DataRobotモデルデプロイ事始め
DataRobotでフィールドサポートエンジニアをしています小川です。
どんなに機械学習プロジェクトを立ち上げてもモデルを作らなければ企画倒れであり、モデルを作ってもデプロイ(予測できる状態)まで行わなければプロジェクトの完了とは言えません。DataRobotはモデルの自動作成という強力な特徴に目が行きがちですが、モデルのデプロイに対しても様々なケースに対応した手法を持っています。今回は、DataRobotにおけるモデルデプロイのパターンごとの特徴について記載して行きます。
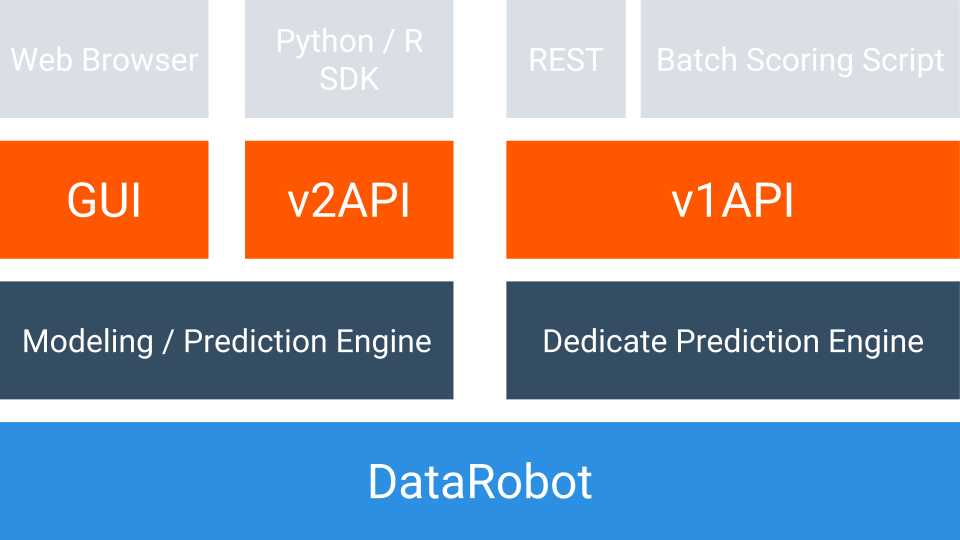
DataRobotのデプロイは大きく三つの方式に分かれます。GUIによるデプロイ、APIによるデプロイ、コード書き出し機能によるデプロイの三つとなります。
GUIによるデプロイ
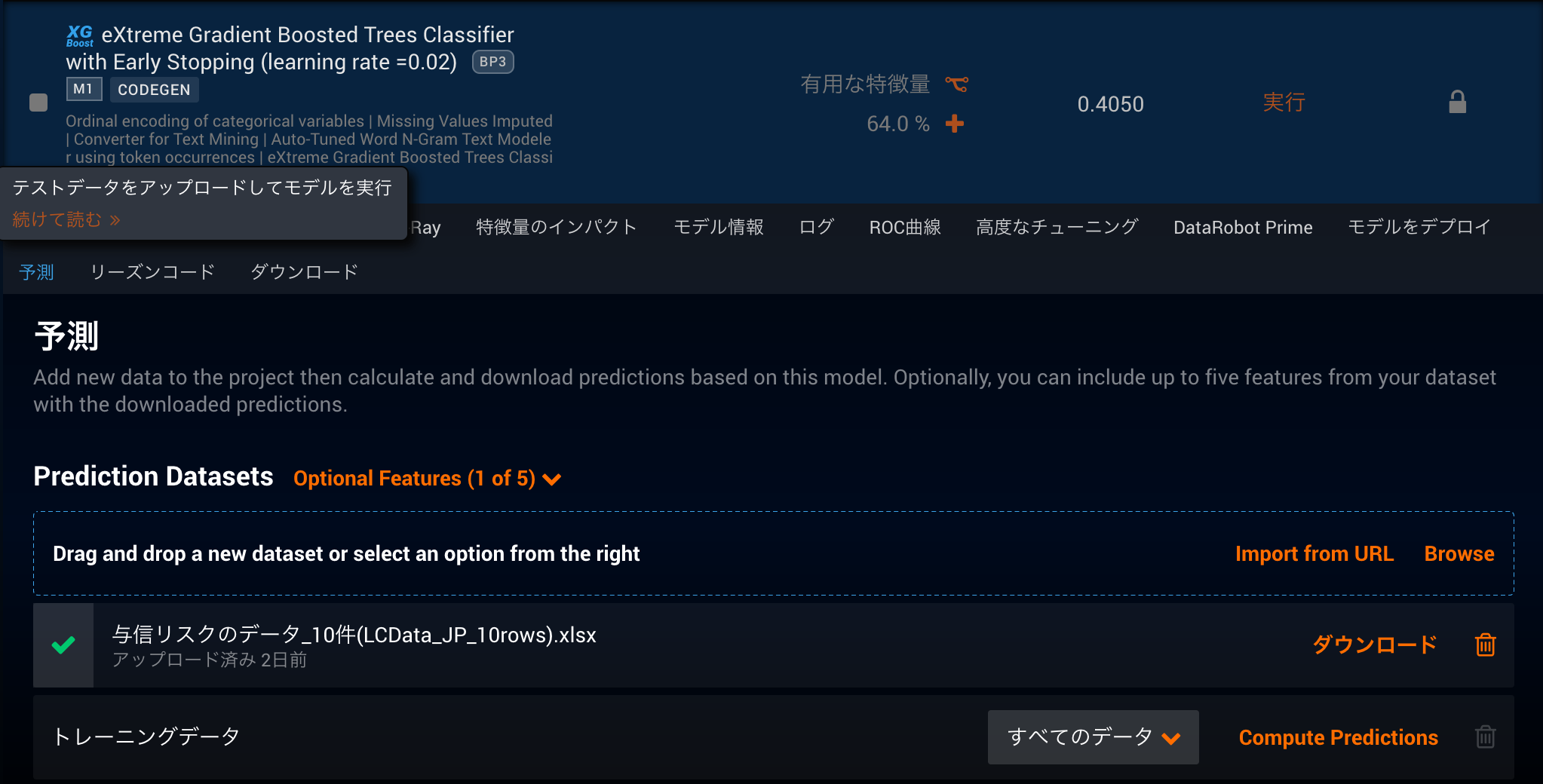
もっとも手軽でコーディングも必要ないため、結果の出力を確認したい時や予測を行うタイミングが頻繁にないケースに重宝します。DataRobotで作成したモデルの中から予測タブを選択します。予測を行いたいcsvかexcelファイルをドラッグ&ドロップ(ファイルブラウジングでも可能)していただくとファイルがDataRobotにアップロードされます。アップロードしたファイルに対して予測を計算するボタンを押せば、予測エンジンが予測を行い、完了後に結果をダウンロードできるようになります。デフォルトでは行番号と予測値のみが返ってくる設定になっていますが、最大5つまでの特徴量の値も結果に結合して出力することが可能です。
