
AI を用いた新商品需要予測
新商品需要予測における課題
サプライチェーンを改善するに当たり、正確な需要予測は1つの重要なポイントです1。その中でも食品・消費財メーカーやアパレル業界では新商品の需要予測は非常に大きな課題となっています。例えば、「在庫廃棄のうち3割は新商品の予測ミス」(A社)、「在庫廃棄の原因のうち最も大きいのは新商品の予測ミス」(B社)の様な現状が複数の CPG メーカーから報告されています2。毎シーズン新作品がリリースされるアパレル業界でも、三陽商会が建値消化率(「正価」販売率)45%、総消化率70%という状況にある様に、3割もの商品が売れ残っています。この問題の原因の1つもシーズン前に新作品の需要を正しく見極め、生産を行えていない事にあると思われます。
同様の結果は弊社が行ったウェビナー参加者へのアンケートからもわかります。下図1にある様に、新商品需要予測の精度が悪いという課題が60%以上を締め、最大の課題となりました。
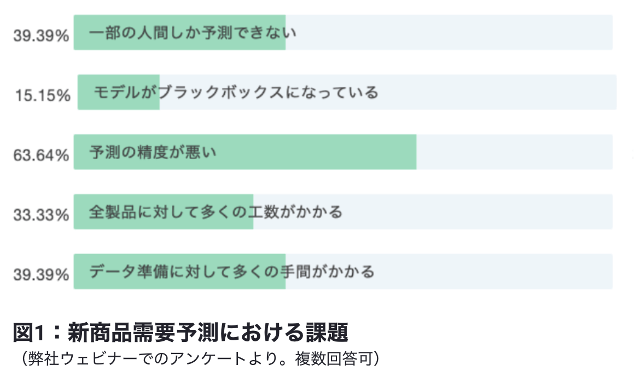
一方で下図2にある様に、現状の新商品の需要予測は、50%以上の企業で営業担当の感覚や経験に基づいた予測で行われています。この傾向は一般的な需要予測テーマの中でも新商品で特に顕著で、実際に我々が会話を行った CPG のお客様でも、過去の売上データが存在する定番品については簡単な統計的手法で当てる事ができるが、過去の売上データが存在しない新商品では現場の感覚に頼る以外に無く精度が出ていない、あるいはどの様に改善できるか分からず全く手を付けられていないという声がよく聞かれました。

人間による予測にはどうしてもバイアスが存在します。例えば、営業担当者は得意先への欠品を恐れ過剰な見通しの数字を出しがちです。また需要に影響を及ぼす無数の要素を人間が正確に考慮して、複雑なパターンを見極め、予測を行う事は例え熟練者であっても難しいのが実情です。
しかし、データサイエンスの進歩と共に、AI の技術を使った新商品需要予測の利用が始まっており、資生堂様の事例にある様に、上記の課題を乗り越えた事例も報告されています。モデリング技術の進歩により数値やカテゴリデータのみならず、テキスト、画像、地理空間情報データなど多様な型の多数の特徴量(AI で予測を行うために利用される変数)を考慮し、より高精度な AI 予測を行う事が可能になりました。つまり過去に上市した自社の新商品の販売実績だけでなく、パッケージングや外観の画像データ、研究開発データ、小売パネルデータ、SNS のテキストデータを含めた外部データなどの多くの特徴量から、複雑なパターンを学習し、正確な予測を行う事ができる技術が現実のものとなってきています。
