
DataRobotでSNS上のデマ判定
新型コロナウィルスに関するデマツイート検知を NTTデータが検証
はじめに
分析の背景と分析目的
「10秒間息を止めることで新型コロナ感染が自己診断できる」「26〜27度のお湯を飲めば感染防止になる」「製造元が中国なので次はトイレットペーパーが不足になる」これらは Twitter 上で拡散された新型コロナウィルスに関するデマツイートの例である. このようなデマを見て, 実際に自己診断したり, お湯を飲んだり, トイレットペーパーを大量に購入した人もいたのではないだろうか.
SNS は有力な情報をタイムリーに得られるため, 情報収集源の一つとして利用されている. 一方で, 間違った情報や誤解を招くフェイクニュースやデマが, あたかも真実または真偽不明の情報として, 正しい情報よりも拡散するという問題が起こっている1, 2, 3. 今回の取り組みで使用したデータでも, デマツイートは非デマツイートよりも, 収束せずに拡散される傾向が見られた(図1).
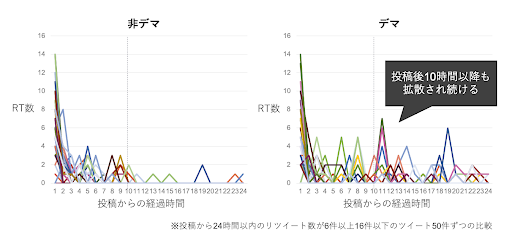
一方, SNS 上では会話や議論が活発に行われており, デマに対して自浄作用が働くこともある. 例えば, Twitterはデマ情報を見る割合が特に高いメディアである一方で, デマに対して注意喚起が行われる場でもある2, 3. 今回の検証でも, デマツイートのリプライの中に「ひどいデマを拡散している方ですね. 早く訂正されないと. 」といった注意喚起が見られた.
このような状況から, DataRobot COVID-19分析官向け無料プログラムに参加した NTT データ社のチーム(以下チーム)は, SNS 上における情報の信頼性を向上するために, デマ情報が広く拡散される前にファクトチェック結果を届ける作業の支援をすることが社会貢献になると考えた. そして, ツイートの拡散の仕方や会話の特徴を分析することで, Twitter 上の情報の信ぴょう性を判定できるかどうかを検証した. 具体的には, NTT データ社が保有する Twitter データと DataRobot から無償提供されたエンタープライズ AI プラットフォーム「DataRobot Auto ML」を活用して, 新型コロナウイルス関連のツイートをデマ判定する機械学習モデルの構築とデマツイートの特徴の分析に取り組んだ.
この分析のために NTT データ社から Twitter データアナリスト2名と DataRobot 認定データサイエンティスト1名がチームにアサインされ, DataRobot からもデータサイエンティスト1名が参加した. (チームメンバーのプロフィールは最終章に記載)この取り組みに関しては、デジマイズム記事でもご紹介している.
分析結果
最終的にチームは先行研究3で得られた精度を上回る精度のデマ判定モデルを構築できたが, もしこのモデルでデマを1つも取りこぼさずに正しく判定しようとすると, モデルがデマと予測するツイートの中に実際には28%ほど非デマのツイートが混ざってしまうことが分かった. そのため, チームはこのモデルの活用イメージとして, 機械によるツイートの完全自動判別ではなく, 信ぴょう性が疑われる大量の情報を人手で捌いているケースでの作業効率アップと対応の迅速化を目指したスクリーニングツールとしての使い方を想定した.
また, 今回の検証を実施する中で, 以下3つのポイントがツイートの信ぴょう性と強い関係性があると分かった.
- ユーザー名, プロフィール文の内容: プロフィール文が丁寧なアカウントや公式を謳っているアカウントが投稿したツイートの信ぴょう性は高い傾向にあり, プロフィール文がないアカウントが投稿したツイートの信ぴょう性は低い傾向にあった.
- ツイートへの反応: 否定的なリプライがあるツイートは信ぴょう性が低い傾向があり, また, いいね数が少ないと信ぴょう性は低い傾向にあった.
