
機械学習パーティショニングのまとめ
Part 1
– 適切なパーティショニングを選択するために –
はじめに
DataRobot でテレコム・鉄道分野のお客様を担当しているデータサイエンティストの佐藤です。
データサイエンスに携わり、モデルを作成しようと思った際に必ずと言っていいほどぶつかる壁が”適切なパーティショニングの選択”です。筆者もデータサイエンティストとして駆け出しの頃にパーティショニングがなぜ必要なのか?今予測したい問題においてどのパーティショニングを選択するべきなのか?非常に悩んだ覚えがあります。
本稿では、当時の私のようにパーティショニングについて悩んでいる方を対象に、何を基準にどういうケースにおいてそれぞれのパーティショニングを選択するべきなのかを考察します。
※より一つ一つのパーティショニングの方法を知りたいという方は、「機械学習パーティショニングのまとめ Part 2」をご参照ください。
パーティショニングとは?
データサイエンスの領域におけるパーティショニングとは、データを分割する方法の総称を示しています。データのパーティショニングには大きく2つの種類があり、一つが垂直方向のパーティショニング。もう一つが水平方向のパーティショニングです。
垂直方向のパーティショニングはデータを列で分割することを示しているので、データサイエンスの領域では特徴量を管理して別テーブルとして利用するケースなどで利用されることが多い手法です。複数のプロジェクトで利用されるような特徴量に関しては共通の特徴量セットとして保持しておき、それ以外のオプショナルの特徴量は別テーブルとしてパーティショニングして保持し、必要に応じて利用するケースがあります。
これにより、不要な特徴量をハンドリングする必要がなく、過学習の防止や計算時間の短縮が見込めるようになります。ただし、データのパーティショニングと聞くと一般的には水平方向のパーティショニングのことを指すことが多く、垂直方向のパーティショニングについて本稿では取り扱いません。
水平方向のパーティショニングはデータを行方向で分割することを指します。機械学習ではデータを学習用、検定用、ホールドアウト用(Training, Validation, Holdout)に分けることが一般的であり、実運用に耐えうるような汎化性能が高いモデルを構築するためには正しいデータパーティショニングに基づいた検定(Validation)などが必要になります。
以下、本稿ではパーティショニングは水平方向のパーティショニングを指します。
パーティショニングと機械学習
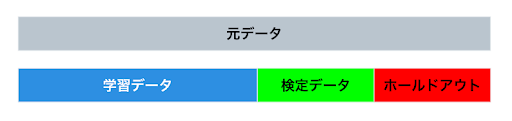
先述の通り、機械学習ではパーティショニングによってデータを学習用、検定用、ホールドアウトに分割する必要がありますが、そもそもなぜこのようにデータを分ける必要があるのでしょうか?仮に全てのデータを学習データにして予測モデルを作成した場合、学習データへの予測結果は良いが、実際に新しいデータに対してどの程度の精度が出るのかを評価することができません。例えれば、入学試験の過去問題は完璧に解けるが、それ以外の模擬試験や本試験を解けるかはわからない状態になってしまいます。
※学習に用いたデータを使用して検定(モデル評価)を行う方法を in-sample validation、学習用と検定用を分けて行う検定方法を out-of-sample validation と呼びます。AIC(赤池情報量基準)、BIC(ベイズ情報量基準)などのモデル評価指標は in-sample validation として有名で、どの程度データに適合(fit)しているかという項と複雑性を表す項の組み合わせで構成されていますが簡易的なものです。
out-of-sample validation として用いられる交差検定(Cross Validation、詳しくは Part 2を参照)は計算量が膨大になるため、以前は非常に時間がかかる手法でした。しかし、近年コンピュータの計算速度の向上により大量のデータでも交差検定を現実的な時間で処理できるようになったため、機械学習においては out-of-sample validation が一般的に利用されています。
ここで登場するのが検定データとホールドアウトという概念です。検定データは模擬試験であり、ホールドアウトは本試験に相当します。機械学習ではこの検定データ(模擬試験)でどの程度精度が出るかを確認しながら学習していくことにより、学習データ(=過去問題)のみにフィットするようなモデルの作成を防ぎます。
