DataRobot 6.0の新機能
2020年4月23日に、DataRobot の最新バージョンである6.0の日本語版がリリースされました。6.0ではモデル作成自動化の進化はもちろんですが、モデル作成だけでなくデータ準備からモデル利用まで「AI/機械学習のプロセスをエンドツーエンドで自動化する」ための重要な新機能がいくつも登場し、大きなマイルストーンとなるバージョンになりました。このブログではそのハイライトをご紹介します。
Visual Artificial Intelligence(AI)
機械学習モデルで使用する特徴量といえば、数値データや文字列データなどを用いることが一般的ですが、予測したい対象が必ずしもそうしたデータだけで説明できるとは限りません。数値や文字列以外のフォーマットで保存されたデータにモデルの精度を高めるシグナルが眠っている、そう考えたことはありませんか?
その代表的な例の一つが画像データです。画像には構造化データでは表現できない多様な情報が眠っています。商品価格を推定するために商品画像を用いたい、不良品予測のために製品画像を用いたい、疾病予測のために診断画像を用いたい、など多様な活用テーマを想像できるのではないでしょうか。
バージョン6.0で DataRobot は Visual Artificial Intelligence(AI)の提供を開始しました。Visual Artificial Intelligence(AI)は画像データを用いたモデリングを自動化することができる画期的な新機能です。Visual Artificial Intelligence(AI)では画像データをあらゆるモデルの精度向上に用いることができます。例えば次の例では、物件の価格を予測するために物件の写真を特徴量の1つとして使っています。
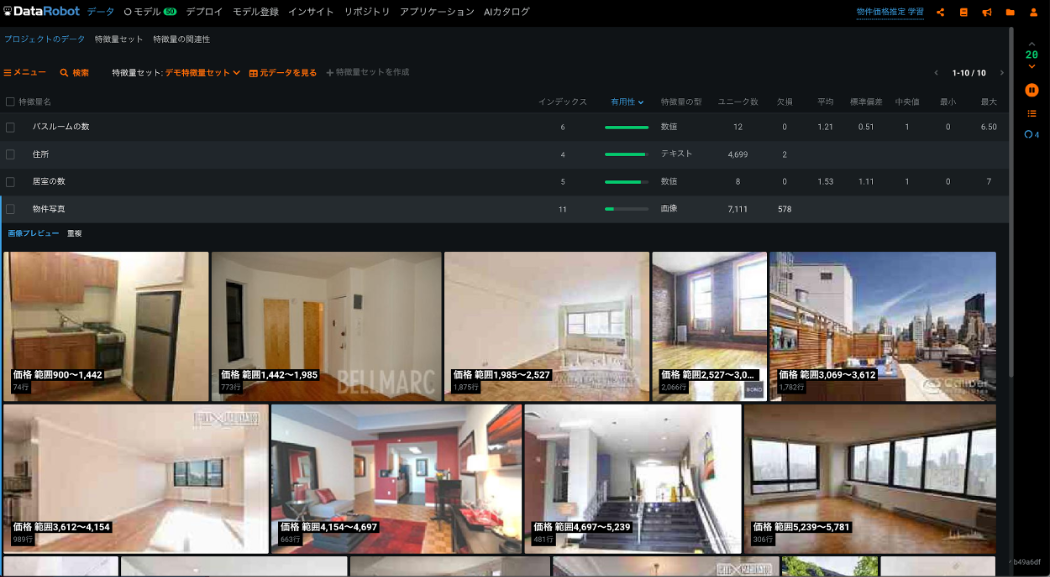
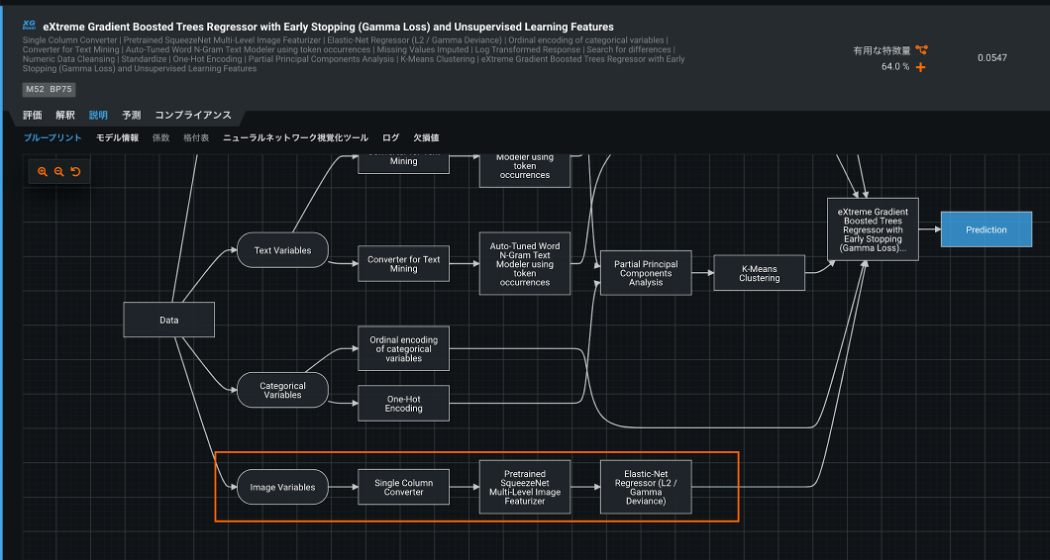