本ブログでは、まず AI を使った新商品の需要予測のプロセスを説明します。次に、新商品の需要予測で気をつけなければいけないポイントを解説します。
AI を使った新製品需要予測のプロセス
需要予測の目的の明確化
新商品の需要予測を行う前に、まず『需要予測を行う要件』を明確にする必要があります。要件には大きく分けて以下の3つがあります。
- 予測の目的(何のために予測するか)
- 予測ポイント(例:発売の Xヶ月前に予測)
- 予測対象(例:SKU ごとの上市後 X週間の総需要を予測)
目的は、この記事を読んでおられる需要予測に関わっている方からすると自明でしょう。例えば、商品開発を行っている方であれば、商品の機能/質とコストを考慮して利益を最大化する、SCM 担当の方であれば、正確な需要計画を策定して適正な調達計画や生産計画につなげるという事になるでしょう。
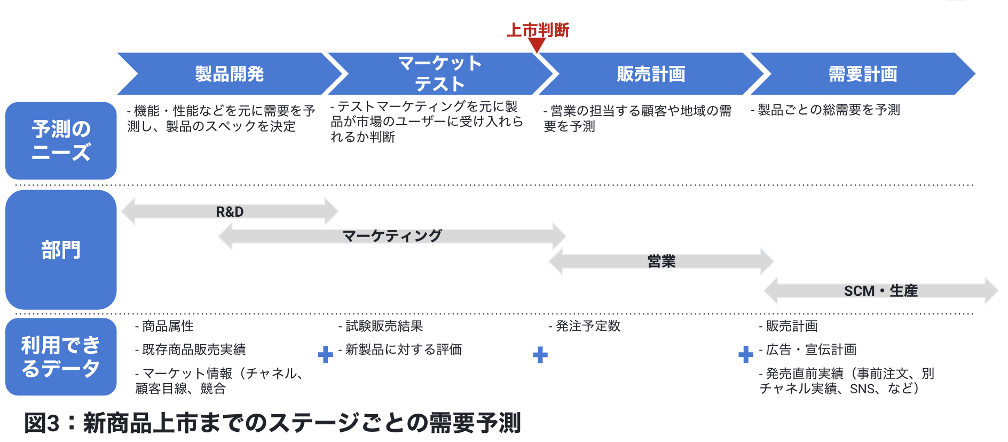
2つ目の要件「予測ポイント」は、予測の目的から自然と決まってくる事がほとんどです。もちろん上市タイミングよりも前もって予測できればできるほど良いですが、予測する時点が早ければ早いほど予測の精度も下がってくる場合がほとんどです。そこで調達や生産のリードタイムなどを考慮した上で許す限り遅らせて予測は行われます。
また、この予測ポイントに従って予測に使える情報が変わってくるため、モデリングを行うデータ収集のプロセスに大きな影響を及ぼします。新商品の需要予測では、需要量の原因となる事象がどれだけデータとして利用できるかが予測の精度に直結します。上図3の商品開発の時点での予測であれば、まだ大まかな商品属性情報しか予測に利用できませんが、需要計画の時点では、新商品の価格や広告予算、上市時により近い時点のマーケットの状況など売上を左右する他の多くの要素を考慮した予測モデルを作成できるため、より精度の高い需要予測を行える事が多いです。
最後に、どの様な粒度(日/週/月次、顧客/支店/統括支店/全体)の予測を行うか「予測対象」の選定も重要です。一般的には大きな粒度の予測(月次、全体)になればなるほど簡単で、細かい粒度(日次、顧客単位)になればなるほど難しくなります。ビジネス側の立場からすると、理想としては日次の顧客単位の上市後の需要が正確にわかるのが一番良いのは自明です。しかし、人が行ってきた既存のプロセスに縛られず、需要予測精度への影響も考慮しながら、ビジネスを行うために最低限必要な大きさの粒度で予測を行うべきです。