(リプライとは, ツイート内容に対する意見を, ツイートをしたユーザー本人に向けてメッセージとして送る機能で, リプライを送受信したアカウントをどちらもフォローしているユーザーのタイムライン上に表示されるものである) - ツイート投稿者の情報: 他のユーザーが作成したリストに数多く入っているユーザーほど, 投稿するツイートの信ぴょう性が高い傾向にあり, また, フォロー数がフォロワー数より劇的に多い, リスナータイプほど, 投稿するツイートの信ぴょう性が低い.
チームは Twitter 利用者が災害時にツイートを拡散する前に, 今回の検証や様々な研究1, 2, 3からわかってきたことを参考にデマであるか考えることで, SNS 上の情報の質が向上するものと考えている. しかしながら, 人は, 特に災害時には人助けをしたいという善意から結果としてデマを拡散しやすい傾向があり, そのため人間のファクトチェッカーは大量のツイートの信ぴょう性の確認に追われる事になる. 機械学習モデルによる AI がデマ判定をすることで少しでもファクトチェッカーを支援でき, SNS 上の情報の質をよくできればと思っている.
検証方法
データ抽出・準備
新型コロナウイルスに関するツイートがデマか否かを判定する機械学習モデルの構築には, AI が学習するための過去のデマツイートと非デマツイートが必要だ. この学習用データから, AI はデマツイートと非デマツイートを見分けるために有力な規則性を学習する. そのため, 学習用データを準備する際, ツイートがデマか非デマかラベルを付ける必要がある. 今回の取り組みでは, ラベル付にファクトチェックサイトの情報を利用した. デマツイートと非デマツイートの抽出方法と抽出した件数は以下表1の通りである.

デマツイートは, ファクトチェックで誤りと判明している新型コロナウイルスに関連する24種類のデマの話題に関するツイートから抽出し, 「デマ」とラベルを付けた. 次にコロナか COVID という単語と24種類のデマの話題別キーワードが入っているツイートを抽出し(ステップ1), それらの中で5回以上リツイートされているツイートに絞り(ステップ2), さらに目視で確実にデマツイートであるものに絞った(ステップ3). 5回以上リツイートがあるツイートに絞ったのは, 全く拡散されないツイートであれば, 信頼性を確認する必要はないと考えたためである.
非デマツイートは, コロナ, covid 19, 肺炎, ウィルス, virus という単語のうち少なくとも一つと, 効果的, 防ぐ, 予防, 有効という単語のうち少なくとも一つが入っているツイートを抽出し(ステップ1), それらの中で5回以上リツイートされているツイートに絞り(ステップ2), さらに目視で明らかにデマでないツイートのみに絞り(ステップ3), 「非デマ」とラベルを付けた. 非デマツイートに関しては, コロナや COVID という単語を本文中に含まずとも「ウィルス対策に○○が効果的」というような注意喚起ツイートも見られるため, コロナ関連ワードを拡張して「ウィルス, virus, 肺炎」といったキーワードを加えた. 明らかにデマでないツイートとは, WHO や国が呼びかけている内容, ファクトチェックサイトで真実とされている内容のものが該当する. なお, 限られた時間と人でデマか非デマかのラベル付けを行った結果, 今回の取り組みで準備できたデータ数は, 587ツイートであった.
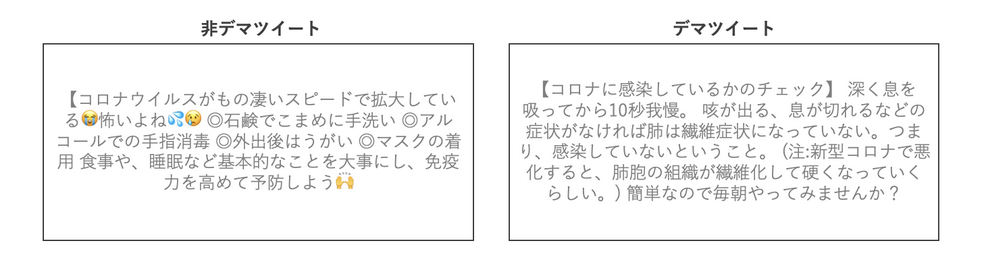
デマツイートと非デマツイートの具体例を下図2に示す.
以上のように対象となるデマツイートと非デマツイートを抽出した後, ツイートに関するデータやツイートしたユーザーに関するデータ, あるいは, ツイートへの反応に関するデータを準備した. また, 後ほどより詳細に説明するが, 抽出したデータ項目そのものだけでなく, デマ検知に有用と考えられる新しい項目を既存の項目から作成した. このように準備したデータ項目の概要は表2の通りである. なお, 以降は機械学習でよく使われる表現「特徴量」をデータ項目の意味で使用する.
