デュアルリフトチャートとは
こんにちは、シバタアキラです。DataRobotには機械学習の自動化に加え、様々な方法でモデルを比較する方法が搭載されています。中には日本ではあまり馴染みのないものとして、リフトチャートなどもありますが、実は大変優れたモデル評価方法であるので、このブログが開設される前に、自分のブログにて記事化し、説明させていただきました。
今回は、そのリフトチャートを更にもう一段深く分析するための、デュアルリフトチャート(Dual Lift Chart)について解説します。またの名をダブルリフトチャート(Double Lift Chart)と呼びますが、いずれにしてもあまりオンライン上に文献がありません(検索するとシワ伸ばしの美容外科クリニックに)
リフトチャートおさらい
リフトチャートは、モデルの出力する予測値がどれくらいの判別能力や予知能力を有しているのか、また複数のモデルを比較した時に、どちらのモデルの精度が良いのかを素早く視覚的に捉えることができます。具体的には、予測値が大きいときに実際の結果が大きくなり、小さいときには結果も小さくなるという、予測値の有用性をシンプルな曲線で表してくれます。
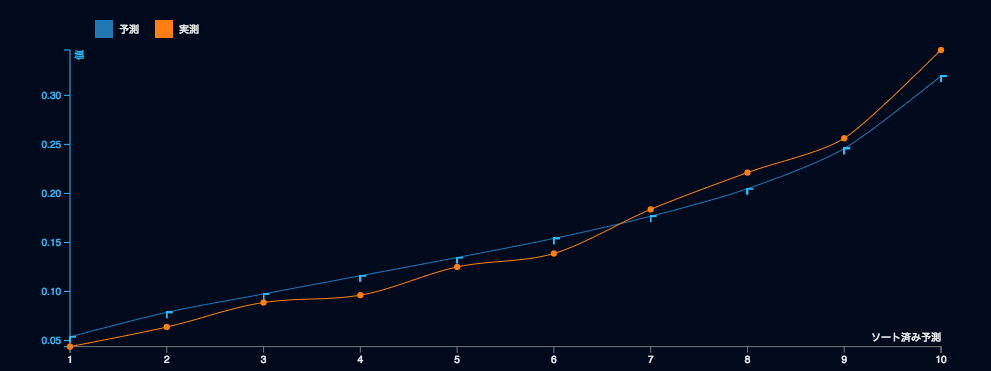
一般的には実測の曲線の角度が急であるほどよく、予測の曲線と近く交差していることが理想的なモデルです。
デュアルリフトは、2つのモデルを比べるためのもの
リフトチャートでは、一つのモデルを一つの線で表すことができるため、複数のモデルを簡単に比べることができます。しかし、2つのモデルが似ているときには比較がしにくくなる問題が有ります。例えばこの2つのモデルを比べてみましょう
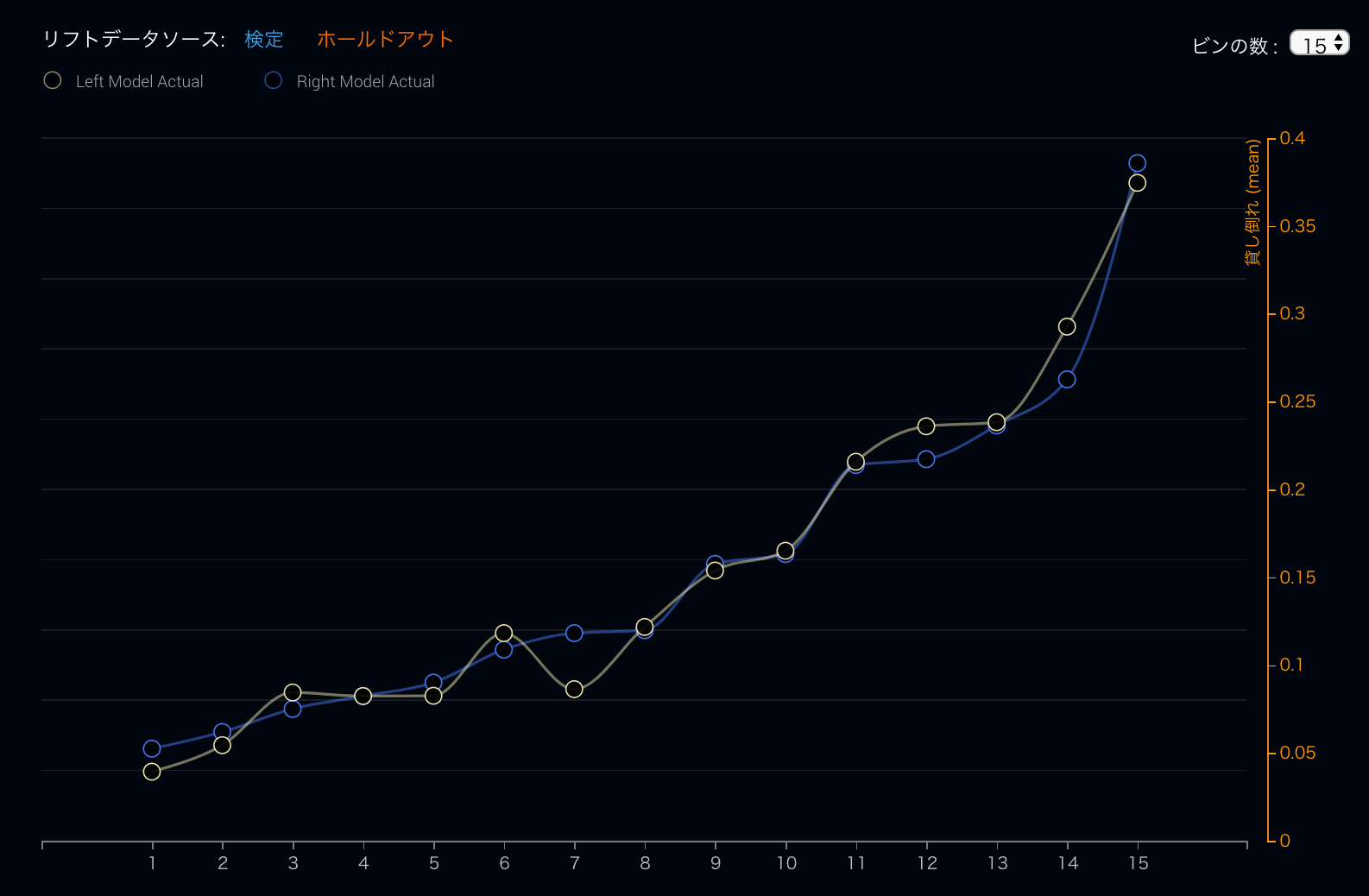
AUCでも0.68と0.69の違いしかなく、非常に近い2つのモデルのため、ここから多くを語ることはあまりできません。「2つのモデルは似ている」くらいの結論でしょう。