また、模擬試験が解けたからといって絶対に本試験が解けるとはなりません。入学試験であれば出題傾向や出題方法が変われば結果も大きく変わります。機械学習でも同様に学習時には結果を絶対に見ることができないホールドアウトというデータも確保しておくことで、未知のデータに対する精度を推定します。
DataRobot 上ではホールドアウトはモデリングを行う上で DataRobot も人間も見ることができないので、ホールドアウトの精度を高めるためのモデリングやホールドアウトの精度が最も高いモデルを選択するということができません。(こうしてホールドアウトデータを未知のデータとして位置づけ、また、ホールドアウトのデータに基づいてモデルが過学習しないよう歯止めをかけています)
つまり、同じデータセットから作成した複数のモデルの中でベストなモデルを選択する場合、一般的にホールドアウトの結果を確認する前に、交差検定の結果などからモデルを選択する必要があります(この順番は非常に重要です!)。このように交差検定の結果などを参考にどのモデルを採用するか選択するのもデータサイエンティストの技量の一つなので、今後データサイエンティストを目指す方には是非腕を磨いて頂きたいポイントです。
パーティショニングの重要性
適切な機械学習モデルを作成するためには、パーティショニングを行う際、以下の3つの要素を考慮する必要があります。
- 実際のプロセスや現象を遵守した、学習用・検定用・ホールドアウトの選択(時系列パーティション・グループパーティション)
- 1の制限内でホールドアウトを見ずに検定用データ、学習データ、の性質をできるだけホールドアウトデータに近づける(ランダム・層化抽出・Adversarial Validation)
- 上記を考慮した上でモデルの安定性を高める(交差検定・Leave-one-out法)
これらの要素を軽視すると適切なモデル評価ができていないリスクがあり、その結果として汎化性能(未知データを精度良く予測する能力)の欠如やデータリーケージ(後述)が起こっている、そもそもモデルとして正しくないモデルが生成される可能性があります。
一方、パーティショニング手法には多くの種類があり、適切な手法を選択することは難しく、また、どのようなケースでも常にベストな「万能パーティショニング」などは存在しません。したがって、モデルを作成するにあたっては予測したい問題に対して、どのパーティショニング手法が利用できるかを見極め、そのパーティショニングのメリットとデメリットを理解した上で適切なパーティショニングを選択することが必要になります。(DataRobot は代表的なパーティショニング手法を全て網羅しており自動で適切な手法を選択してくれますが、常に人間の目でその手法が本当にベストなのかどうかを考察することが重要です)
パーティショニングを軽視したケースでの失敗例
それではここでよくあるパーティショニングの失敗ケースを3つ、皆様に共有いたします。
- 問題の前提条件を無視したパーティショニング
- 時系列を無視したパーティショニング
- グループを無視したパーティショニング
一つ目の問題の前提条件を無視したパーティショニングの例として、実業務では中国の出店における売上を予測したいが、実際に手元にある学習用のデータは日本の出店に関するデータしか所有していないようなケースを考えてみます。この状態で予測モデルを作成すると実際に作成されたモデルが日本国内でのみ活用できるにも関わらず、中国での出店における売り上げの予測をするため適切な予測をすることができません。実運用に導入される前に適切なパーティショニングが行われているかどうかの確認しなくては、大きな損失を出してしまいます。
このように本来予測したい対象を適切に表現していないようなデータを学習用に用いることで、実運用に導入時に初めて失敗に気づき失敗するケースです。
二つ目の時系列を無視したパーティショニングの例として、「アナと雪の女王」の興行収入を予測する際に「アナと雪の女王2」(続編)の興行収入の値を使って学習するケースを考えてみます。確かにシリーズ続編での値を使えればより当てやすくなりますが、実際には「アナと雪の女王」は「アナと雪の女王2」の前にリリースされており、その時点では「アナと雪の女王2」の興行収入を知ることはできません。このように予測したいターゲットに対して、本来未知であるべき答えとなるような値を使って学習を行うことを「データのリーケージ」といいます。特に時系列問題においては非常に起こりやすい問題なので、パーティショニングを実施する際には予測時の状況を想像し、そのときに”どのデータ”の”いつまで”の値が取得可能なのかを注意する必要があります。
※なお、予測時よりも未来の時点の値であっても自身がコントロールできるような値であれば学習データとして利用することは可能で、例えば「予算執行計画が決まっているプロモーション費用」や「休業するかどうかのフラグ」などが挙げられます。
