大変動下での機械学習モデルへの対処
はじめに
コロナウイルスの感染者数は日本全国各地、及び世界の多くの国で増加し続けています。その結果、マスク・消毒液品の品薄・品切れ、訪日外国人・旅行客の減少のみならず、一部の国では病院・医療機関が対応しきれず、医療崩壊を招くなど、社会・経済に大きな影響を及ぼしています。
その様な状況下でこそ、予測はより一層重要なテーマとなります。例えば、マスクなどは海外で生産されるものが多いため、約半年のリードタイムがあると言われています。つまり、生産者も半年先の需要の予測を行い、未来の需要に合わせて生産し、必要な在庫を確保しておく必要があります。
しかし、AIは過去のデータから学習するため、過去に未経験の事例に対して予測するのは得意ではありません。この様な未曾有のイベント・大変動に対して、機械学習の予測は信頼することができるのでしょうか?あるいはどの様にすれば、大変動に対応できる機械学習モデルを作ることができるのでしょうか?
本ブログでは、大きな変化が起こっている際に精度の劣化を最小限に抑えながらAIのモデルを使っていくためのポイントを、以下の2つにまとめてご紹介します。
- モデル性能監視
- 変化に対応できるモデルの生成
モデル性能監視
大きな変化が起こっている際に機械学習モデルを運用するに当たって重要なポイントの1つが、性能監視です。デプロイされたモデルの性能低下の原因となる要因を検知すると同時に、その精度をモニタリングする事で、予想外の予測値や精度の低下を事前に防止する事ができます。
データドリフトの検知
データドリフトとは、機械学習モデルをトレーニングした時のデータと、予測を行う時点でのデータがずれていく現象です。予測に重要な特徴量がトレーニングした時と異なった値を取るときには、より予測が外れるリスクが高まります。
例えば、来店客数を特徴量として使っている需要予測モデルを考えましょう。モデリングした当時と大きく状況が変化した場合、モデルの予測値が当たらなくなる可能性が高まります。そこでモデルのデータドリフトを監視する必要性が生じます。
コロナウイルスの影響で、顧客の購買がリアルからECに変わってきていると言われています。来店客数をはじめとする特徴量のデータドリフトをモニタリングする事で、状況がモデリング当時と大きく違った場合にアラートを上げ、問題を未然に防ぐ事ができます。
精度の監視
しかしデータドリフトはモデルの精度低下の可能性のアラートをあげるだけで、モデルの精度の評価はできません。予測を行った後に正解データが出てきたタイミングで、予実を比較し精度を評価が可能になります。モデル精度の経時的変化をモニタリングする事で、精度が下がってきた時点でアラートをあげ対応が可能になります。
MLOPs
以前のブログで紹介した通り、MLOps (Machine Learning Operations)はモデルの構築を迅速かつ効率的に実現すると同時に、高度なモデル運用の実現を目指す考え方です。