通常、画像を特徴量として扱うにはニューラルネットに関する知識と技術が求められます。大量の学習データと計算リソースも必要で、とても誰もができることではありません。DataRobot では VVisual Artificial Intelligence により画像の特徴量化が自動化されているため、誰でも簡単に何度でも、数値やテキストなどと画像を組み合わせたマルチモーダルなモデリングを実現できます。下図では、データ(左端)から画像データが自動で特徴量に変換され、モデルに利用される様子がわかります。
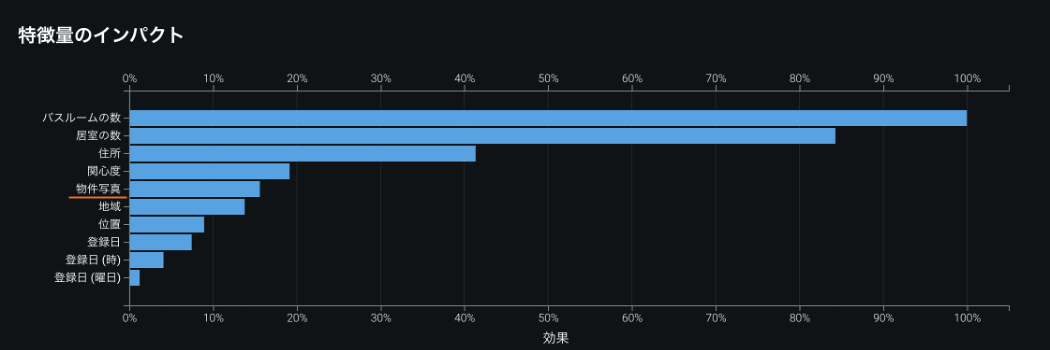
画像データは DataRobot の特徴量のしくみに完全に統合されているため、これまでとまったく同じ操作で同じように分析ができます。以下の例では、物件写真が物件価格の予測に与えるインパクトを他の特徴量と比べており、物件写真のインパクトは最大ではないものの、重要な特徴量の一つであることがわかります。
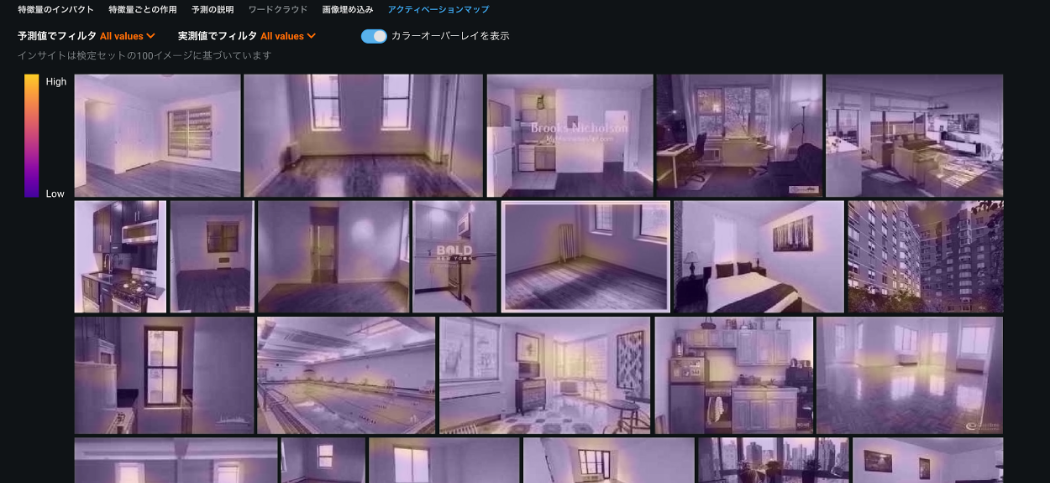
また、画像を用いてただ精度が上がったというだけではだめで、実際に運用するには「AI の説明性」も求められます。Visual Artificial Intelligence(AI)では画像特徴量の性質を説明する機能も提供されており、画像と予測との関係が人間の経験や知識と照らし合わせて納得のいくものであるか確認することができます。例えば下図では、物件写真のどの部分に着目して物件価格を予測しているかがわかります。これが人間の着目する箇所と類似していれば、そのモデルの信頼性も高まるでしょう。
DataRobot へ画像データのアップロード方法はとても簡単です。プロジェクトデータ(CSVファイル)中にそれぞれの行データに対応する画像ファイルへの相対パスを記入した列を用意し、参照先の画像ファイルと一緒に zip で一つのファイルにまとめ、あとはドラッグアンドドロップや AI カタログを通じて DataRobot にアップロードするだけです。
皆さんはどのような活用テーマで画像を使ってみたいですか?