データの準備とモデリング
新商品需要予測に使えるデータは、前のパートで決定した『需要予測の要件』で自然と決まります。需要に影響を及ぼす可能性があり、利用可能なデータをリストアップした後、精度の高いAIモデルを生成するために、以下の3つのステップで進めていきます。
- モデリングに適したデータセットの生成(特徴量エンジニアリング)
- モデリング
- 不要な特徴量の取捨選択
機械学習のモデリングを行う時には、特徴量エンジニアリングと呼ばれるモデリングに適した変数をデータから作成する作業が非常に重要です。以下に主要な理由2つを列記します。
- 単に収集した素のデータを使ってモデリングするのではなく、より予測にダイレクトに関係する特徴量を作る事でモデルの精度が向上します。例えば人間は単に気温だけでなく、湿度や風の有無でも暑さの感じ方が異なります。つまり、単に気温を使うのではなく、体感気温を使うというのも特徴量エンジニアリングの1つです。
- 新商品需要予測のモデルを生成するには、1つの商品が1行として表されるデータが必要です。しかし新商品の全国の総需要を予測する際、POS データや気温データなどは、1商品に対して複数存在します。そこで複数行のデータを集約し商品に特徴付けるデータとする必要があります。例えば全国の総需要予測で気温を使う場合、地域で異なった気温が存在します(1商品に対して複数のデータ)。そこで「全国の最低気温」、「最高気温」、「平均気温」、あるいは「人口で重みづけした平均気温」など様々な「1商品を特徴付けるデータ」に集約します。これも特徴量エンジニアリングの一種です。
特徴量エンジニアリングのアプローチは大きく分けて2つに大別されます。
- 機械的なアプローチ:1対複数のデータを様々な粒度や期間で集約した特徴量や、特徴量間の差や比など、複数の特徴量を組み合わせた新たな特徴量を機械的に生成し、その中から重要な変数を探索する
- ビジネスナレッジに基づいたアプローチ:現場熟練担当者の経験・ナレッジに基づいて、需要への影響が大きい要素を特定し、特徴量とする。先ほどの体感気温もビジネスナレッジに基づいたアプローチです。
DataRobot では上記のそれぞれのアプローチをサポートする機能/商品を用意しています。
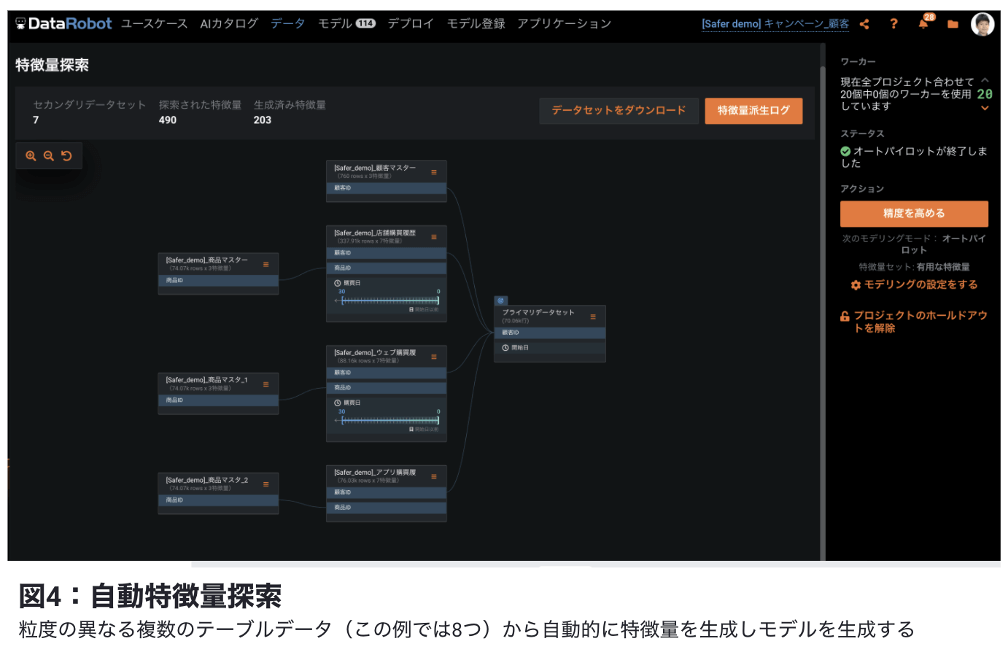
- 自動特徴量生成:複数のデータセット間の関係性を指定する事で、複数のテーブルを自動的に集約し、特徴量エンジニアリングを行い、モデルを生成します。また単一データソースからも予測に有用な相互作用項を探索する事も可能です。