デュアルリフトの作り方
ここで下記の手順でデュアルリフトチャートの作成を行います
- 2つのモデルによって計算された予測値A(白い線のモデル)とB(青い線のモデル)があったとき、A/Bの値を計算する
- リフトチャートを作るときと同様に、A/Bの値で全体を並べ替え、各ビンに同じレコード数が入るよう等分する
- A/Bの小さいビンから並べ、ビンごとに、予測値Aの平均、予測値Bの平均及び実測値の平均を計算する
そうして完成したのがこのデュアルリフトチャートです。
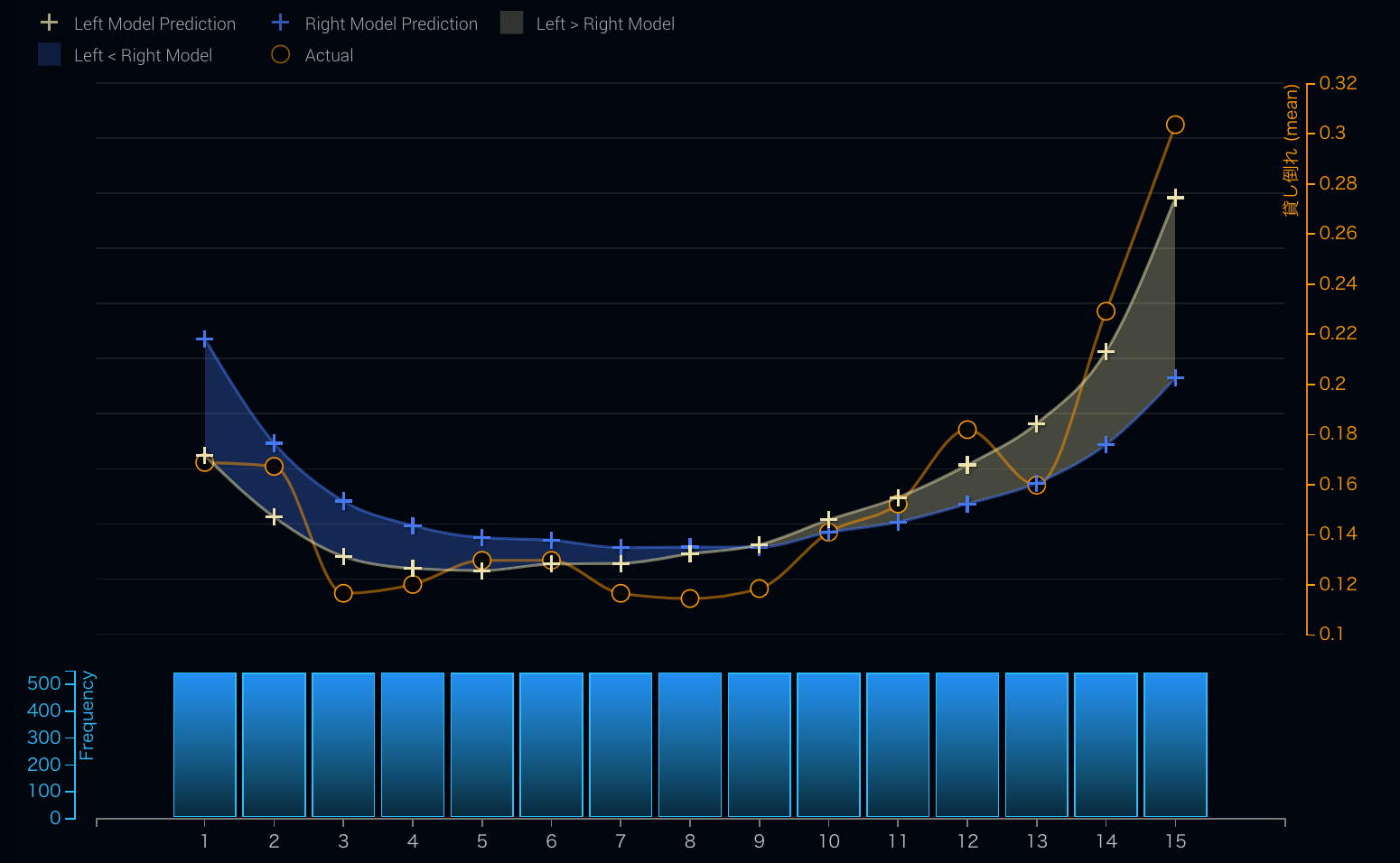
チャートの真ん中付近においては2つのモデルの予測値がほぼ同じであるため、2つのモデルの曲線が交差します。左右の端においては、2つのモデルの予測結果の差が大きくなり、左側においては青のモデルのほうが高い予測値、右側では白のモデルが高い予測値を出しています。リフトチャートでは見えなかった2つのモデルの違いがよりはっきり見えます。そして、オレンジの線で表されているのが実測値です。
これにより、先程は見にくかった2つのモデルの違いを定量的に分析することができます。例えば、2つのモデルが一番ずれている右のビンにおいては、予測値が40%ほど(0.28と0.2)ずれていて、白い線のモデルのほうが実測に圧倒的に近いなどです。
新旧モデルの比較による、さらなるインサイト
デュアルリフトと、2つのリフチャートの比較との違いは、両方のモデルの結果を一つの指標で並び替えたため、各ビンにおいて計算される3つの値はすべて同じレコード群から計算されています。今回のデータでは、貸し倒れを予測していますが、例えば青い線のモデルが過去に使われていたモデル、白い線はこれから導入を検討しているモデルだとしたときに、
- 過去のモデルにおいては、貸し倒れ率を50%も低く見積もっていた領域がある(右のビン)