エンドツーエンドでの自動化
DataRobot は「機械学習の自動化」を掲げてビジネスをスタートしましたが、モデル作成や評価、デプロイを自動化しただけでは真の AI 民主化は達成できないことも同時に学んできました。そこで近年の DataRobot は、モデル作成より前のフェーズ(データ管理やデータ準備)と、モデル作成より後のフェーズ(モデル運用やモデル利用)も自動化に加えることで、誰もがデータから価値を得るまでのプロセスをエンドツーエンドで自動化できるよう開発に取り組んできました。
バージョン6.0では前述の Visual Artificial Intelligence(AI)に加え、この「エンドツーエンドでの自動化」のビジョンを具体化する重要な新機能が3つ登場しています。以下ではこれらについてご紹介します。
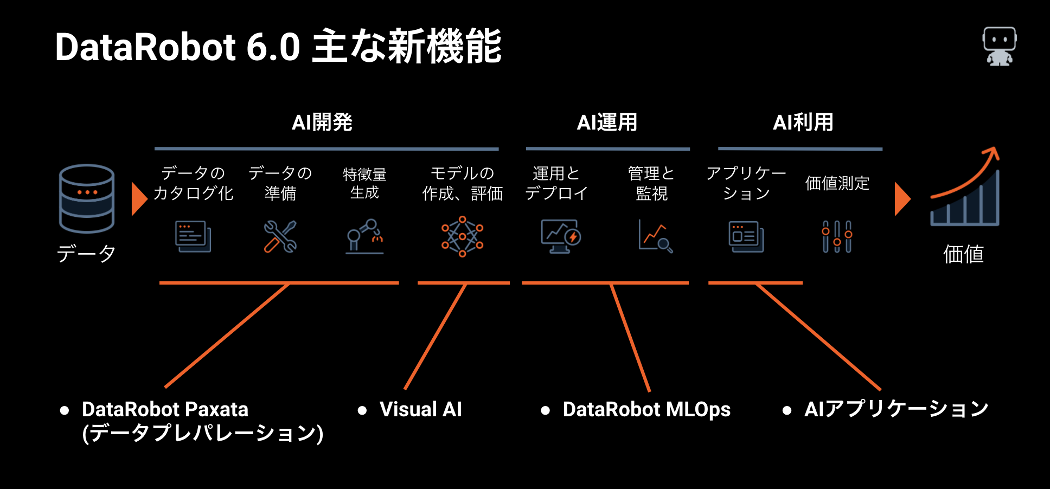
DataRobot Paxata (データプレパレーション)
DataRobot は従来から特徴量エンジニアリングを自動化しており、さらにバージョン5.3では自動特徴量探索の導入により複数のデータセットの結合・集計による特徴量の生成も自動化できるようになりました。
しかし、機械学習のためのデータ準備作業は機械的に自動化できるものばかりではありません。人の判断が必要なデータ修正や、業界・業務知識が必要な特徴量エンジニアリングもあります。一方、そのような作業は誰でも簡単にできるわけではありません。
