MLOps – 機械学習モデルの活用、その先にあるチャレンジ Part 1
はじめに
DataRobotの小島繁樹です。ビジネスへのAI、機械学習の活用は日々喧伝され、既にバズワードと疑われるフェーズを遥かに超えています。日本でも多くのお客様がその効果を認め、巨大なビジネス効果創出にも成功しています。
こういった背景の中、「多くの機械学習モデルの威力を維持するための統合管理」といった、これまで存在すらしていなかったあらたな課題が先進的な企業においてその姿を表しつつあります。今回ご紹介するMLOpsという考え方、技術は、まさにこうした背景から生み出されたものです。
機械学習モデルライフサイクル
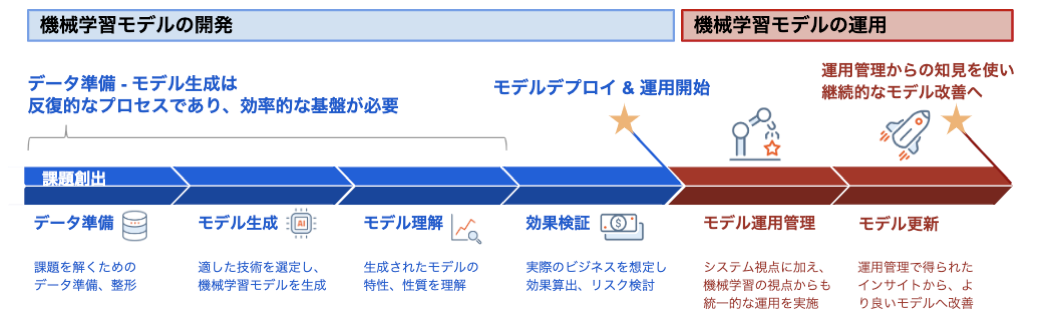
機械学習プロジェクトにより生み出されるモデルのライフサイクルとして、一般的に
課題の創出(発見) → データ準備→ モデル作成→ モデル理解 → 効果検証→ デプロイ→ ビジネス上での利用
という文脈が語られます。ビジネス上で利用するためのデプロイが一つの大きなゴールというわけです。しかし、実際のプロジェクトはここで完了する事はありません。
→ モデルの運用監視 → モデルの更新
という段階を経る事で、作成されたモデルの威力を落とさない運用を実現し、またモデルの精度等をよりビジネス課題に即した物へと進化させていくサイクルを実現することができます。
では、機械学習モデルの運用で何が必要とされるのか、また効果的であるのかについて見ていきます。
機械学習モデル運用時のチャレンジ
機械学習モデルの「運用」における具体的なチャンレンジとしては、下記が代表的なものとして存在します。
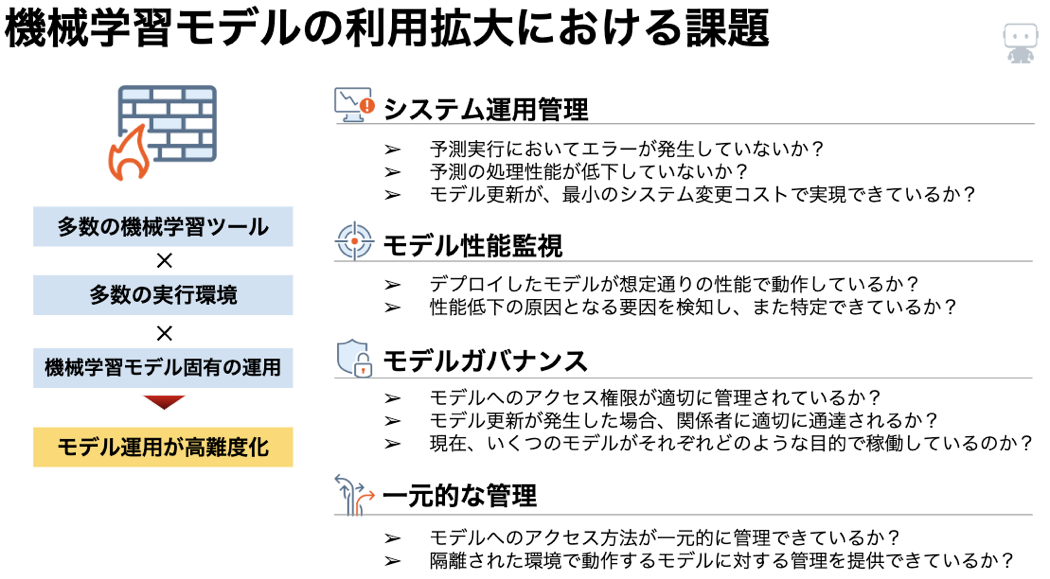
システム運用:
システム視点から「モデルがうまく動いているか」を定常監視する必要があります。予測実行時においてエラーがでていないか、といった確認はもちろん、処理スループットの低下、モデル切り替え時にはそのモデルを利用しているアプリケーション側の対応に問題がないか、といった点を観測していきます。
モデル性能監視:
機械学習モデルの視点から「うまく動いているか」を確認します。一般的なITシステムと異なった視点を持つ必要があり、代表的なものとしては、モデルを開発し、効果検証した時点から大きく予測性能が落ちていないか、その原因はなにかを観測していきます。
性能に問題が発生する代表的な要因としては、ビジネス状況の変化によるデータの変化、つまり、特徴量やターゲットの分布が、モデル作成時と比較して変化していく、といった現象があります。これを、まるで「データが流れ漂うよう」である事からデータドリフトと呼称します。