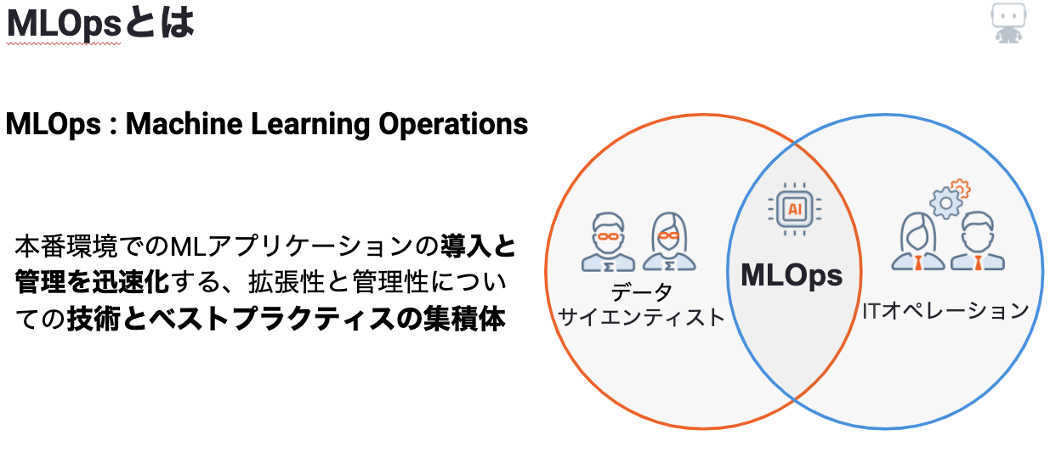
データドリフトの検知、精度の監視は、MLOpsの中でも重要なモデル性能監視の基礎となる2つのポイントです。
しかしモデル管理者が運用している全てのモデルの性能を監視することは現実的でありません。そこでMLOpsでは、問題が起こるとアラートメールを自動で送るといったシステムも必要です。
DataRobotでも最近製品提供し始めたMLOpsは、単なるモデル管理に収まらず、データドリフトや精度の変化を逐次モニタリングし、状況の変化やリスクを事前に察知しアラートをあげるという仕組みを備え、大きな変化の下でのモデル運用に欠かせないものです。
変化に対応できるモデルの生成
モデルの性能監視や精度悪化をモニタリングし、状況の変化を事前に、あるいは早い段階で察知できたとしても、その変化に対応できるプロセスが必要です。そこで本セクションでは、大きな変化に対応できる頑健なモデルを生成する方法を説明します。
真っ先に思いつくのは、より早く最新のトレンドをモデルに反映し変化に対応させるという方法だと思います。この方法は特に予測を行う未来のポイントが近い場合などには活用できます。
しかし、最新のトレンドを使っても、不連続な変化が続いている場合には対応できません。そこで予測時点の経済シナリオなどをわかっている特徴量としていくつかシナリオを与えてシミュレーションし、それぞれのケースでの予測を行うという方法も使われます。
また、これらの手法を使ったモデルの変化への頑健性をどの様に評価するかも1つポイントになります。
変化に早期対応できるモデル
できるだけ早く大きな状況の変化に対応させるには、大きく分けて2つの方法があります。
- より高頻度に最新のデータをモデルにフィードバックする
- モデルの最新の変化へのセンシティビティを高める
高頻度に最新データをフィードバック
機械学習モデルはトレーニングデータからパターンを学習し、それに基づいて予測を行います。つまり、未曾有の変化があった際のデータをトレーニングに使っていないモデルでは、高い可能性で変化に対応できず当たらない予測となります。そこでモデル更新の高頻度化が必要になります。最新のデータを取り込んだ再モデリングの頻度を上げ、月次から週次にする、週次を日次にする事で最新データのフィードバックが可能になります。
あるいは、最新の状況を逐次取り込み学習していく、オンライン機械学習(逐次学習)が使えるアルゴリズムを利用するという方法も1つのオプションです。
モデルの最新の変化へのセンシティビティを高める
いくらモデルの更新頻度を高めたり、オンライン学習したとしても、変化が起こった後のサンプル数が十分にない場合、モデルが変化のパターンを学習することは難しいです。データが十分集まるまで指を咥えてデータを収集する以外に何ができるのでしょうか?