特徴として750MBまでのファイルをアップロードできるため、列数にもよりますが、数百万行程度のデータを一括で予測することも可能です。手元のローカル環境からのアップロード以外にもURLからのファイル読み込みに対応しているため、予測用のデータをs3などのオンラインストレージに配置し、ダウンロードurlから読み込むなどの運用も可能です。
デプロイに必要な作業はモデルを作成するだけであとは数クリックで予測ができてしまいます。全て手動で行えるのでエンジニアリングスキルがいらないデプロイとなりますが、その分自動化することは難しく、頻繁に予測が発生する際には運用が大変になります。また注意点として、このデプロイ方法による予測では、モデリングエンジンを予測エンジンとして使用するため、モデリングエンジン側のリソースを使用してしまいます。
APIによるデプロイ
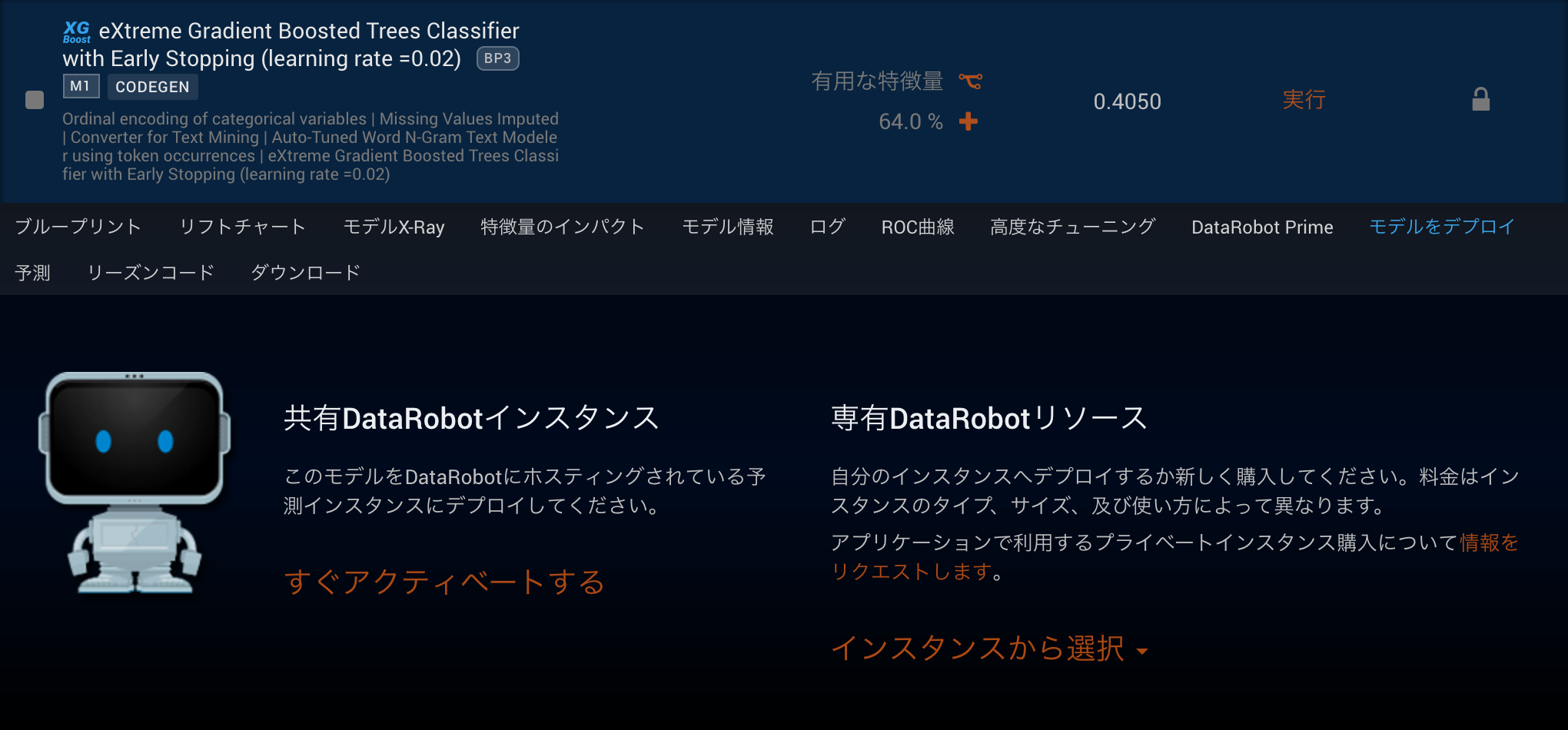
システムに予測を組み込みリアルタイム予測をしたいケースや予測をスケジューリングして毎日の運用を自動化したいケースでは、APIによるデプロイがとても便利なものになっています。またモデリングから予測までをAPIによって完全に自動化することも可能です。
APIは2種類あり予測専用のPrediction APIとGUIでできる操作全般をAPIで行えるModeling APIがあります。APIを有効化する作業は、各モデルのモデルをデプロイタブから形式を選ぶだけで完了します。その際にデプロイされたモデルへの予測を行うためのサンプルコードも確認することができます。共有DataRobotインスタンスへのデプロイからはModeling API、専有DataRobotリソースへのデプロイからはPrediction APIのサンプルコードを確認できます。