データドリフトの発生は、「いつごろから、どの程度、どの特徴量で発生していたのか」を時系列に沿った形で記録して置く事が重要です。それにより、ビジネス上での変化と付き合わせることができ、モデルをよりビジネスに沿ったものとして進化させていく上で非常に重要なインサイトとなっていきます。
ガバナンス:
ガバナンスは「統治」と和訳される事もあるように、「現在いくつのモデルが組織において稼働しているのか」「数多く予測に利用されている重要なモデルはどれなのか」といった稼働状況の把握から、「モデルは適切な利用者に限定されて利用されているか」「モデルが更新された場合、関係者へ適切な通知がなされているか」等を、組織横断的に把握する必要があります。また、監査証跡の観点からは変更前のモデルがどのようなものであったのか、といったモデルの世代管理についても、統合的に管理できる必要があります。
一元管理:
機械学習モデルが多く生成されていく過程の中で、個々のデータサイエンティストの得意とする技術(Python/R 等)や、目的に応じたライブラリの利用等で、単一のアーキテクチャではない技術を用いたモデルが増えていきます。しかし、そういった状況の中でも利用者に対しては同一のインタフェースで機械学習モデルへのアクセスを提供し、また上記に列挙したようなモデル運用監視を行う必要性には変わりありません。
また、非常に気密性が高いセキュリテイエリア等、モデルが配置される場所のネットワーク状況等も多様性に富んだものとなっていき、それらについての管理についても検討しておく必要があります。
MLOpsとは?
そこで、DevOpsの機械学習への発展という文脈で生まれたMLOpsという考え方が注目されています。
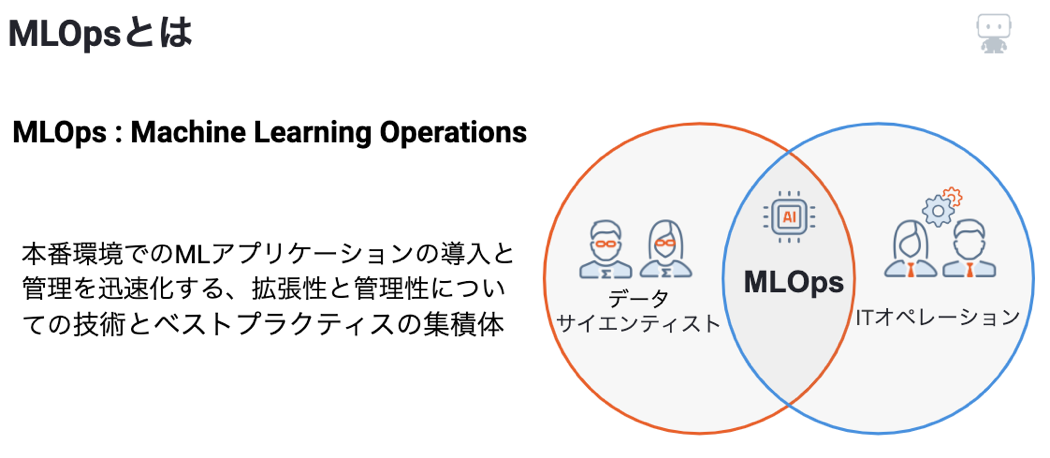
機械学習モデルの作成とデプロイを継続的・高速に行う仕組みと方法論を指しており、データサイエンティストの視点とIT運用者の視点を融合し実現する物となっています。モデルの構築を迅速かつ効率的に実現するのみならず、難易度が高くなり続ける高度なモデル運用の実現を目指す考え方です。
米国では昨年、MLOpsにフォーカスしたカンファレンスも実施されています。
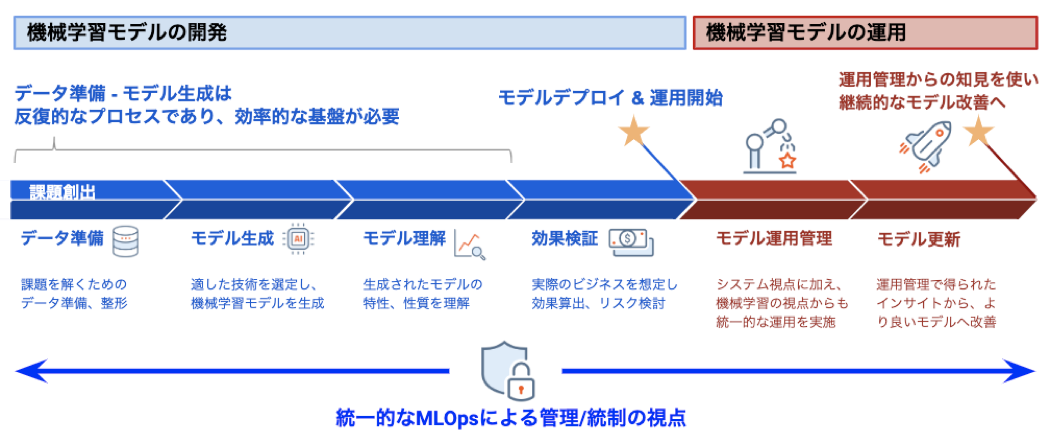
DevOpsがそうであったように、現状MLOpsもその前段に過ぎない機械学習モデルの開発の自動化への注目度が高いのが現状ですが、その後段として避けることができない、様々なアーキテクチャにより作成された機械学習モデルをどのように運用すべきか、という視点こそが重要です。