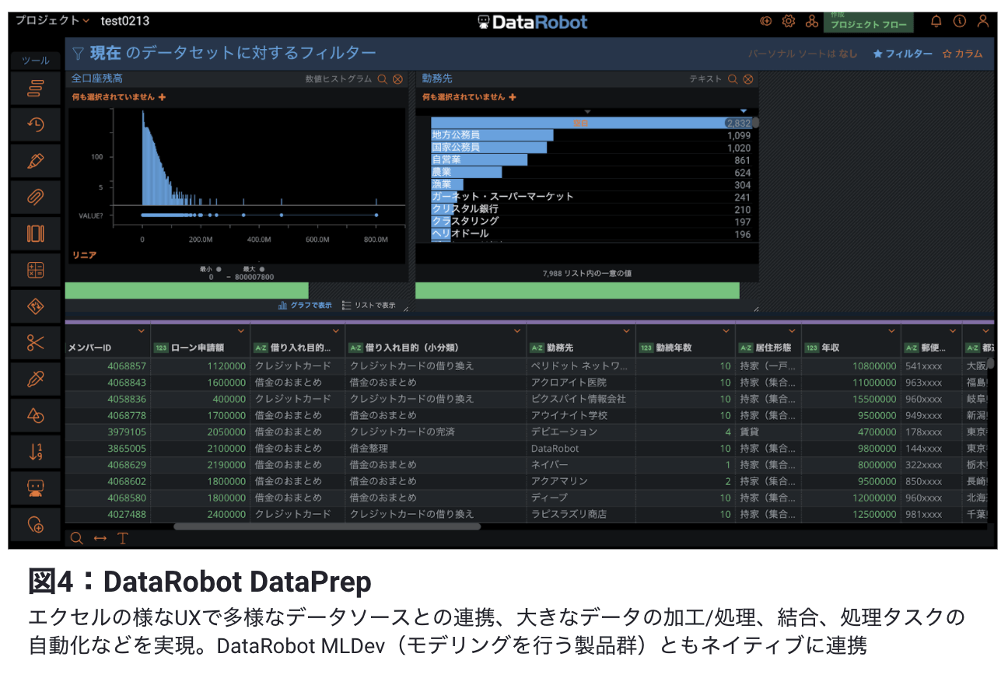
- Data Prep:元は Paxata と呼ばれていた GUI で行える ETL ツールです。大量のデータを扱えると同時に、エクセルによく似たUIを持っているため、ユーザーは簡単にデータを可視化し処理する事が可能です。
しかしこれらの方法で生成した特徴量全て使ってモデリングを行った場合、全ての特徴量がモデルに有用なケースはまずありません。
機械的アプローチで生成すると、単にデータとしてその中からパターンを抽出するだけで、機械学習はそのビジネスがどのようなビジネスなのかを考えて特徴量を生成する訳ではありません。その結果、ビジネス的に意味をなさない、不要な特徴量が多く生成される事は想像に難しくありません。
ビジネスナレッジに基づいたアプローチの場合でも、経験豊富な担当者の考えは単に仮説であり、本当に重要かどうかはモデリングを行い精度向上に寄与するか検証するまで分かりません。
この様な不要な特徴量は、モデルを理解する事が難しくするだけでなく、時にはモデルの精度を悪化させる可能性があります。実際にビジネスで使えるモデルとするには、多数の特徴量の中からモデルの精度に寄与していないものを特定し取り除く必要があります。
DataRobot では特徴量のインパクトというモデルの可視化技術を使う事で、全てのモデルで各特徴量の予測精度への影響度を定量化する事ができます。この機能を用いて、影響度の小さい特徴量を削除していく事で、機械的に生成した多数の特徴量から、重要なものを特定する事ができます。不要な特徴量を徐々に削除しモデリングするプロセスを繰り返す事で、多くのデータの中から最終的に新商品の需要に影響の大きい特徴量を特定し、モデルの精度も向上させる事が可能になります。
また、特徴量のインパクト以外にも、特定の特徴量が変化すると予測値がどれほど変化するかを表す部分依存や1行1行の予測に対して影響の大きい特徴量を可視化してくれる予測の説明など、DataRobot は豊富なモデル可視化の機能を備えており、不要な特徴量の発見に利用できます。
在庫・欠品リスクのバランス
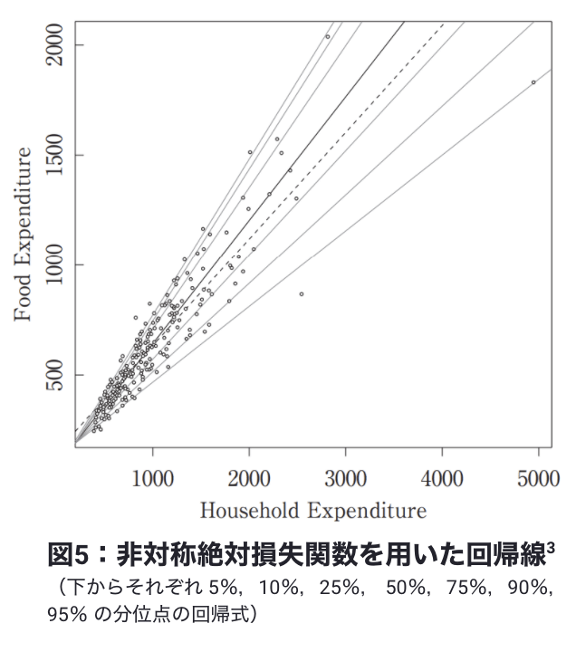