そんな、AI/機械学習のためのデータ準備作業の課題を解決するのが DataRobot Paxata です。DataRobot Paxata ではスプレッドシートに似たわかりやすいインターフェースで、誰でも簡単にインテリジェントなデータ準備を行うことができます。2019年11月に DataRobot 社が Paxata 社を買収した後、すでに DataRobot とのインテグレーションも利用可能になっています。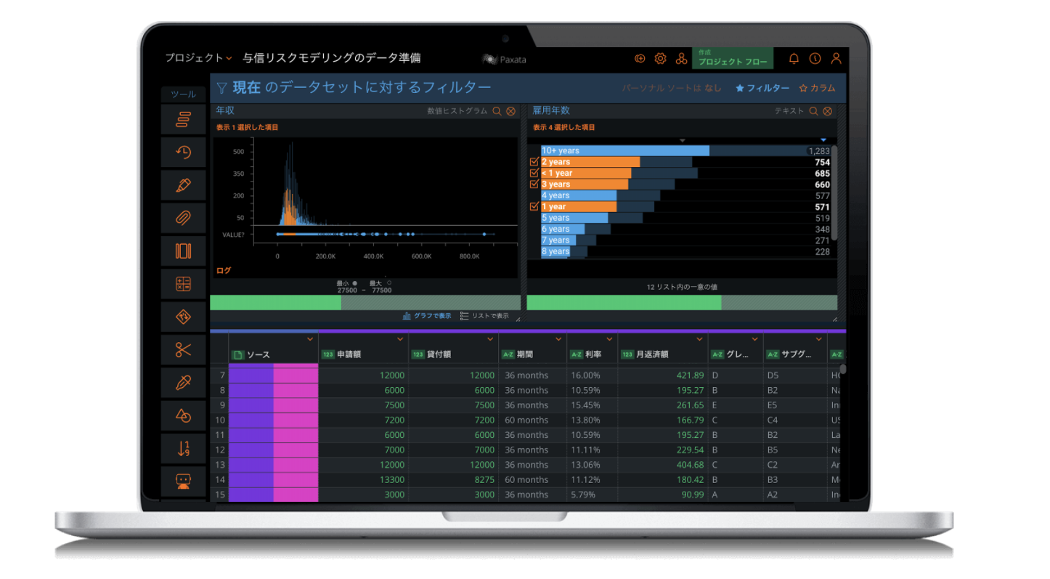
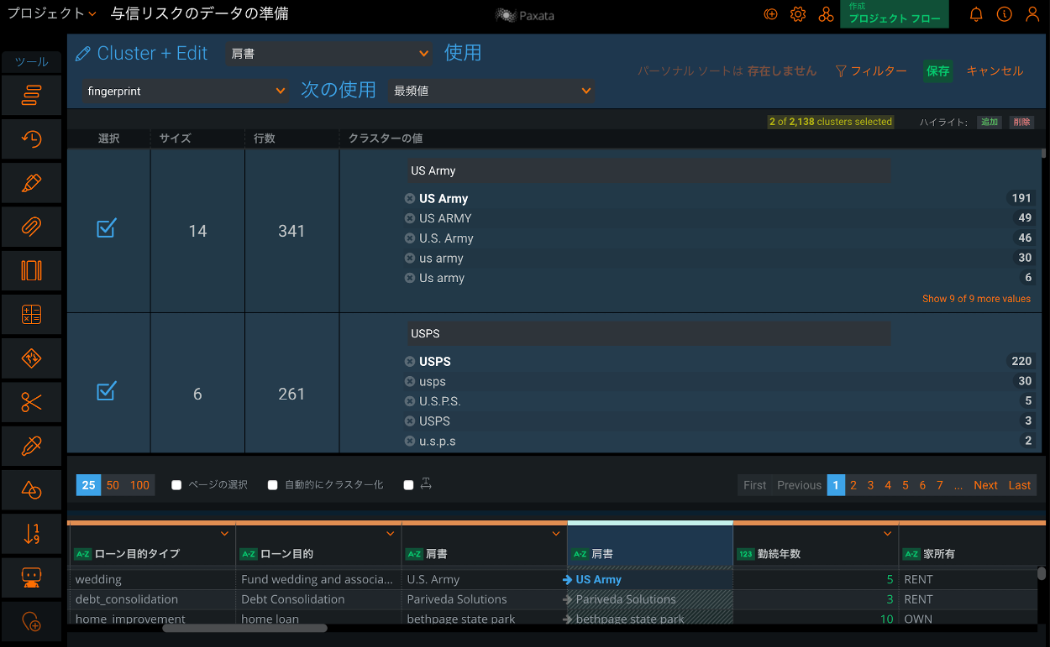
DataRobot Paxata の特徴の一つは、インテリジェントなデータ準備機能を手軽に使えることです。例えば「名寄せ」はとても手間がかかるデータ準備作業の一つですが、DataRobot Paxata ではワンクリックで列内の似たデータを検出し、統一することができます。検出アルゴリズムは複数あるため、各業務の要件に応じた標準化を実施できます。下記の例では、「肩書」列の中にあるさまざまな「US Army(米国陸軍)」や「USPS(郵便公社)」の表記を自動で統一しています。
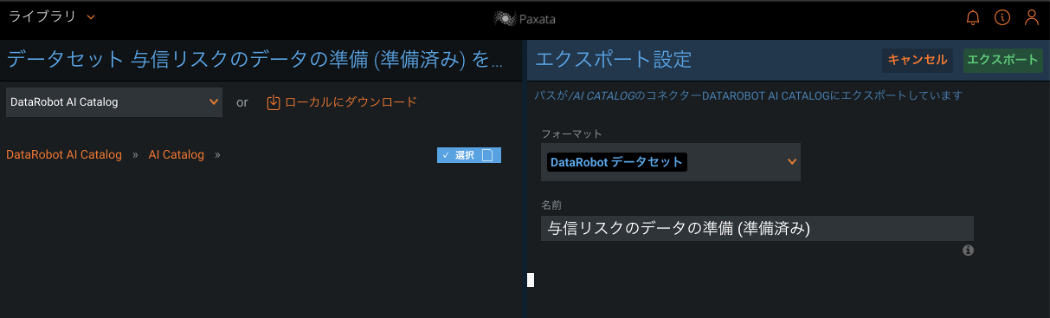
AI/機械学習用に準備のできたデータは、モデル作成や予測のプロセスと迅速につながる必要があります。DataRobot Paxata ではすでに DataRobot との連携機能が提供されており、数クリックで準備済み学習データを DataRobot に送ってモデリングを始めたり、予測用データを送って DataRobot から予測結果を取得、書き戻したりすることができます。