- この領域のローンに対しては損害が出ていたと考えられる
- 過去のモデルにおいては、貸し倒れ率を20%も高く見積もっていた領域がある(左のビン)
- この領域のローンに対しては利率を高く設定しすぎていた可能性がある
- いずれの場合も新しいモデルのほうが実測値(ホールド・アウトデータでの)に近づいている
といった新しいインサイトを得ることができるのです。
以上、簡単でしたがデュアルリフトチャートの作り方と使い方でした。実際には2つのモデルを比べるだけならば、検定値のAUCで十分ということもあるかもしれないですが、素早く上記のようなインサイトを得ることができるのは時として分析のサイクルをスピードアップしてくれるでしょう。

DataRobot Japan チーフ・データサイエンティスト。ロンドン大学高エネルギー物理学博士課程修了。ニューヨーク大学でのポスドク研究員時代に加速器データの統計モデル構築を行い「神の素粒子」ヒッグスボゾン発見に貢献。その後ボストン・コンサルティング・グループでコンサルタントとして、主に TMT/製薬業界でのデータ分析業務に従事。AI 型情報キュレーションを提供する白ヤギコーポレーションの創業者兼 CEO を経て2015年に DataRobot Japan の立ち上げに一人目のメンバーとして加わり現職。個人ブログにhttps://ashibata.com/、共著に「データ活用実践教室」(日経BP社)など
直近の注目記事
AI活用を成功に導く方法をサービス商品化した米AIベンチャーの狙い(ZDNet Japan)
シバタアキラ氏が伝授#01/データサイエンスって何?(日経ビジネスONLINE)
この人にはこれが売れる/実践!データサイエンス#09(日経ビジネスONLINE)
データサイエンティストになるには?社内で育てる方法は?わかりやすく解説(ビジネス+IT)
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事