Modeling APIの操作ではSDKが利用でき、DataRobotはPythonとRの2種類のSDKを提供しています。Modeling APIによる予測は実質的にGUIによる予測をAPIで操作している形になります。コーディングは発生しますが、GUIでは難しかった毎日の予測を自動化することも簡単に実現可能です。またGUIではcsvとexcelファイルが対応しているデータ形式でしたが、Modeling APIでは、Python SDKではpandas.DataFrame、R SDKではdataframeを予測対象のデータとしてアップロードすることも可能です。Modeling APIでは予測だけでなくモデリングの操作も行えることから、予測だけでなくモデリング含めての完全自動化を実現することも可能です。注意点としては、GUIと同じようにModeling APIによる予測はモデリングエンジンを予測エンジンとして使用するため、モデリングエンジン側のリソースを使用してしまいます。
Prediction APIの操作はREST APIで行います。GUI、Modeling APIの操作とは完全に独立していて、モデリングエンジンとのリソース競合を起こさない専有予測エンジンに対してのAPIとなります。専有DataRobotリソースへのデプロイから確認できるサンプルコードはPythonコードで書かれていますが、REST APIのため、言語を選ばずに実装することが可能です。REST形式であり、一回の予測でbodyとしてpostすることができるデータサイズは10MBが上限となります。専用予測エンジンでは、モデルをメモリにキャッシュする機能を備えているため、よりレイテンシが求められるケースに向いています。ただ、一回当たりに予測できるファイルサイズ上限がGUIやModeling APIに比べて小さいことから大量の予測を行う場合には、手元でファイルの分割を行い、都度予測を行い、予測結果をマージするようなコーディングを施さなくてはいけません。
