機械学習モデルのデプロイ 後編
DataRobot フィールドサポートエンジニアの小島です。
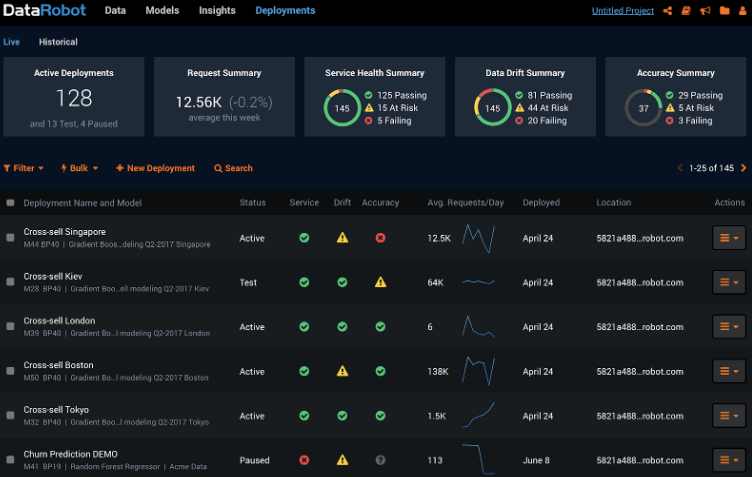
DataRobotの予測エンジン 3種
機械学習モデルの利用 (DataRobot の実装)
1. 共有予測エンジン (通称:V2エンジン)

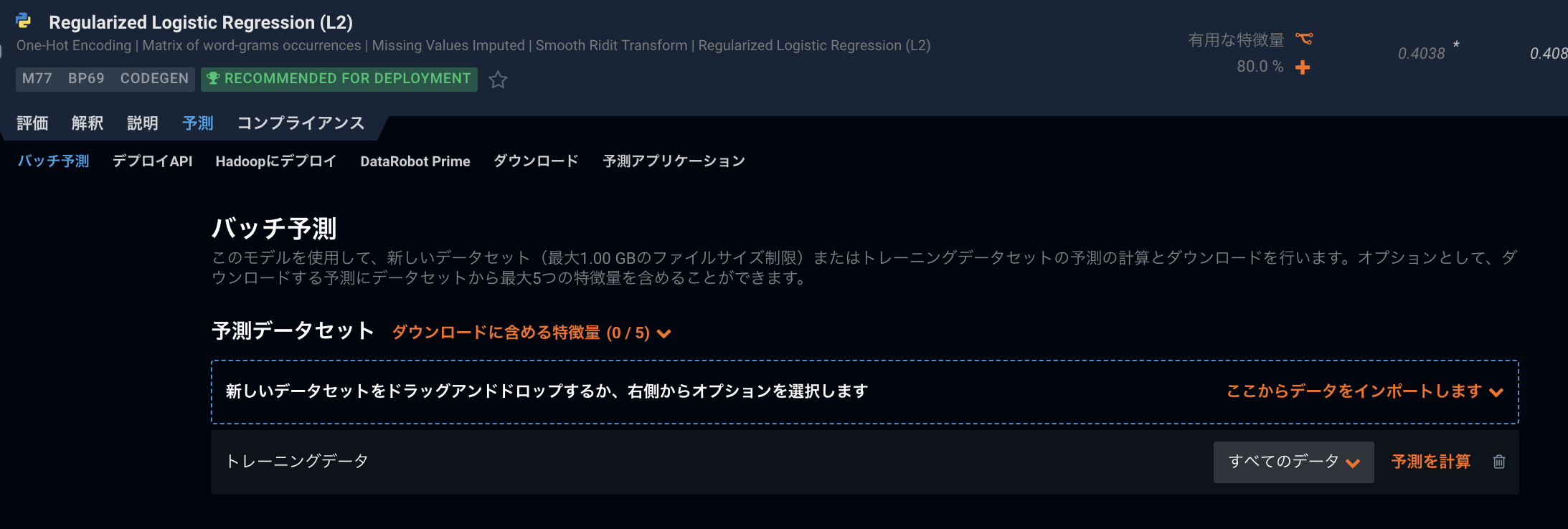
機械学習モデルの利用 (DataRobot の実装)
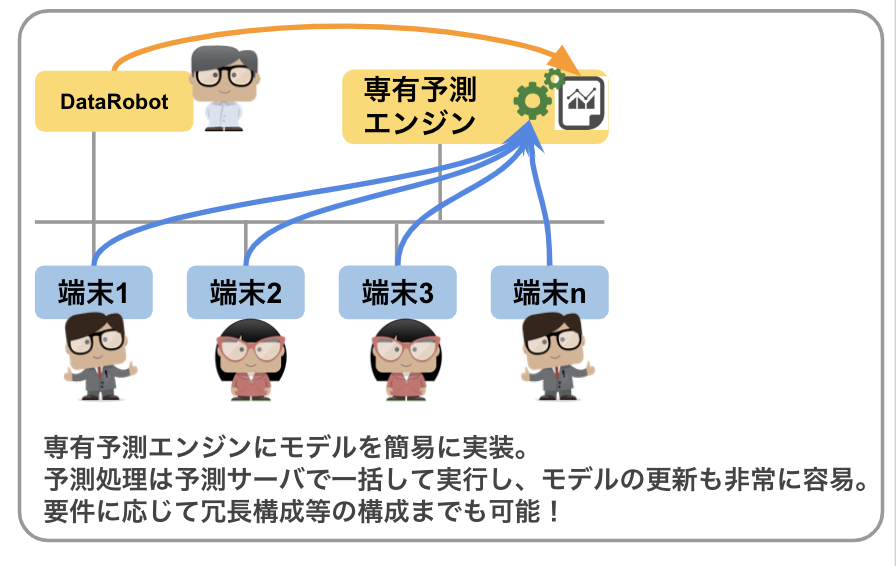
2. 専有予測エンジン (通称:V1エンジン)
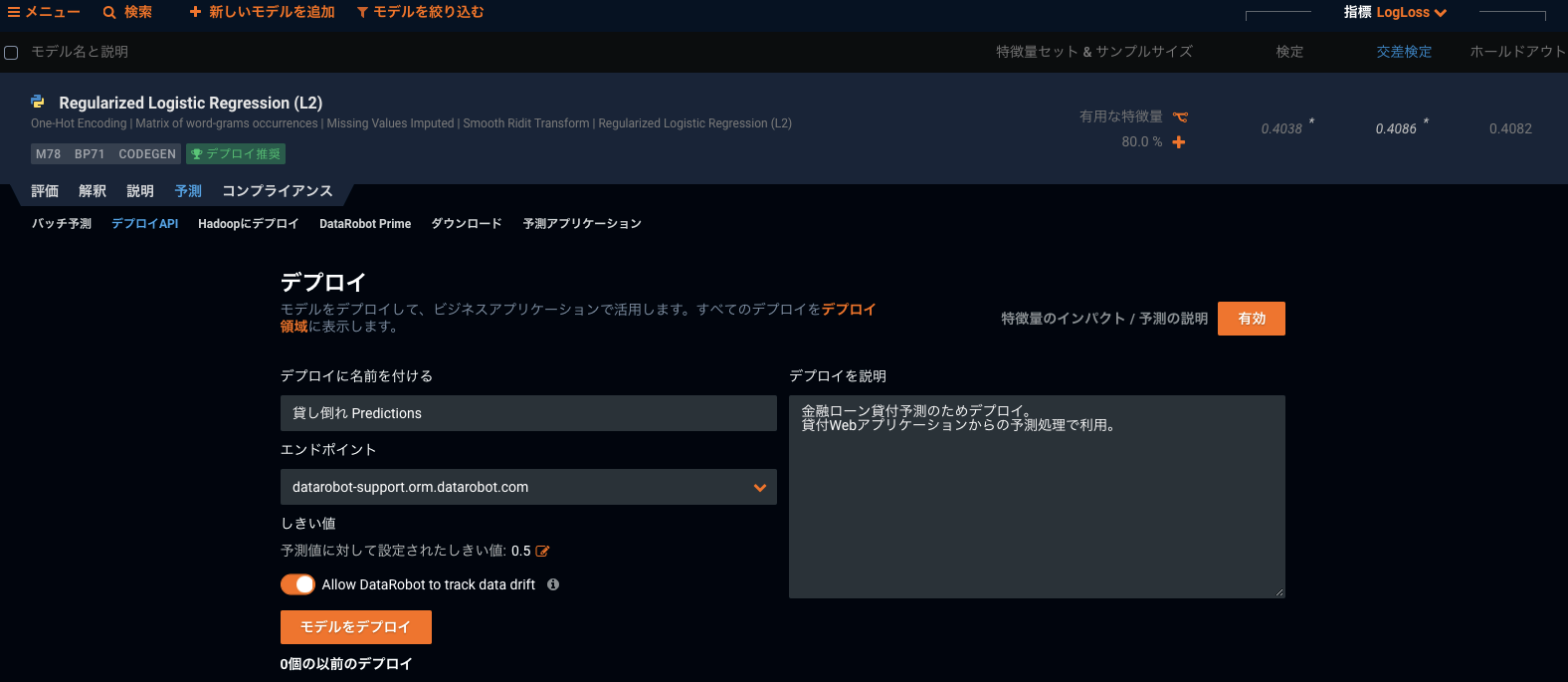
DataRobotをご利用であれば、作成したモデルのメニュー画面から “予測” -> “デプロイAPI” と選択し、”モデルをデプロイ” というボタンを押下するだけで、このモデルが全自動でV1エンジンにデプロイされ、ユーザから利用できるようになります。
デプロイを行うときにはモデルの管理のため、「何のために作ったモデルなのか」「想定している利用者は誰か」といったコメントをモデル毎に自由に残すこともできるようになっています。