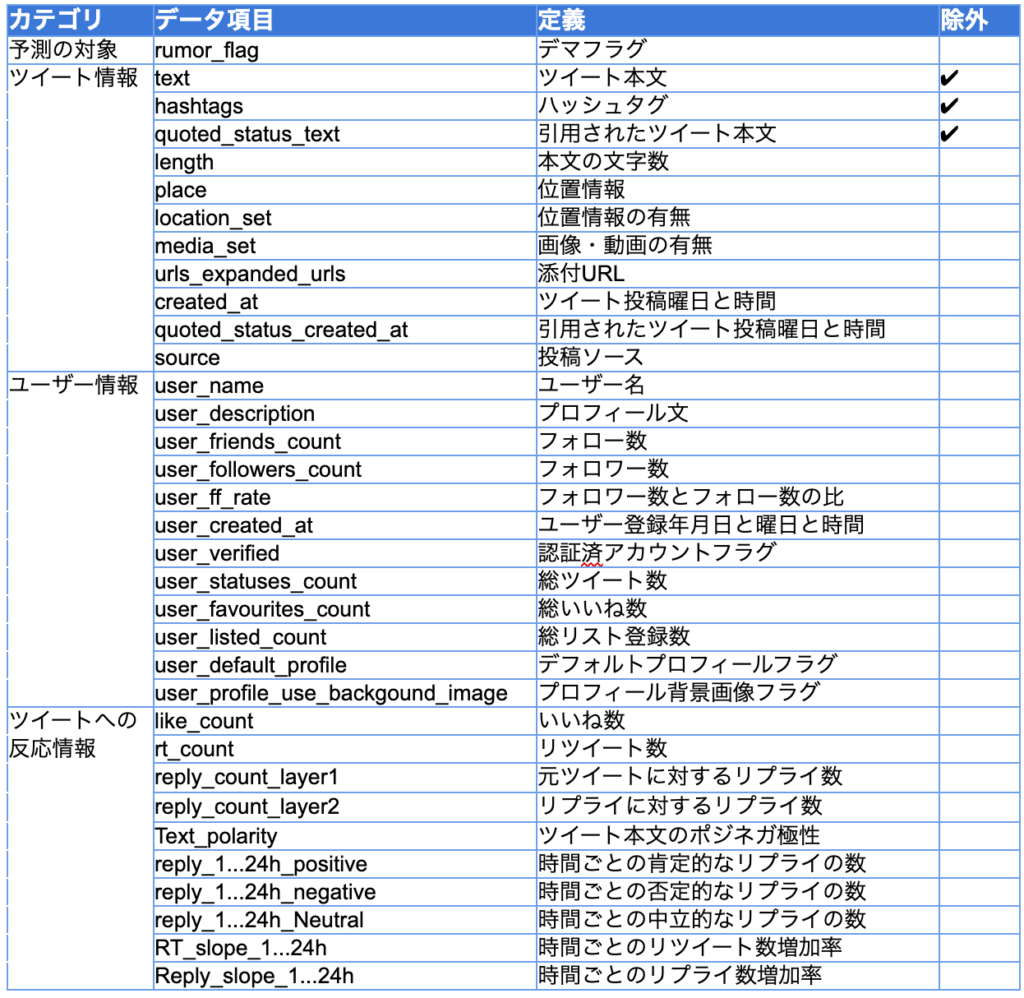
✔︎マークがついている, ツイートの本文とハッシュタグ, また引用されたツイート本文の内容は特徴量として使用しないことにしたため, 特徴量セットから除外した. 上述のようにデマツイートは24種類のデマの話題から抽出しているので, もしこれらの話題であればデマだという学習をすれば精度の良いモデルを構築はできるが, それでは単に抽出基準を学習しているだけであって, 新しい表現のデマツイートが現れた時に検知できないかもしれない. 例えば「10秒間息を止める」という内容はデマだと学習してしまい, 「お湯を飲む」という新しいトピックに応用できなくなってしまうということは避けたい. ツイートの内容に関するデータを使用しないことで, 内容によらずにより汎用的にデマツイートを判定できるようになる.