バッチで予測を行いたいケースかつモデリングエンジンと競合させないためにPrediction APIを利用したいが、手元のファイルが大きい場合には分割用のコーディングをしないで済むようにBatch scoring scriptという専用のPythonスクリプトも提供しています。こちらは10MBを超えるファイルを読み込んだ場合には、スクリプト内でファイルをPrediction APIに対応する範囲に分割して、予測を行い、予測結果の結合まで自動化します。
APIにおいてSDKやBatch Scoring Scriptを利用する場合には、クライアントのバージョンも重要になります。DataRobotはクラウド版とオンプレ版を提供していますが、クラウド版においては常に最新のSDKとBatch Scoring Scriptを利用するようにしてください。またオンプレ版にはバージョンが記されているため、そのバージョンにあったSDKやBatch Scoring Scriptを利用します。SDKやBatch Scoring Scriptは内部でPythonやRを利用しているため、PythonやRのバージョンについても気をつける必要があります。
コード書き出し機能によるデプロイ
これまでにあげたDataRobotのプラットフォームを活用したデプロイは予測用のサーバを立てずにDataRobotから手軽にモデルがデプロイできるというメリットがありました。しかし、中にはマイクロ秒レベルの予測速度を求めるケースやネットワークとしてDataRobot環境と分離した環境から予測を実行したいケースがあります。DataRobotとしては、その状況に対応した予測用のコード書き出し機能をDataRobot PrimeとスコアリングコードJARアーカイブと2種類の機能を一つのオプションとして提供しています。
オプションが有効にされている環境の場合、DataRobot Primeに対応する各モデルからDataRobot Primeタブから線形近似のモデルを作成することができます。作成された線形近似のモデルは他のモデルと同じようにどのようなモデルなのか確認することができますし、これまで紹介してきたGUIによるデプロイやAPIによるデプロイをしていただくことも可能です。
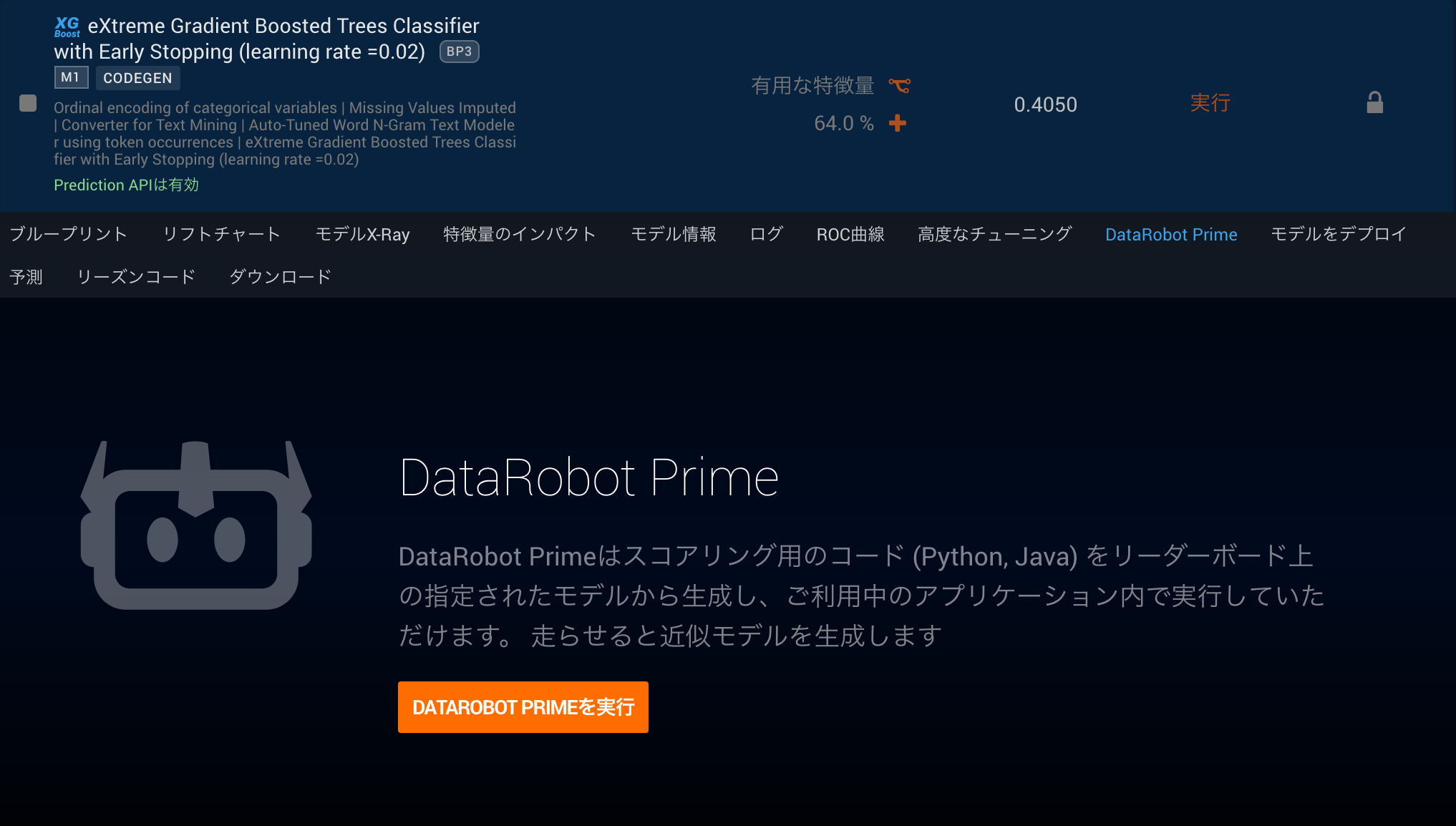
DataRobot Primeによって新規に作成されたモデルのDataRobot Primeタブを開いていただくとルールの数とモデルの精度指標との関係を表すグラフが出力されます。
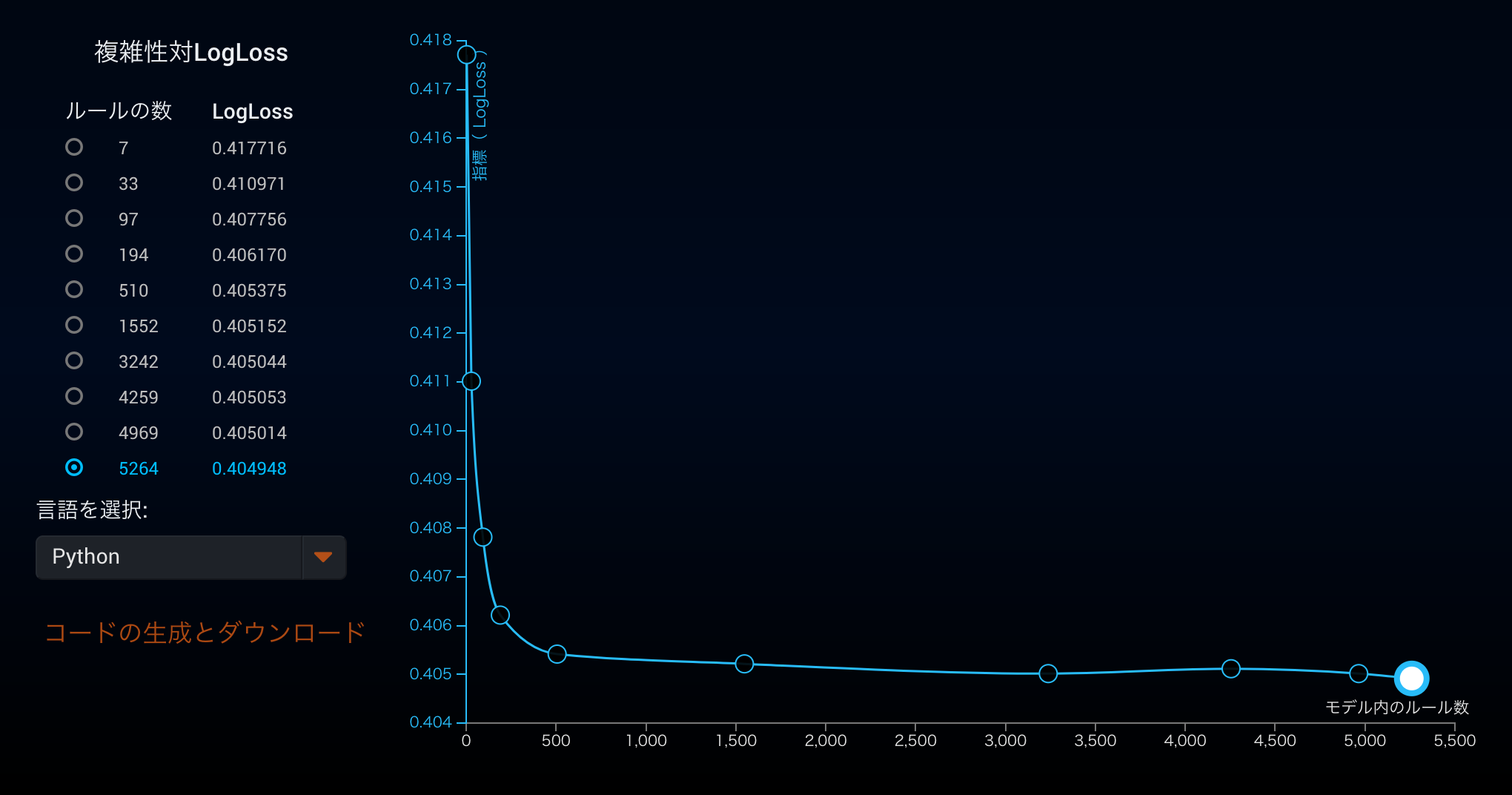
デフォルトではもっとも精度がよくなるルール数でモデルが作成されていますが、レイテンシが小さいルール数の少ないモデルを精度と比較しながら選んでいただくことができるようになっています。最後に言語としてPythonまたはJavaを選択いただくことによって、その言語に対応したコードが生成されます。
スコアリングコードJARアーカイブでは、DataRobot Primeと違いモデルそのものをjarファイルとしてダウンロードすることができます。DataRobot Primeに比べ、Javaのみの対応(コードの一部はバイナリの状態)となりますが、線形近似でなくDataRobotで利用されている内部のロジックと全く同じものを利用することができます。