そこには前述したように多くのチャレンジが存在しますが、変わり続けるビジネス環境に適合し続ける機械学習モデルを実現するためには欠かせないプロセスとなります。このプロセス無しには、ビジネスに価値をもたらすはずの機械学習モデルが逆効果となってしまうことすら考えられます。
DataRobot が実現するMLOps
DataRobotはこれまで、機械学習モデル開発の自動化を業界最高のレベルで実現して来ました。
ユーザは分類、回帰、時系列、と様々な分析機能をそのビジネス課題に対し、単一のインタフェースで容易かつ迅速に実現し、ビジネスへのデプロイまでを統合的に実現する事ができます。
そしてDataRobotは2019年、ビジネスへの機械学習モデル適用におけるMLOpsの重要性から、この分野の先駆者であったParallelM社を買収し、その技術を機械学習モデルの自動開発プラットフォームに融合する事を開始しました。
これにより2020年、いよいよDataRobotは機械学習モデルの開発から運用までを統合的に管理するDataRobot MLOpsをリリースします。PythonやR等の個々の技術で作成されたモデル等も、実装アーキテクチャを吸収し組織横断の機械学習モデルの運用管理を実現していきます。
DataRobotの機械学習プラットフォームは、モデル生成の自動化、どれだけ高精度のモデルを生成できるか・・・といったレベルを超越し、真にビジネス環境で役に立つ統合環境を実現していきます。
DataRobot MLOpsの詳細については ブログPart 2 にてご紹介を進めてまいります!
また、今後このMLOpsについて先端事例から学ぶ勉強会をコミュニティで広げていきます。ぜひともこちらからご登録ください。イベントでお会いできる事を楽しみにしております!
MLOpsコミュニティ
DataRobotでは、製品に依存しないMLOpsコミュニティを運営しています。
活気のあるイベントを続々と企画していきます。どうぞこちらからご登録ください。

DataRobotデータサイエンティスト。システムインフラ全般、特に大規模 RDB 基盤に関する経験を保有。機械学習モデルの開発からビジネス適用に渡り技術的視座から支援を実施、また技術的トレーニングカリキュラムの開発を行っている。主に流通・小売・また通信業界のお客様に対する支援を担当。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事