下記の例は、与信リスク判定モデルのために DataRobot Paxata で準備したデータを DataRobot の AI カタログにエクスポートし、DataRobot でプロジェクトを作成してモデリングを始めようとしているところです。
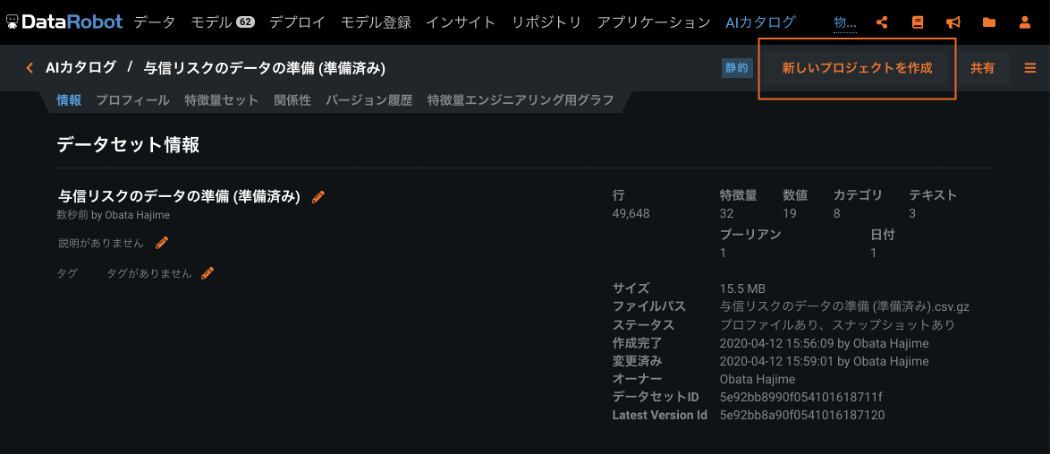
DataRobot ML Ops
組織内で機械学習モデルの利用が広まると、DataRobot 以外のプラットフォームで作られたモデルを扱うようになることもあるでしょう。単にさまざまなツールでモデルが作られるというだけでなく、例えば明確な説明性を目的として、DataRobot で得たインサイトをもとに Python で線形のモデルを再構築する、というケースなどもあります。
そうしたモデルを運用するには、モデルごとに利用するための API や監視のしくみを作る必要がありますが、これは簡単なことではありません。もし統一的なしくみを用意できなければ「野良モデル」が発生し、利用用途も、その精度もわからないままビジネス判断に影響を与え続けてしまうでしょう。
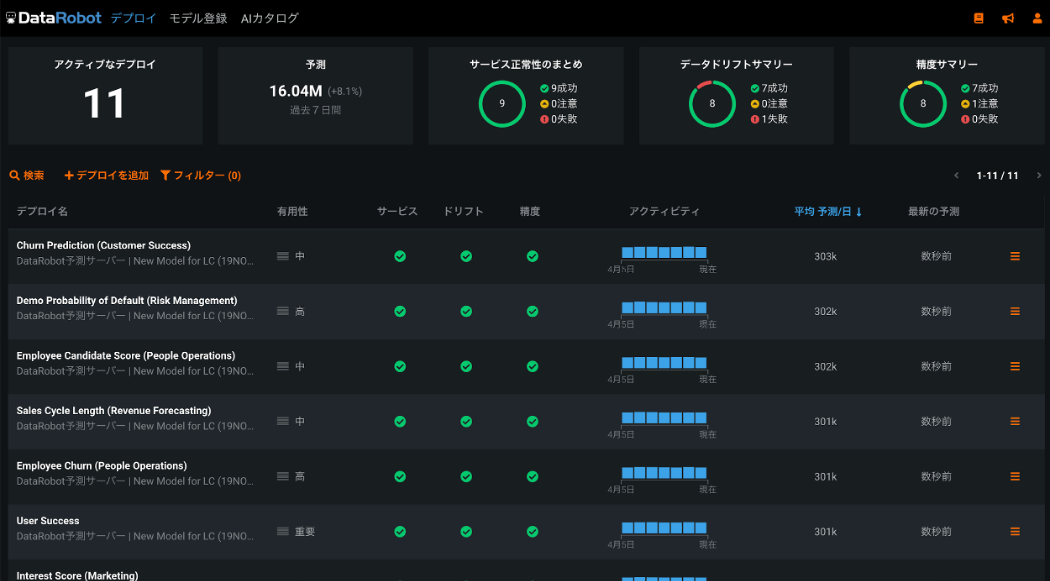
DataRobot ML Ops はこうした問題を解決するため、DataRobot で開発されたモデルだけでなく、さまざまな環境で開発されたモデルに対して統一された利用・運用機能を提供します。監視のしくみを新たに作り込む必要はありません。統一された API を自動で作成でき、一つのダッシュボードで精度などモデルの運用に必要なポイントを統一的に監視することができます。
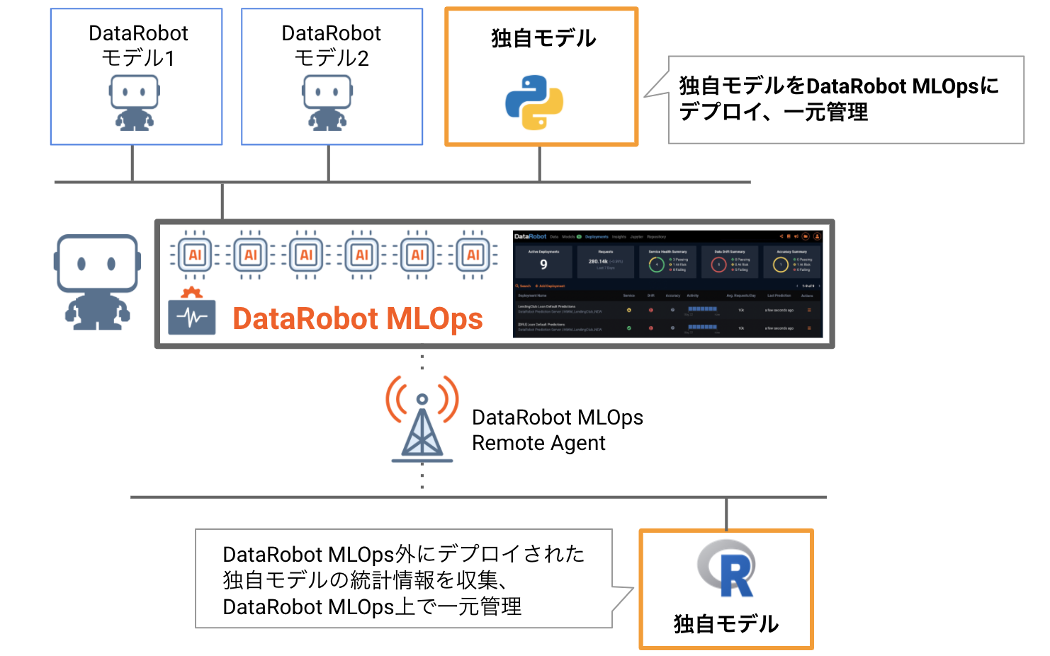