また, 実際にデマツイートは早いタイミングから非デマツイートより広く拡散されるという先行研究結果から1, 2, リツイート量とリプライ量の増加率が毎時間どれくらい変化しているかという時系列の特徴量を作成し, 拡散スピードがデマ検知に重要かを検証した. デマは広く拡散される前にできるだけ早く検知し注意喚起することが重要であるため, ツイート投稿後24時間以内の情報のみを使用して特徴量を生成した.
データ前処理
機械学習モデルを構築する際, 抽出したデータをそのまま使えることは少なく, データの前処理が必要となる. データの前処理には守りと攻めの2種類がある.
守りの前処理では, データの不備をなくしたり, データを機械学習アルゴリズムに適した形に加工する. 例えば表記ゆれの統一, 外れ値の除去, 欠損値の補完, カテゴリ型の項目の数値化などがある. 今回の取り組みでは, 欠損値の処理とカテゴリ値の数値化は DataRobot Auto ML が自動的に実行した. また表記ゆれや外れ値も, AI モデル構築のための前処理に特化した製品である「DataRobot Data Prep」を使用して容易に処理できるが, 今回は Data Prepを 使用する必要はなかった.
攻めの前処理では, 業務知識をもとに既存のデータを加工して新しい特徴量を生成したり, 他のデータベースの特徴量を結合したりして, 機械学習モデルの精度を向上させるのに利用する. 例えば, 気温と湿度と風速という3つの特徴量をある計算式に当てはめて, 体感温度という一つの新しい特徴量を作成することで, 人が外出するかをより正確に予測できるかもしれない. これらは特徴量エンジニアリングと呼ばれるもので, 既存の特徴量を加工して新しい特徴量を作成するというデータの前処理であり, 機械学習モデル構築において最も重要な作業の一つだ. 機械的な特徴量エンジニアリングは DataRobot が自動で実行してくれるが, 業務知識や常識をもとにした特徴量エンジニアリングは手動で実行する必要がある. 今回の取り組みでは以下の特徴量エンジニアリングを実施した.
- 本文の文字数: ツイート本文の文字数を計算した特徴量を作成. 先行研究では, 非デマツイートの方がデマツイートより文字数が多いという結果が得られている3.
- フォロワー数とフォロー数の比: フォロワー数とフォロー数の比を計算した特徴量を作成. フォロワーが集まってくるがフォローはしていないトレンドセッタータイプか, フォローに専念しているリスナータイプか, それともバランスタイプか, といったユーザーの特徴をデータとして持つことができるようになる.
- ポジネガ: NTT データが提供する「なずき」を利用し, ツイート本文の内容をポジティブ, ネガティブ, ニュートラルで判定し, 特徴量を作成した. また, ツイート投稿後24時間までの毎時間のリプライの内容をポジティブ, ネガティブ, ニュートラルで判定し, 集計した特徴量を作成した. 時間ごとの肯定的, 否定的, 中立的な内容のリプライ数を表す特徴量だ.
- 時間ごとのリツイート数増加率: ツイート投稿後24時間までの毎時間のリツイート量の増加率という時系列の特徴量を作成. 先行研究では, デマツイートは非デマツイートより速くリツイートされたという結果が得られている2. リツイートは, タイムライン上のツイートを再びツイートして共有する機能で, タイムライン上のツイートをフォロワーと共有したいときに使う.
時間ごとのリプライ数増加率: ツイート投稿後24時間までの毎時間のリプライ量の増加率という時系列の特徴量を作成. リツイート量のように, リプライ量もデマツイートと非デマツイートで違いがあるのではないかという仮説のもとこの特徴量を作成した. デマツイートには早いタイミングからデマに関しての注意喚起がされるのではないかと考えた. リプライは, ツイート内容に対するリアクションや意見など, ツイートをしたユーザー本人に向けてメッセージを送る機能で, リプライを送受信したアカウントをどちらもフォローしているユーザーのタイムライン上に表示されるものである.