通常の回帰モデルのアウトプット予測値は、説明変数を与えたときの条件付き平均値であり、ビジネスで使うに当たっては満足いかない場合が多くあります。例えば CPG メーカーが顧客(小売・卸)との関係性を重要視する場合、過剰と欠品のリスクを同等に評価するのではなく、少々の過剰在庫を持ってでも欠品を回避したいという判断を下します。この様なビジネスニーズに答えるため、DataRobot では非対称絶対損失関数を使って最適化を行い、分位点回帰をおこなう機能を用意しています。ビジネスニーズに基づき、適切な分位点を設定してモデリングを行う事で、より在庫/欠品を回避するモデルを生成する事ができます。例えば、先ほどの少々過剰在庫のリスクを負って欠品を抑えたい場合は、75%の分位点でモデリングを行う事で50%の分位点でモデリングを行った場合より欠品を半減する事ができます。
シミュレーションと最適化
最終的に意思決定を行うために、いくつかのシナリオでの需要を考えたり、限られたリソースをどの様に分配すれば売上が最大になるのか最適化などを行う場合が多くみられます。
そこで、DataRobot では生成したモデルを用いてシミュレーションや最適化を行うアプリケーションを提供しており、逆問題ソルバーなどのその他のツール GUI が必要なく GUI インターフェースでシミュレーション/最適化を行う事ができます。
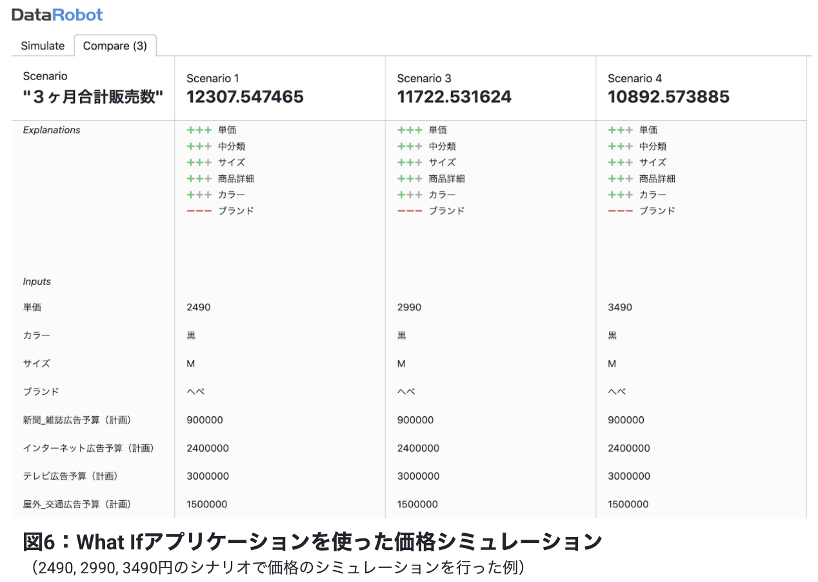
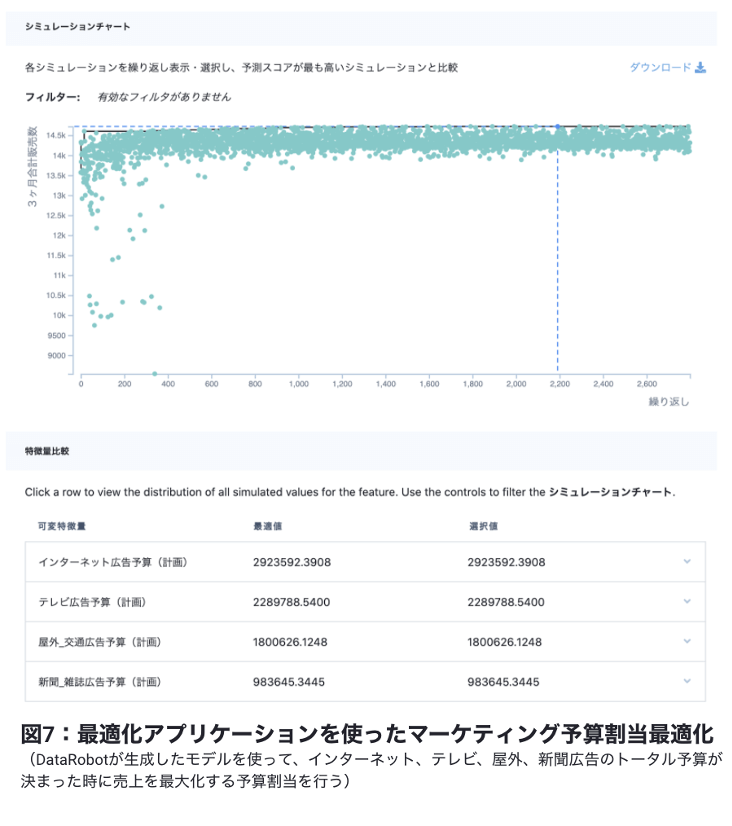
例えば、いくつかの価格シナリオでの需要を予測し比較する(図6)、あるいは新商品のマーケティング予算を決定する時に売上を最大化する最適な予算配分の探索(図7)も行う事ができます。
AI 需要予測を行う際の注意点
制約された需要
AI 需要予測に限った話ではありませんが、過去にリリースされた新商品によく欠品が出ていたのであれば、制約された需要(constrained demand)に注意が必要です。機械学習では過去の販売実績を正解としてモデルを学習し予測を行います。つまり過去の販売実績に欠品のケースが含まれていた場合、実績は本来の需要を下回った値となり、それを用いて学習したモデルも同様の傾向を持つものになってしまいます。
この問題を回避するために一番シンプルな方法は、欠品があった実績を除いて、本当の需要を表す結果のみを学習データに用いる方法です。
ただ元々の新商品の数が少なく、欠品となるケースが多い場合は、モデリングに使えるデータが少なくなり十分な精度がでない事も考えられます。そこで欠品が発生した実績から、モデルを使って本来売れたであろう需要を推定する事で、予測に活用する事も可能です。
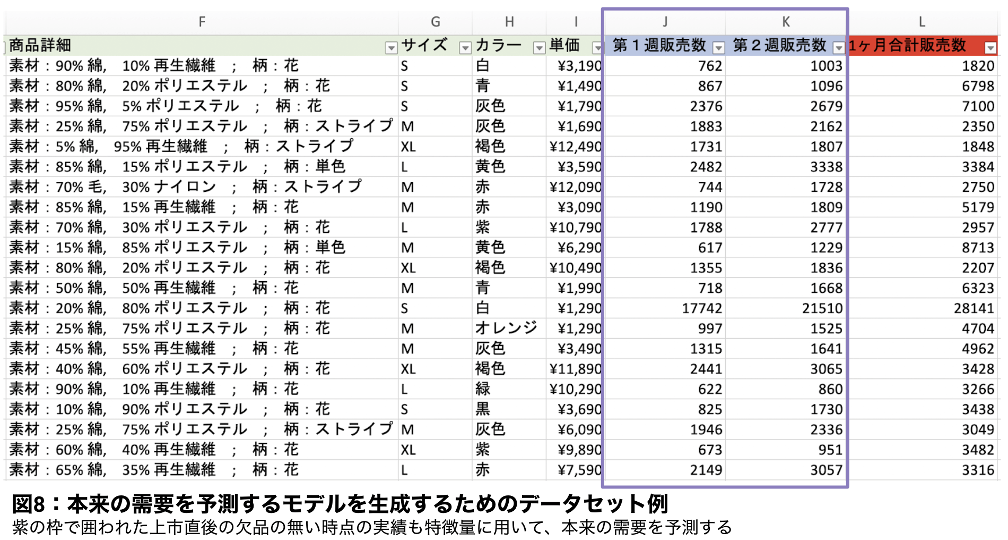
