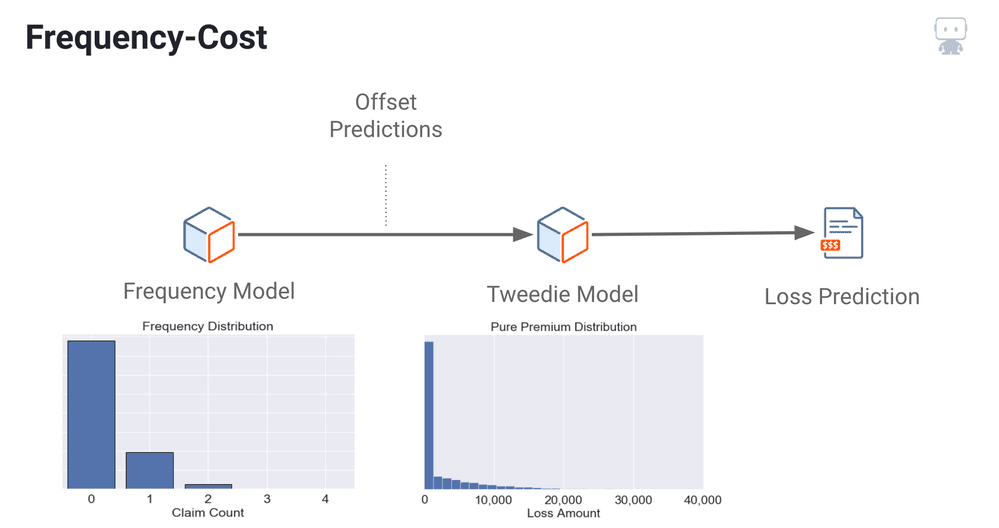
This methodology fits two models in sequential order.
- The first model is a claim frequency model.
- After fitting this model, DataRobot will offset these predictions
- Then, DataRobot will fit a Tweedie model on the total loss distribution using the frequency model offset as a starting point.
This model has shown to occasionally outperform the first two approaches in cases where loss distribution is very highly skewed.
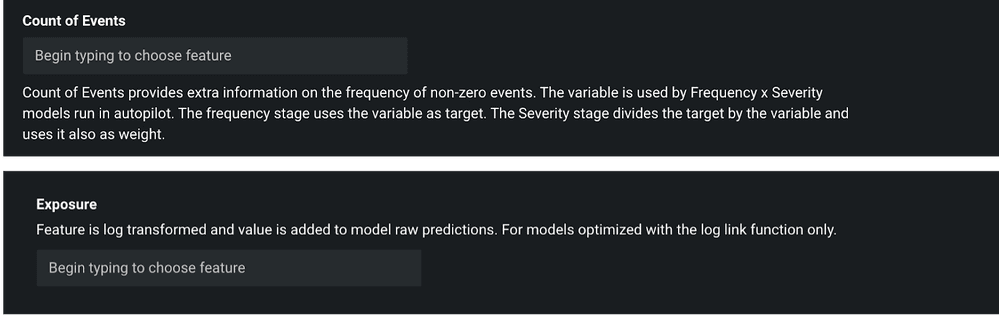
DataRobot will simultaneously evaluate all three of these approaches when building pricing models in order to yield the best possible model setup. It is worth pointing out that for all the three modeling approaches, since either frequency or pure premium is modeled, it is important to make sure that Claim Count and Exposure are set up appropriately. These setups can be done easily using Count of Events and Exposure options within the DataRobot platform, Show Advanced Options link (see Figure 5 below).
More Information
See the DataRobot Public Platform Documentation for Frequency and Severity models and for Show Advanced Options link .

-
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read -
6 Reasons Why Generative AI Initiatives Fail and How to Overcome Them
February 8, 2024· 9 min read
Latest posts
