機械学習モデルのデプロイ 前編
DataRobot フィールドサポートエンジニアの小島です。
機械学習!というと、自然と「いかに精度のよいモデルを作り上げるか」に注目が集まります。
しかし、「精度のよいモデル」を作り出すことに成功したあと、ビジネス上での効果に結びつけていくためには、次に非常に重要なステップが待ち構えています。
それが、機械学習モデルのデプロイ、つまり実際にモデルを使う、使えるようにしていく、というステップです。
一般的には、機械学習モデルはそれを使って対象データに対する予測を行う事により、実際のビジネスへの影響を作り出し、直接的なROIを生み出していくといえます。
では、そうして「モデルを使って予測を行う」ためには、どのような事をしなければならないのでしょうか? 実装ケース毎に整理してみたいと思います。
一般的な機械学習モデルの実装
(1)分析環境で予測処理までを行う
機械学習モデルの利用では、多くの端末に公開して利用をするのではなく、分析を行う担当者がそのまま予測処理までを同じツール、同じ分析プラットフォーム上で行い、予測結果のデータを作り出す、といった利用ケースがあります。

これはモデリング中のテストのための予測処理はもちろんの事、「来月に訪問すべき得意先リストの作成」といった、速度も頻度もそれほど極端に求められない、もしくは、一度実施すればそれで役目を終える、といったケースでの予測処理等で利用される事が多いです。
利点:
・最も簡便な方法であり、容易に行うことができる。
考慮点:
・広くデータを利用する場合、予測処理の結果を「配布する」形となるため、
実際の利用者が予測データを取得するまでにかかる時間(タイムラグ)について考慮が必要。
・分析環境として利用できる環境が限られている場合、予測処理で時間を専有してしまうことで他の分析プロジェクトの時間を奪ってしまう可能性に注意が必要。
データサイエンティストが作り出した機械学習のモデルによる予測がビジネス上で効果を出し、その威力・効果が認められるにつれ、一般的には予測に求められるシステム的な要件もそれにつれて高度になっていきます。
例を上げれば「より多くの端末上での予測処理」「より頻繁なモデルの更新」
そして「より高頻度な予測処理の実行」といった具合です。こうなってくると、分析環境と予測環境のあり方を変えていく、考え直していく必要性がでてきます。
一般的な機械学習モデルの実装
(2) モデルによる予測を行う中央集中型のサーバを構築する
予測処理を実行するための「予測処理の専用サーバ」を構築し、予測処理を必要とする端末からネットワーク経由でアクセスさせる形で共同利用するという実装です。
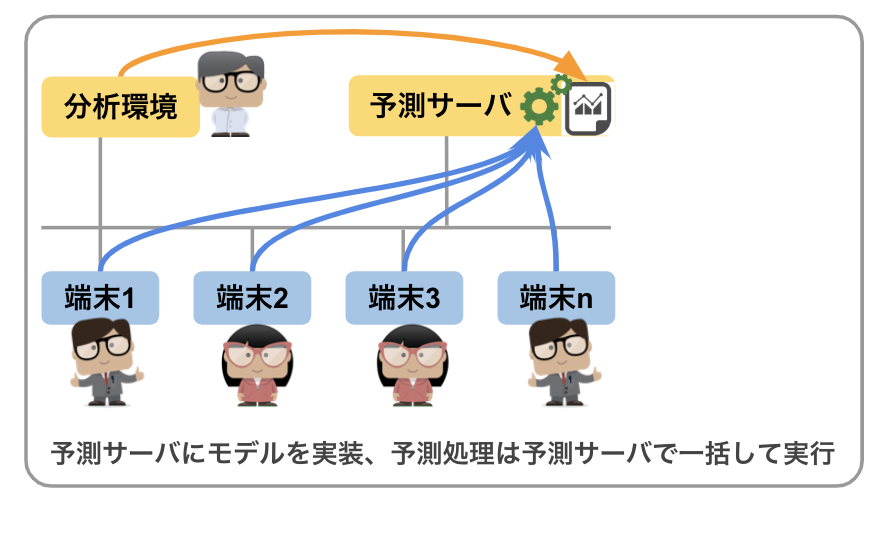
データサイエンティストが生成した機械学習モデルをこの予測専用サーバで稼働させます。
予測処理を必要とする端末は、この予測専用サーバにネットワーク経由でアクセスし、予測が必要なデータの投入と、予測結果の取得を行います。
システム構築の世界で一般的にC/S(クライアント・サーバ型) と呼ばれる形をイメージするとわかりやすいかも知れません。
近年、こういった予測専用サーバは端末側に専用の接続ソフト等を必要としない、REST型のAPIエンドポイントで構成される場合が一般的となってきました。
こういった構成である場合、接続する端末の種別を選ばないため接続性に優れています。
利点:
・端末側はモデルを利用した予測処理をサーバに「任せる」事ができる。そのためモデルの管理、
予測処理の実行といった処理についてはサーバ側にまかせ、APIへの接続のみを考慮すれば良い。
・機械学習モデルの更新がサーバに対して一回で済むため運用管理面が容易。
考慮点:
・予測サーバ上では、2つの仕組みを構築する必要があります。
「生成されたモデルを導入し、予測処理を実行する」「APIを起動し、予測データの授受を行う」
そしてこれらを維持、運用していく必要もあります。
・端末と予測サーバに何ら問題がなくとも、その間をつなぐネットワーク上に
問題が発生すると、一切の予測処理を行うことができなくなります。
堅牢なネットワーク設計、もしくは接続できなかった場合の代替案を考慮しておく事が必要です。
・大量の端末から多くの予測処理が投入された場合を想定し、予測サーバ側の
コンピュータは性能を適切に設計しておく必要があります。
・対応できるREST処理には上限がある事が一般的です。数GBといった大容量ファイルについて