DataRobot ML Opsでは、DataRobotで 作られたモデルと DataRobot 以外のプラットフォームで作られたモデル(下図では「独自モデル」と表記)の双方を運用できます。独自モデルは DataRobot ML Ops にデプロイして API 作成や監視を自動化したり、DataRobot の外でデプロイされている独自モデルであればリモートで監視することもできます。
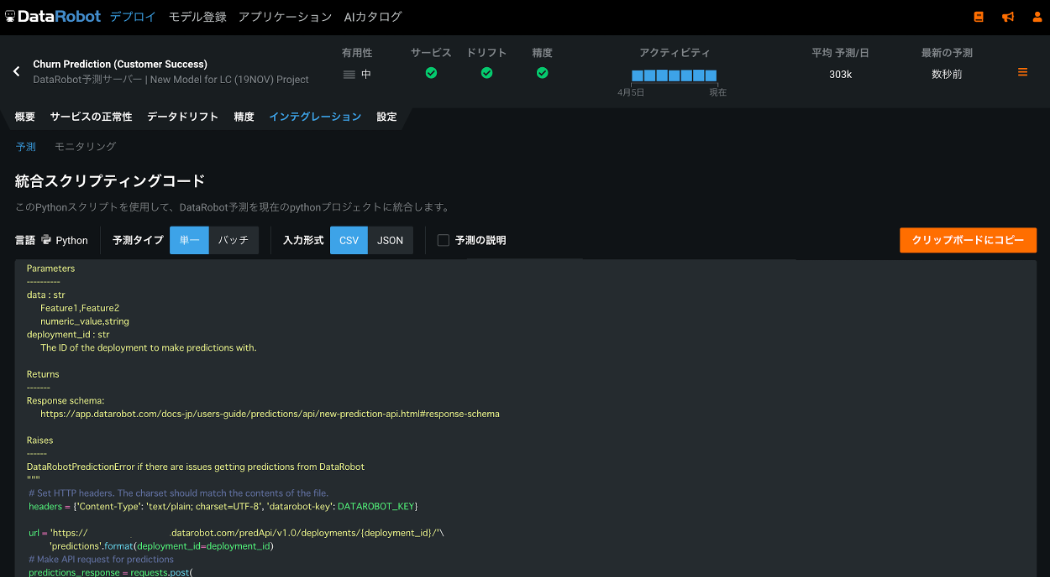
DataRobot ML Ops に独自モデルをデプロイするだけで、標準化された API が自動で作成されます。その API を呼び出すサンプルスクリプト(下図)も自動で作成されるので、開発者はどんなモデルであれ標準化された API を使ってシステムインテグレーションをすぐに始めることができます。
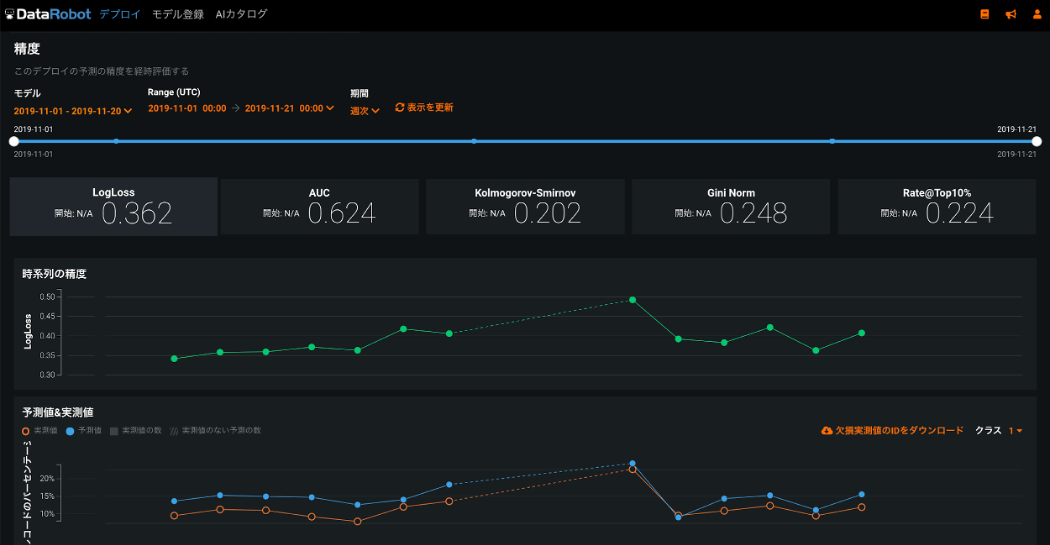
独自モデルに対しても DataRobot モデルと同じように精度の監視をサポートしています。予測値は DataRobot ML Opsによって自動的にトラックされ、実績値をアップロードすることで精度の劣化を検出・通知できます。モデルの置換にも対応しており、置換前後で精度が劣化していないかを確認するもの簡単です。
AI アプリケーション
ここまでの新機能は程度の差はあれ、モデルの「作り手」へ向けたものでした。そして、機械学習自動化に関する世の中の製品の多くは、作り手へ向けた機能を提供することに注力しています。