ここではより最新の変化へのセンシティビティを高める2つの技術を紹介します。
1つには、最新の大きな変化があったサンプルに荷重をかけてモデリングし、それらに対しより強制的に合わせにいく方法があります。これはモデリング時の最適化指標に荷重を加えた精度指標を使う事で実現されます。
例えば、以下の式で表されるWMAPE(荷重絶対値平均誤差率)
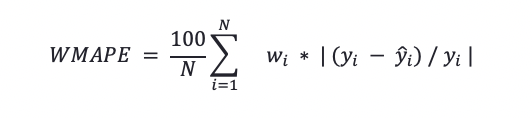
を使ってモデリングを評価する事で、荷重の高い特定のサンプルへの学習へのペナルティーを高める事ができます。最新のサンプルへの荷重を高める事で、最新の変化により合致するモデルが生成されます。
2つ目の方法は、モデルに長期のトレンドを使わない方法です。
平常時は昨日や先週の売上を参考にすれば、今日の売上も大体わかります。つまりその様なケースにヒストリカル特徴量は強力な予測力を持ちます。結果平常時のデータでモデリングすると、それらを主要なシグナル(特徴量のインパクト上位)としたモデルが生成されます。
しかし大きな変化の時には、自己相関が弱まり、昨日や先週の値を参考にしすぎると、予測も外れる可能性が高まります。特に1年の平均売上の様な長期のトレンドを特徴量とすると、特に直近の変化に対応できなくなります。以下のグラフからも、12ヶ月移動平均は2009年の大きな変化の時期に反応が遅れている事がわかります。
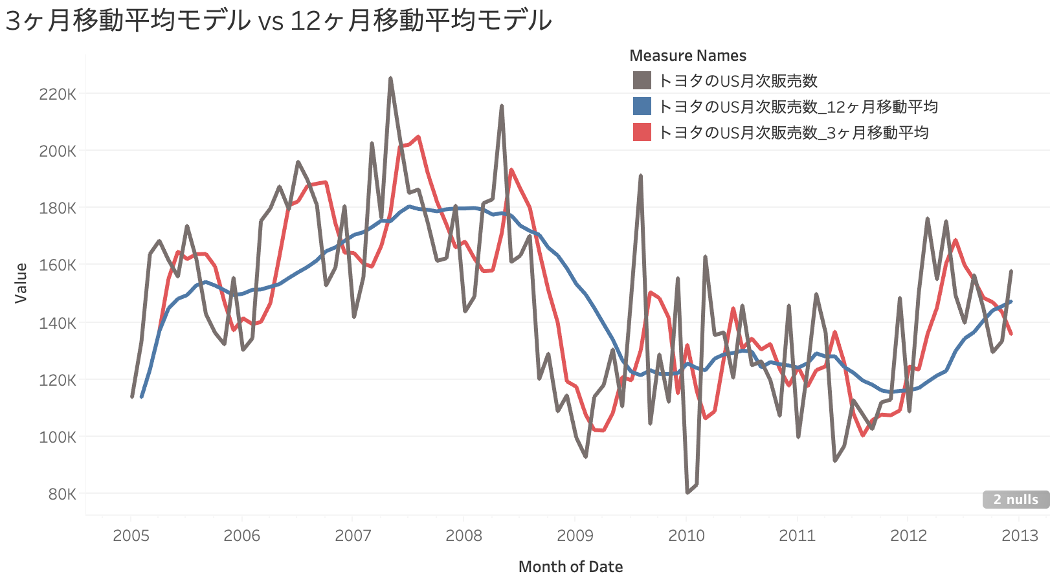
通常時にはノイズを吸収し予測を安定させてくれる長期の移動平均は、大きな変化の時には諸刃の剣となり、予測の状況変化対応を遅らせる事につながります。
What-if分析による未来の予測
ある程度連続した変化を示す場合や、近い未来を予測する場合には、高頻度で最新のトレンドを学習することで対応が可能です。しかし、大きな変化がある状況で遠い未来を予測する場合、あるいは完全に不連続な変化が起こる場合には、最新のトレンドを学習したモデルでは対応できません。
事実リアルビジネスでも数ヶ月先の遠い未来の予測が必要とされています。例えば、製造から販売まで自社で行うSPA(製造小売)企業などでは、海外の工場から出荷する場合も多く、数ヶ月のリードタイムがあります。大きな変化が起こっている中で数ヶ月先を予測することは非常に難易度が高く、ビジネスで使えるレベルの精度の予測は期待できません。