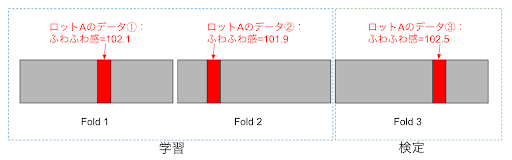
三つ目のグループを無視したパーティショニングの例として、パンの製造ラインで「ふわふわ感」を予測する問題で、各ロット毎に品質に多少の偏りが発生しているケースを考えてみます。その場合、もし学習データと検定データのどちらにも同一の製造ロットで生産された製品(パン)が含まれていると、製造ラインで計測される温度やその他センサーのデータから学習するのではなく、「この製造ロットで生産されたのでふわふわ感はこれだ」という様に、製造ロットの ID 番号等ロットを識別する情報を過学習してしまいリーケージが発生する可能性があります。実運用上はこのようにある特定のグループが(ここではパン製造ロット)全く同一の品質で将来また出現するとは考えられないので、検定データやホールドアウトデータは必ず学習データと違うグループのデータだけで構成されなければなりません。この制約条件を保証してデータリーケージを防止するためには、Group K Fold のようなパーティショニング手法を選択する必要があります。
以上のような失敗を未然に防ぐために、Part 2では各パーティショニングの種類、それぞれの特徴と使い分けについて考察します。
基本的なパーティショニングの選択基準

各パーティショニングの種類と詳細に入る前に基本的なパーティショニング方法について説明します。
上記表1は最も基本的なパーティショニング手法を選定する上で、どのような基準で選択するべきかを一覧表にまとめたものです。多くの場合、まず予測したい問題が回帰問題なのか?分類問題なのか?また、データ量は多く存在するのか?それとも少ないのか?という軸で評価したのち、一般的な予測問題なのか?時系列性があるのか?グループ性があるのか?といった観点から適切なパーティショニング手法を選択する必要があります。
※なお、上記で述べているパーティショニングは世に提案されている様々な手法の一部であり、予測する問題に応じて適切な組み合わせなどを選択する必要があります。
まとめ
ここまでのPart 1の記事では、パーティショニングとは何か?パーティショニングと機械学習の関係性、パーティショニングの重要性と基本的なパーティショニングの選択基準を考察してきました。
「機械学習パーティショニングまとめ Part 2」では各パーティショニングの種類、それぞれの特徴と使い分けについてより詳細を考察していきます。
参考文献
Akaike, H. (1973). Information theory and an extension of the maximum likelihood principle, 2nd International Symposium on Information Theory (eds. B. N. Petrov and F. Csaki), 267-281, Akademiai Kiado, Budapest. (Reproduced in Breakthroughs in Statistics, Vol.1, Foundations and Basic Theory (eds. S. Kotz and N.L. Johnson), Springer-Verlag, New York, (1992).)
https://link.springer.com/chapter/10.1007/978-1-4612-1694-0_15
Schwarz, G. (1978). Estimating the dimension of a model, Annals of Statistics, 6, 461-464.
https://projecteuclid.org/journals/annals-of-statistics/volume-6/issue-2/Estimating-the-Dimension-of-a-Model/10.1214/aos/1176344136.full

米国大学研究員を経て、外資系コンサルティングファームでコンサルタント兼データサイエンティストとして AI Team の立ち上げを経験し、小売・製造・ヘルスケア等様々な業界向けに需要予測・レコメンデーション・営業戦略立案などに従事。
2021年から DataRobot 社のデータサイエンティストとしてテレコム・鉄道系のインダストリーを担当し、AI・データ利活用を推進している。
AI・データ利活用などについての講演活動も各所で行っている。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事