しかし AI の民主化を進めるには、作り手だけでなく AI の「使い手」によって価値が認められなければなりません。使う側、つまり必ずしもデータサイエンスに馴染みのないビジネスユーザーがわかりやすくその価値を理解するには、誰かがわかりやすいアプリケーションを開発しモデルをインテグレーションしなければなりませんが、それに気軽に取り組める組織は多くないでしょう。
DataRobot の AI アプリケーションは、モデルを利用したアプリケーションの作成を自動化することでこのラストワンマイルともいえる部分を実現する、まったく新しい発想の機能です。現在、目的別の3種類のアプリケーションが提供されており、それぞれ使用するデプロイ済みモデルを指定するだけで自動的にアプリケーションが作成されます。
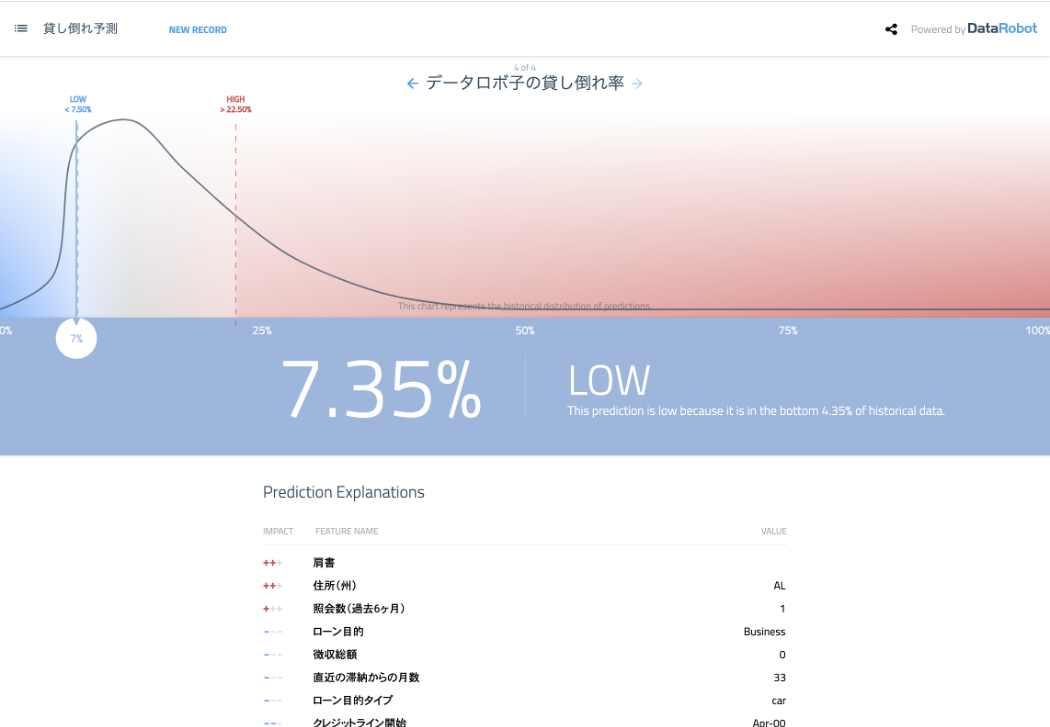
「予測実行」アプリケーションは最もシンプルなアプリケーションで、特徴量の値を指定してモデルの予測結果や予測の説明を得ることができます。
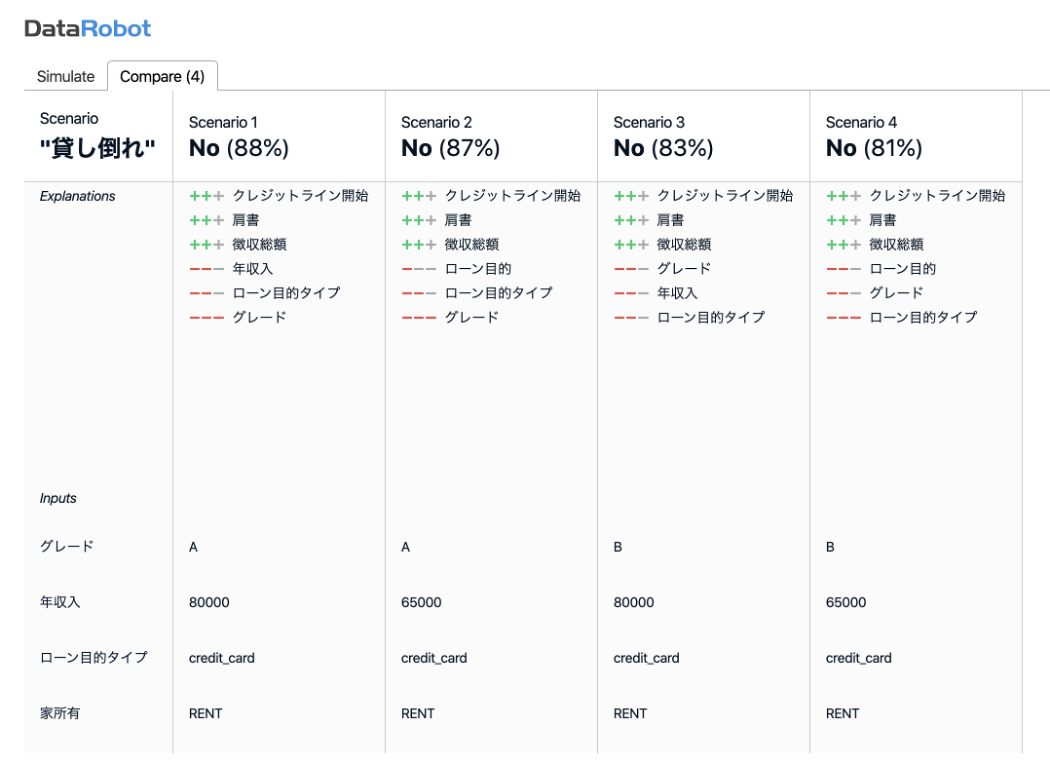
What-If アプリケーションは、特徴量の値を少しずつ変えながら予測値の変化を比較したい場合に便利です。下記の例では、貸し倒れ予測モデルを使った What-If アプリケーションにより、グレードと年収入の違いによる貸し倒れ率の変化をシミュレーションしています。
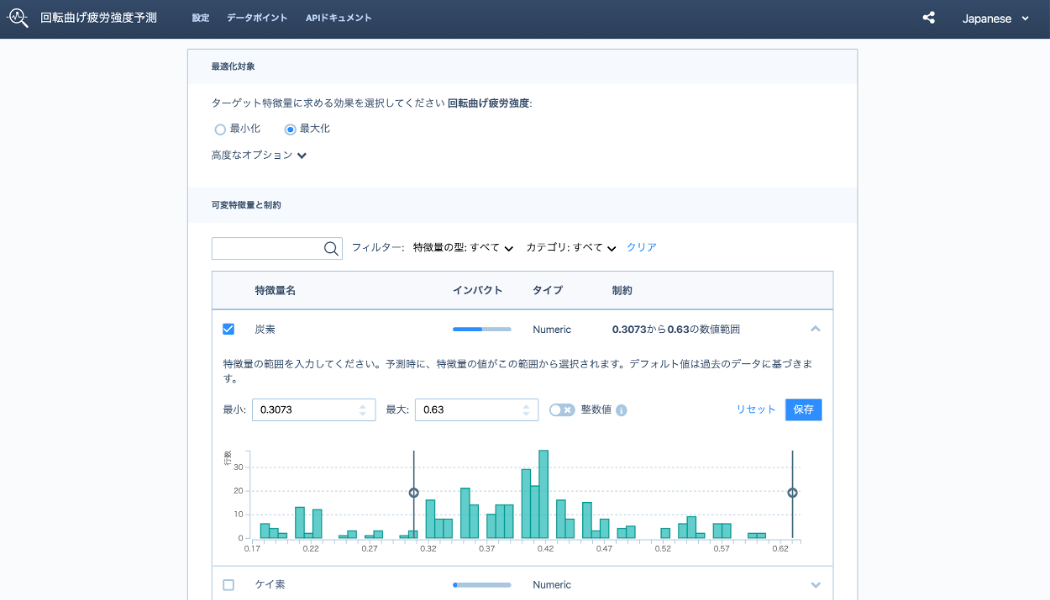
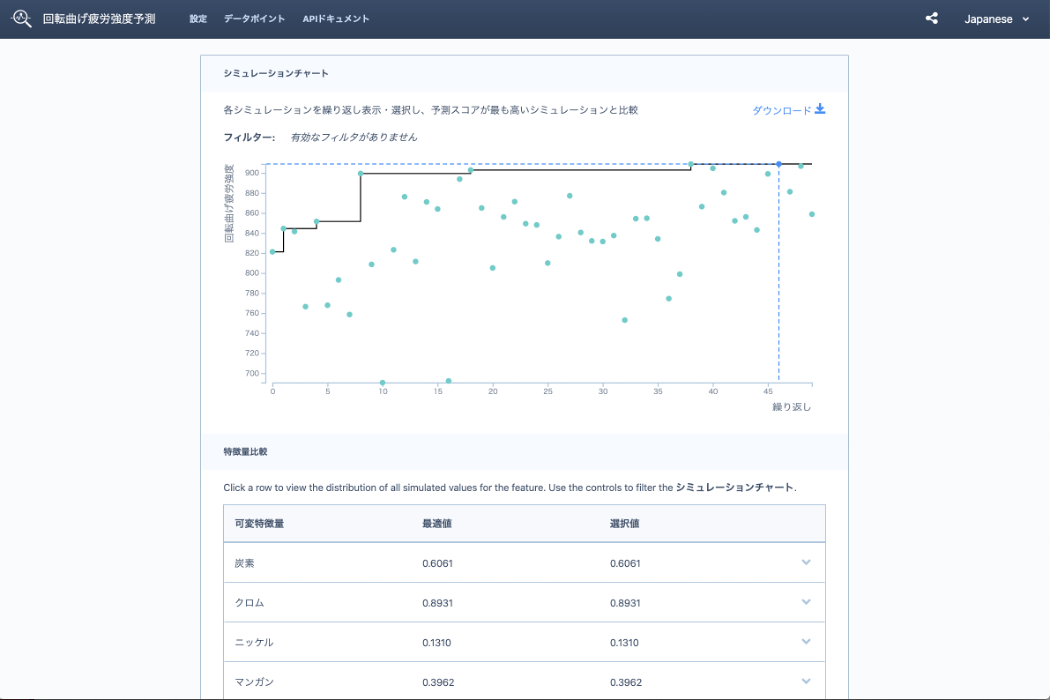