これによりDataRobotで作成したモデルが、多くの端末からAPI経由で利用できるようになります。また、このV1エンジンは予測処理専用に設計されており、その処理性能にも優れています。
V1エンジンはhttp REST 型のAPIで構成されており、端末側には接続ツール等を導入する必要がありません。デプロイ後、直ちに予測処理を開始する事ができます。
加えて、DataRobotはユーザがすぐにコピー&ペーストで実行可能な予測処理のためのPythonのコードを出力することもできます。
(予測デプロイのコードについては こちら の記事もあわせてご参照ください)
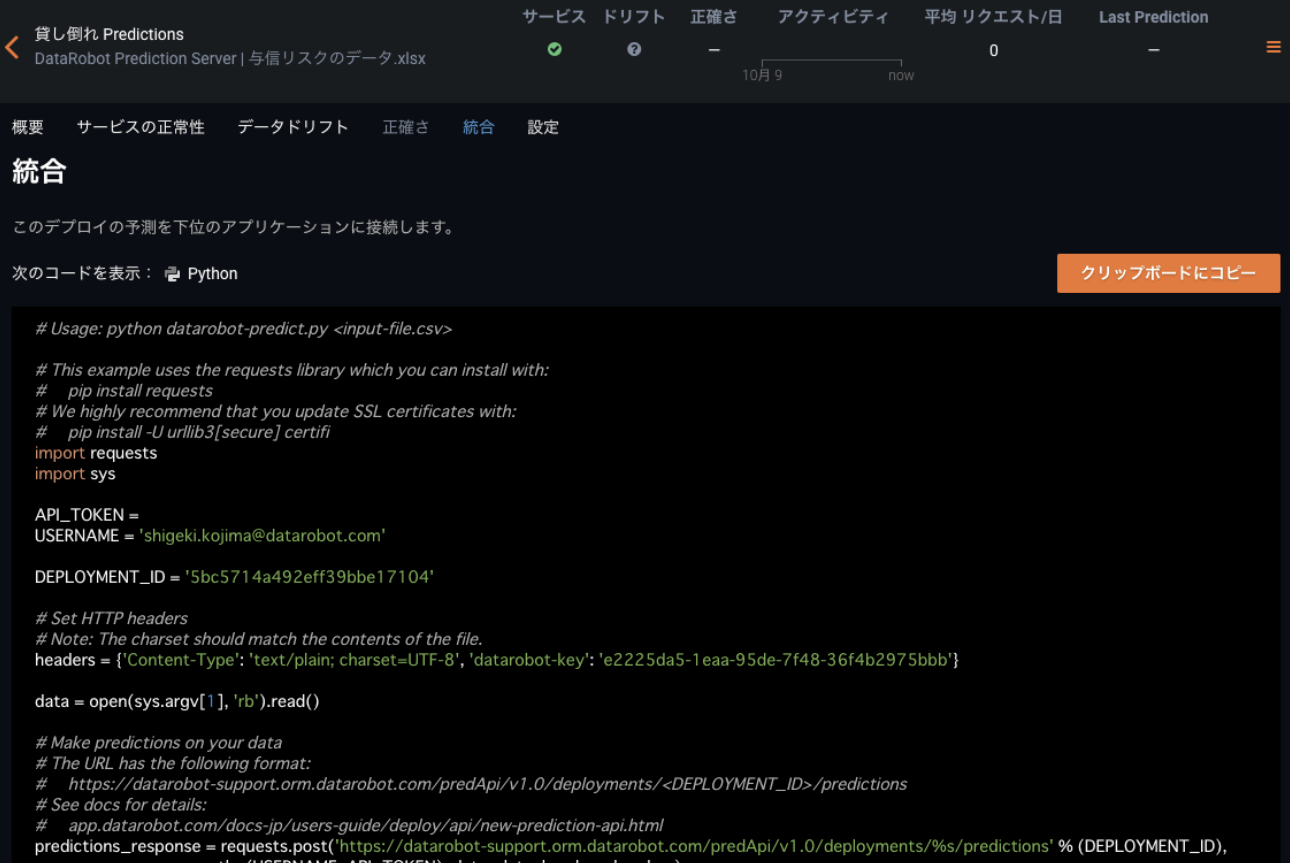
またDataRobotでは、こういった不特定多数のユーザがモデルを利用する際に重要となる、
・どのモデルがどれくらい利用されているのか / 利用されなくなっているのか
・予測精度が落ちてきているモデルはどれなのか
・更新すべきモデルはどれなのか
といった管理もダッシュボードで集中的に管理ができる機能が実装されています。
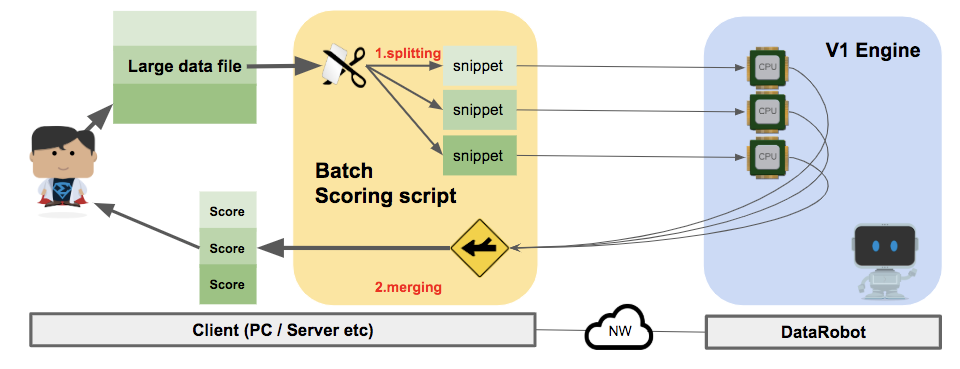