この様な問題の予測が難しい理由は、大きな影響を及ぼす外部ファクターが予測不可能なためです。例えば、アパレルにおいて夏や冬の気温は需要に大きな影響を及ぼしますが、数ヶ月前の生産時点で冷夏、暖冬などを正確に予測する事は、機械学習だけに限らず、専門家にとっても非常に難しい問題です。
そこでこれらの外部ファクターを、前もって知ることができるものとしてモデリングし、様々なケースでシミュレーションした結果を勘案して対応するという方法が取られます。アパレルの例で言うと、冷夏のケース、平年通りのケース、平年よりも暑いケースなどをシミュレーションし、それぞれの予測値とリスクを考えながら発注量の最終決断を下す事になります。
このWhat-if分析は元々金融で使われているストレステストと同様の方法です。金融機関では、様々な経済状況を想定し、デフォルト率やロスのシミュレーションを行い、金融危機への対応能力評価が行われています。
それではこれから、アメリカでのトヨタ車の販売台数をアメリカ合衆国国税調査局の出すUS Monthly Retail Trade Surveyを用いてWhat-if分析を行ってみましょう。月次小売飲食売上の数字を使ってトヨタ車の販売台数を予測するモデルをDataRobotで生成、その後様々なシナリオを想定し、シミュレーションを行います。
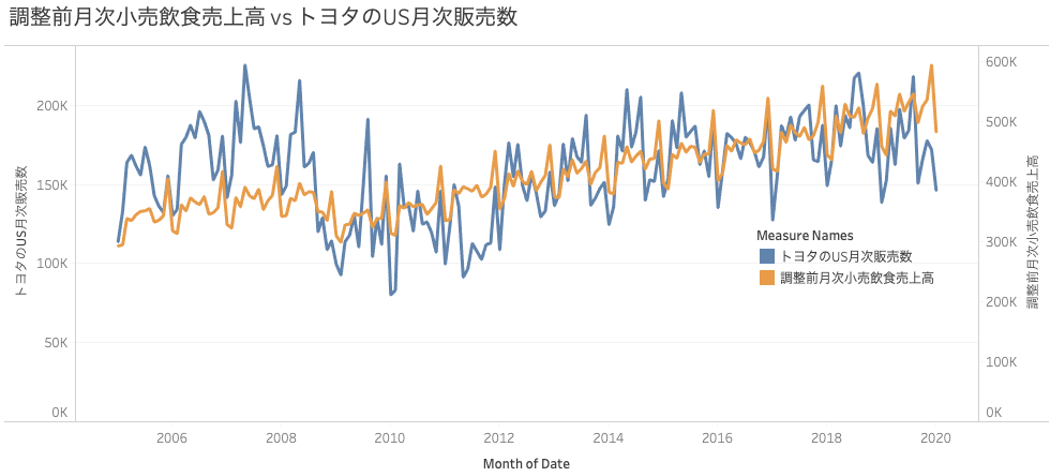
What-if分析を行うモデルを生成する際には、いくつか注意が必要です。
まず、特徴量同士が相互に影響を及ぼしあう場合、シミュレーションにおいて、片方だけが変わって一方の特徴量が変わらないというシナリオは意味をなしません。US Monthly Retail Trade Surveyには季節調整済みと未調整の月次小売飲食売上の値がありますが、それらは全く同じものを表します。つまり、一方が変われば必然的にもう一方も代わるので、両方の特徴量をモデリングに使う場合、両方に同等の変化を加えてシミュレーションする必要があります。この様なケースでは、特徴量を一方のみにまとめてモデリングすると、シミュレーションや解釈がたやすくなります。