「最適化」アプリケーションは、予測値を最大化または最小化するためにさまざまな入力値のパターンを探索するプロセス(逆問題とも呼ばれます)を自動化し、最適な入力値の組み合わせを発見します。以下の例では鉄の強度予測モデルを使用し、強度を最大化する原料の配合比を探索しています。
おわりに
いかがでしたでしょうか。Automated Machine Learning(AutoML)という概念が登場して久しいですが、DataRobot は AI の民主化にあたって、機械学習モデルの作成や解釈を自動化しただけでは解決することができない課題に直面してきました。まだ誰も乗り越えたことのないその山を越えるために DataRobot が開発してきたものの一つが AIサクセス であり、そしてもう一つがこのブログでご紹介したエンドツーエンドのプロセスを自動化する製品です。
もはや DataRobot は AutoML だけの会社・製品ではないといえるでしょう。すでに DataRobot は従来のいかなる AutoML の概念も超えた広範囲の自動化を進めています。しかし、バージョン6.0はエンドツーエンドの姿が具体化された最初のリリースであり、これで終わりではありません。今後の進化にもどうぞご期待ください。

DataRobot プロダクトマネージャー。2018年から DataRobot に参加。DataRobot 製品に関するフィードバック収集と新規開発計画への反映、新機能・新製品のベータプログラムやローンチ、トレーニングやマーケティングを通じた普及活動、ローカライゼーション管理、などを通じて、AI と DataRobot の価値を日本に広く広めるための業務に従事。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事