の対応について考慮しておく事が必要です。
また、非常に重要な点としてこの予測専用サーバ上で予測処理に使われているモデルが、過去どれくらい利用されているか、利用者は誰か、更新が必要なモデルがどれか、という事もあわせて管理していく必要があります。
一般的な機械学習モデルの実装
(3) 利用する端末個別にモデルを「インストール」する
多くの端末、それぞれで、その場で機械学習による予測を行いたい、(これらの端末でモデリングを行う必要はない)、といった要件が出てきた場合、端末それぞれに予測モデルを配布し、利用できるようにするという、非常にシンプルな実装です。特に、ネットワーク接続ができない、もしくは接続が不安定な端末が存在する場合に考慮すべき実装とも言えます。
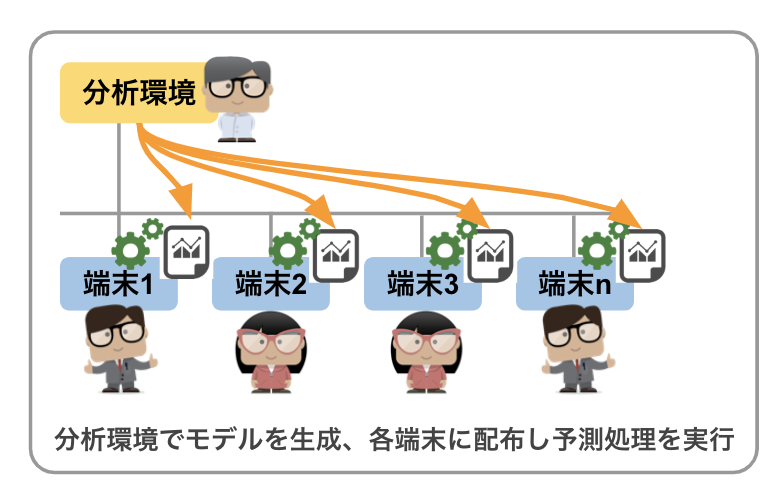
ここでいう「端末」は、次々に生み出されるセンサーデータに対する予測を行い、次のアクションに反映するような製造現場のロボットであるかもしれませんし、人がWeb画面で操作するアプリケーションが稼働する数多くのサーバや、もしかすると営業担当が出先のカフェで利用するノートパソコンであるかも知れません。
機械学習により生み出されたモデルをこれら内部に組み込み、「端末」が単独で対象データに対する予測ができるようにしていくのがこの実装方式です。
ここで考えなければならないのは、機械学習で生成されるモデルは、一般的なソフトウェアと違い「インストーラ」といったものはありません。
(「次へ」ボタンを連打すれば “インストール完了!利用開始!” ではないのです)
そのため、これらの端末上では「モデルを導入し、そのモデルを使って予測処理を実行する」仕組みの導入も合わせて考慮していく必要があります。
利点:
・予測処理をその端末内部に組み込み、完結するため、その端末からのネットワーク接続や
その通信性能の確保、といった点を考える必要がない。
・常時ネットワークに接続できない端末、接続帯域が限られている端末においてもネットワークの
状況に影響を受けない、安定的な予測処理を行う事が可能。
考慮点:
・機械学習モデルと、そのモデルを利用して予測を行う仕組みをあわせて全ての
端末に導入する必要がある。
・機械学習モデルは新しいものに更新されていくため、端末それぞれに配布したモデルをどう管理、更新していくかを考えておく必要がある。(例えばモデルの更新が毎日必要、そしてこのモデルを利用する端末は100以上…という状況を想像すると、手動での運用では無理がある事が想像できると思います。)
機械学習モデルの利用 / まとめ
機械学習プロジェクトを行う場合、どうモデルを作り上げるか、という点が重要視されがちです。しかし、モデルがその威力・効果を発揮するためのデプロイの方法論、戦略についても、業務で必要とされる予測処理のあり方を踏まえた上で、事前に設計をしておくことが非常に重要です。
言い換えると分析システムの構築では、モデリングを行う基盤のみならず、生成された機械学習モデルのデプロイのあり方までをしっかりと考慮して進める必要があるという事です。これができていないと、たとえ素晴らしい機械学習モデルの作成に成功したとしても、最終的に手に入れたい実際のビジネス上での効果 – ROI には結びつかないプロジェクトとなってしまいます。
一般的なシステム構築と同じく、すべての用途 / 要件に適合するアーキテクチャというのは機械学習モデルの実装においてもなかなか難しく、現実的には上記の1, 2, 3 のパターンすべてを要件にあわせて組み合わせながら実装していく事になります。
今回の記事では一般論として機械学習モデルの実装について述べました。
次回の記事ではこれらモデルのデプロイをDataRobotはどう噛み砕き、製品として実現しているのかについてご案内したいと思います。( 本記事の後編を掲載しました –> こちら )
— — —
執筆者について

小島 繁樹(Shigeki Kojima)
DataRobotデータサイエンティスト。システムインフラ全般、特に大規模 RDB 基盤に関する経験を保有。機械学習モデルの開発からビジネス適用に渡り技術的視座から支援を実施、また技術的トレーニングカリキュラムの開発を行っている。主に流通・小売・また通信業界のお客様に対する支援を担当。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事