特にDataRobot PrimeとスコアリングコードJARアーカイブどちらを使うべきかというと、線形近似したモデルを見ながら、ある程度モデルの処理を変更していきたい場合には、DataRobot Primeが有効です。逆にモデルには一切手を加えずにDataRobotで作成したモデルをそのまま使っていきたい場合には、スコアリングコードJARアーカイブをおすすめします。スコアリングコードJARアーカイブでもコードを出力する機能がありますが、モデル自体はバイナリになっているため、変更できる箇所は入出力部分のみとなります。
まとめ
DataRobotのモデルデプロイの手法ごとの特徴についてまとめさせていただきました。機械学習プロジェクトにおいて、ただ精度が高ければいいだけでなく、定期的な実行やレイテンシが求められるケースもあります。DataRobotでは様々なニーズを満たすためにニーズそれぞれに対応した様々なデプロイ手法を提供しています。

DataRobot Japan 3番目のメンバーとして参加。現在は、金融業界を担当するディレクター兼リードデータサイエンティストとして、金融機関のお客様での AI 導入支援から CoE 構築の支援を行いながら、イベント、大学機関、金融庁、経産省などでの講演を多数実施。初期はインフラからプロダクトマネジメント業、パートナリング業まで DataRobot のあらゆる業務を担当。前職はデータマネジメント系の外資ベンダーで分析ソリューション・ビッグデータ全般を担当。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事