欠品があった商品から本来の需要を予測するためには、下図にある様に、欠品がなかった商品の実績データを用いて、多くの商品で欠品のない『上市直後の短期間での販売実績』と商品属性などから本来の需要を予測するモデルを生成します。このモデルを使う事で、欠品のあった商品の本来の需要が推定できます。欠品があった商品に対しては、このモデルの予測値を需要量としてモデリングを行う事で、データ量が増し、予測精度の向上に繋がります。
データ数が少ない場合
AI・機械学習モデルで新商品需要予測モデルを生成するにあたり、過去にリリースされた学習用データとなる新商品の数は重要なポイントです。十分なデータがない場合、過学習したモデルができてしまう場合や、学習/検定データのサンプル数も少ないため、精度やインサイトなどが不安定なモデルとなる傾向があります。
清涼飲料や酒類では絶え間なく数多くの新商品がリリースされていますが、日雑品などの業界では新商品の数が少ないのが現実です。そこで無理やりデータを増やそうとすると、より過去に遡る以外に道はなく、10年以上前の商品データを使う様な事態になります。しかし一般的に、10年前の古いデータは現在と全くトレンドの変わっており予測の役に立たない、時には予測に悪影響を及ぼす事が多くみられます。そこで、近年のデータのみを用いて少ないデータで予測モデルを作る以外に道はありません。
その場合、こちらのブログにまとめられている少数データ、横長データでよりロバストなモデルを生成する方法を活用する事が有効です。具体的には、以下の様な手法を使う事でよりロバストなモデリングが可能になります。
- 多様なモデルを組み合わせたよりロバストなアンサンブルモデルを利用する
- ランダムシードを変えパーティショニングの条件を変えた複数のケースでモデリングを行い、それらの複数の結果を元に特徴量選択を行う
予測できる新製品と予測できない新製品
機械学習・AIは過去のデータからパターンを学習し、予測を行うデータサイエンスの技術です。逆説的に言うと、AI では過去のデータと全く異質な新商品に対しての予測は難しいという限界を理解しておく必要があります。
既存品のリニューアルやこれまでの自社商品の類似品などは AI を用いた需要予測である程度信頼できる予測を行う事ができる可能性がありますが、これまで自社で一度もリリースされた事の無い商品や市場に類似品すら存在しない商品、あるいは自社最高の売上を上げる様な商品の需要予測は AI を使って行う事はできません。この限界を理解し、AI モデルで予測を行う商品と行わない商品をしっかり分類する事が重要です。
最後に