それはこのモデルにラグ特徴量を加える際も同様です。トヨタ車の販売台数と月次小売飲食売上の相関性が高いため、必然的に月次小売飲食売上とトヨタ車の販売台数のラグ変数の相関も高くなります。結果、ラグ特徴量を使うとシミュレーションで見たい月次小売飲食売上の影響が過小評価される危険性が高くなります。
そこで今回は全く販売台数のラグ特徴量を使わず、月次小売飲食売上も未調整のものだけを使い、他の特徴量はDataRobotが自動生成した月の特徴量のみというシンプルなモデルでシミュレーションを行います。
もう1つ注意点としてあるのは、使うアルゴリズムごとの外挿特性の理解です。どのアルゴリズムを使っても、トレーニングデータの値域外ではデータに基づいた値ではなく、推定された値であるという点は同じです。しかし、以下の表の様にツリー系のアルゴリズム、NN系・線形回帰系のアルゴリズムによって外挿の方法に違いがあります。
今回は線形回帰のモデルとツリー系のモデルを使ってシミュレーションをしていきましょう。
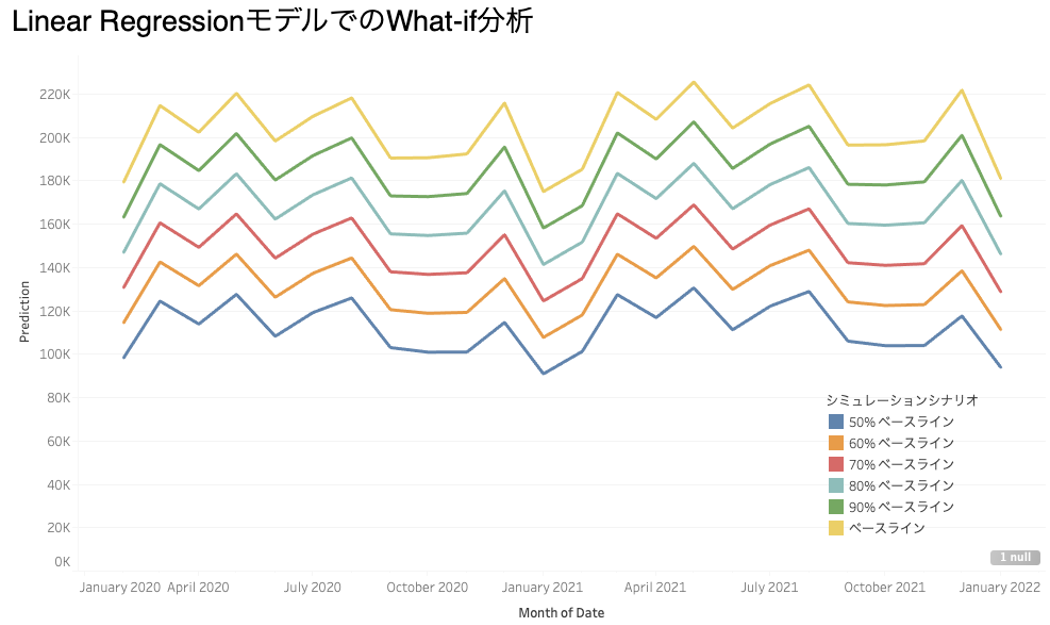
シミュレーションに使う、2020年2月以降の月次小売飲食売上の値は、マーケットアナリストなどの出すもっと正確な予測があるかもしれませんが、今回はSTLモデルで予測した値をベースラインとして、それより10%、20%、30%、40%、50%下がったケースをシミュレーションして行きます。
まず線形回帰モデルを使ったwhat-if分析をみてみましょう。こちらを見るとクリアに月次小売飲食売上が下がった分だけ、車の販売数も下がるという関係が出ています。
次にツリー系モデルでのwhat-if分析の結果を見てみましょう。下のグラフの特に以下の2つが目に付くと思います。
- 90%とベースラインでほぼ重なっている。
- 50%と60%の一部で重なっているところがある。
これはツリー系モデルの「予測値の値域は、トレーニングデータの値域を超えない。つまりモデルの外挿できる最大・最小値は、トレーニングデータの最小、最大となる」という外挿の特性によるものです。
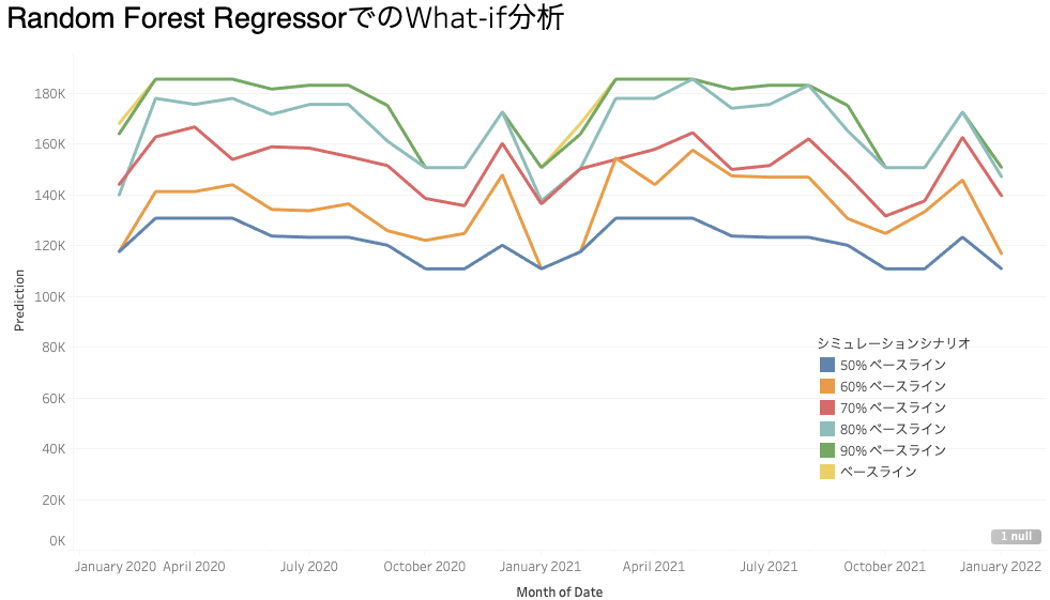
繰り返しになりますが、常にどちらの外挿が良いということはありません。今回の場合は、線形モデルの方が納得しやすいモデルと思われるかもしれませんが、50%減という状況は経験した事がないのでどの様になるかは実際に起こらないとわかりません。もしかするこれまでの半分しか物を買えない極限の状況では、新車を買っている余裕などなく、もっと大幅な減少となるかもしれません。どちらのモデルもトレーニングデータになかった値域に対しては異なった推測を行っているだけでしかないのです。