このV1エンジンはhttp REST 型のAPIであり、数GBといった大きさのファイルの予測については予測性能の確保、転送エラーの抑止等のため実行できない仕様となっておりますが、そういった大きなファイルでの予測実行が必要なケースのため、DataRobotはバッチスコアリングというツールをご提供しています。
このツールは、大きなファイルをV1エンジンが処理できる大きさに分割、並列で予測処理を実行、結果をマージしユーザに提供するといった一連の処理を全自動で実行する事ができます。
DataRobotではモデルデプロイについての専用トレーニングである、DRU Model Deploy Trainingを開催しておりますが、ご参加いただいた皆様から「とても便利なものだと理解できた」「今後は積極的に利用したい」というフィードバックを最もいただくのがこのV1エンジンです。
機械学習モデルによる予測の実装、管理を行う時に必要となる機能について、データサイエンティストの経験に基づいてよく考えられた実装となっています。DataRobotをご利用であれば是非とも利用について検討いただきたいと思います。
機械学習モデルの利用 (DataRobot の実装)
3. DataRobot Primeエンジン (通称:Primeエンジン)
DataRobotはネットワーク経由で利用する製品ですが、モデルによる予測処理はネットワークに接続されていない / 接続が断続的にしかできない端末でも実行する必要がある場合があります。DataRobotではこういったご要望についても対応する事が可能です。
DataRobot Prime エンジンはDataRobotで作成されたモデルを、PythonもしくはJavaの実行形式でダウンロードし、各端末上で実行できる機能オプションです。
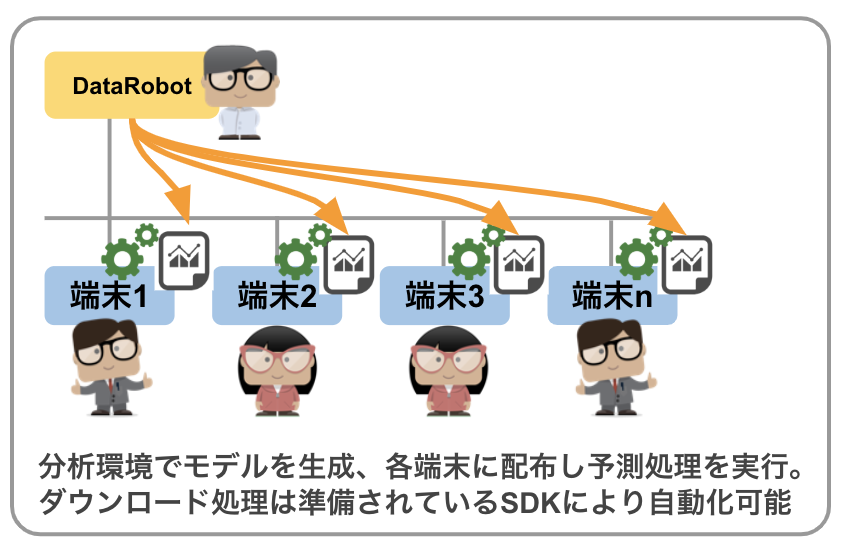
機械学習モデルの利用 (DataRobot の実装) まとめ

DataRobot University のご案内


DataRobotデータサイエンティスト。システムインフラ全般、特に大規模 RDB 基盤に関する経験を保有。機械学習モデルの開発からビジネス適用に渡り技術的視座から支援を実施、また技術的トレーニングカリキュラムの開発を行っている。主に流通・小売・また通信業界のお客様に対する支援を担当。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事