AI は、これまで営業やエキスパートパネルの勘/経験に基づいて行われて来た新商品需要予測を、データに基づきより正確に行う事ができる可能性のある技術です。しかも DataRobot を用いて、これまで一部の人間しか使えなかった AI モデリングが、誰でも手軽/短時間にできる様になってきました。その結果、精度のみならず、属人化や予測にかかる工数など、多くの新商品需要予測に関わる問題が解決されています。
このブログを読まれて、もっと具体的な新商品需要予測のプロセスを知りたい方は、Pathfinder に具体的なデータとステップ毎の詳細が入った記事があるのでご参照ください。
また、AI を使った新商品需要予測の事例を知りたい方は、弊社オンラインイベント「AI Experience Virtual Conference」で資生堂の山口様に講演いただいた事例ビデオをオンデマンドで公開しています。化粧品新商品需要予測での AI 活用方法や、精度改善の結果と成功要因、需要予測での DX を成功させるスキルや組織体制などを詳しくご説明されていますのでご参照ください。
参考文献
[1] 石川 和幸 (2017) この1冊ですべてわかる SCMの基本 (日本実業出版社)
[2] 月刊ロジスティクス ・ビジネス2010年10月号 (2010) 日本型SCMが次世代を拓く第5回 (ライノス・パブリケーションズ)
[3] 元山 斉 (2015) Commentary 分位点回帰-理論と応用- (社会と調査)

DataRobot データサイエンティスト。小売・マーケティングのスペシャリストとして、需要予測からダイレクトメールのターゲティングモデルまで様々なテーマで AI を活用し、企業の AI 変革を推進。より多くの人がビジネスで機械学習を活用できるよう DataRobot を使った機械学習の民主化を推し進めている。元リターゲティングのリーディングカンパニー Criteo のデータサイエンスチームリード。デジタルマーケティングや小売でのAI活用関連の研究会講師や講演・寄稿多数。
直近の注目記事
マーケティングと機械学習は相性抜群、データサイエンティストが業務ごとに解説(ビジネス+IT)
AIを使いたい小売・流通業へ、データサイエンティストが教える機械学習活用法(ビジネス+IT)
AI駆動で始まる新たなマーケティングスタイル。AIがマーケティングにもたらす価値(Ledge.ai)
DataRobot 中野さんに聞く:機械学習の民主化がもたらすマーケティング分野でのAI 活用(Unyoo.jp)
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事