この様に、What-if分析ではこれまで経験したことのないシナリオが多く含まれています。つまりモデルの評価をモデルの検定スコアのみで行うのは難しく、シミュレーションの結果が現場にとって納得できるかという点が重要です。最悪なケースなど極端な事例も含めたシミュレーションを行い、ビジネスナレッジと合致したモデルか評価を行いましょう。
まとめ
本ブログでは大きな変化が起こった時に精度劣化を最低限に抑えながら、機械学習モデルを運用していく方法をご紹介しました。今まさに起こっている変化の時代においては、①モデルの性能を監視し、②変化に対応力の高いモデルを生成し、③それらのモデルの対応変化力を評価しながら機械学習モデルを運用していく事が必要です。
これらのモデルが実際に使えそうな場合は、機械学習モデルを使った頑健なモデルを以前通り運用し、逆に機械学習モデルが対応できないケースについては、ビジネス担当者の経験に任せてしまう事が重要です。

DataRobot データサイエンティスト。小売・マーケティングのスペシャリストとして、需要予測からダイレクトメールのターゲティングモデルまで様々なテーマで AI を活用し、企業の AI 変革を推進。より多くの人がビジネスで機械学習を活用できるよう DataRobot を使った機械学習の民主化を推し進めている。元リターゲティングのリーディングカンパニー Criteo のデータサイエンスチームリード。デジタルマーケティングや小売でのAI活用関連の研究会講師や講演・寄稿多数。
直近の注目記事
マーケティングと機械学習は相性抜群、データサイエンティストが業務ごとに解説(ビジネス+IT)
AIを使いたい小売・流通業へ、データサイエンティストが教える機械学習活用法(ビジネス+IT)
AI駆動で始まる新たなマーケティングスタイル。AIがマーケティングにもたらす価値(Ledge.ai)
DataRobot 中野さんに聞く:機械学習の民主化がもたらすマーケティング分野でのAI 活用(Unyoo.jp)
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事