モデル構築
チームは準備したデータを DataRobot Auto ML にアップロードして機械学習モデル構築を自動で行った. 具体的な流れは以下の通りである. (実際に人間が行う作業は予測対象の設定と開始ボタンの押下のみ)
- アップロードされたデータが想定通りであることを各特徴量の分布を見て確認した後, 「デマフラグ」を予測する対象として設定
- 開始ボタンを押して, 2値分類モデルの構築を開始
- DataRobot Auto ML が自動で欠損値の補完やカテゴリ特徴量の数値化, また, ほとんどが欠損の特徴量や値が一つしかない特徴量の削除を実施
- DataRobot Auto ML はデータを5分割し5フォールドの交差検定を実施. 80%のデータが学習に使われ, 20%のデータを検定に使用
- 学習データを使用して複数のモデルが構築され, 学習には使用されていない検定データで, 構築されたモデルの精度を評価
モデリングが開始されると, DataRobot Auto ML はデータの前処理と機械学習アルゴリズムの組み合わせを決める, ブループリントと呼ばれる「機械学習の設計図」を自動作成する.
- データ前処理: 欠損値やカテゴリ特徴量の処理, 主成分分析やクラスタリングといった処理, 2つの特徴量の差と比の計算, 日付特徴量から曜日や月の抽出, テキストマイニングや画像の特徴量化など
- 機械学習アルゴリズム: ディープラーニングを含むニューラルネットワーク系のアルゴリズム, XGBoost やランダムフォレストなどの決定木系のアルゴリズム, また回帰系のアルゴリズムやk近傍法そしてナイーブベイズやサポートベクターマシーンなど, ありとあらゆるアルゴリズム
DataRobot Auto ML が作成したブループリントでの「勝ち抜き戦」が行われ, 最後に, 精度の良いモデルをブレンドしたブレンダーモデルも自動生成された. 最終的に54個のモデルが構築され, 精度の良い順にリーダーボード上に表示された.
モデル選択
交差検定での精度をもとにモデルを選択した. 交差検定での精度とは, 5回の検定での精度の平均である. この取り組みでのモデルの活用イメージは, リアルタイムでデマ判定結果を自動的に Twitter に反映するのではなく, 毎日処理しきれない数のファクトチェックをしている人をご支援する目的で, モデルのデマ判定結果をもとにチェックするツイートを絞り込むというものだ. よって, リアルタイムでデマ判定をするための予測の速度よりも, モデルの精度を重視してモデルを選択した.
モデル選択のための精度パフォーマンスを評価するための指標としては, AUC を採用した. AUC は2値分類でよく使われる指標で, ランダムなモデルであれば0.5, 最も精度の良いモデルであれば1.0になり, 直感的に分かりやすい. デマ判定をするにあたっては, ある閾値以上の予測値のものをデマと判定した場合に合っているかどうかが重要なので, 順位をつけた際に正解した割合を考慮するべきであり, AUC が適切と考えた.
モデル評価
上述のように選択したモデルの精度パフォーマンスは AUC で表されているが, AUC はモデルの総合的な精度を示してくれるものの, この一つの値のみでは, モデルの精度の一貫性や, モデルの予測値に基づいて意思決定した際の正確さはわからない. そこで, DataRobot が出力する混同行列を使用して, モデルのパフォーマンスをさらに深堀りした.
混同行列とは, モデルの予測結果と, 実際の実測値によって場合分けし, それぞれの場合が起こる件数をまとめた表である. デマ(+)/非デマ(-)のどちらかを予測するような2値分類モデルでは, 以下のように混同行列は2×2=4通りのケースパターンを表す(図3).

True Positive(TP):モデルがデマ(+)と予測し, 実際にデマ(+)であった件数
False Negative(FN):モデルが非デマ(-)と予測し, 実際はデマ(+)であった件数
False Positive(FP):モデルがデマ(+)と予測し, 実際は非デマ(-)であった件数
True Negative(TN):モデルが非デマと(-)予測し, 実際に非デマ(-)であった件数
2値分類問題では, 実際のデマのうちいくつをモデルがデマだと予測できたかを表す「リコール」と呼ばれるカバー率(= TP /(TP+FN))と, モデルがデマだと予測したうちいくつが実際にデマであったかを表す「プレシジョン」と呼ばれる的中率(= TP /(TP+FP))がモデルの精度を評価する上でよく使用されている. 今回の取り組みでも, これらの指標でモデルを評価した.
モデル解釈
単にモデルの精度パフォーマンスだけを評価するのではなく, 「どの特徴量がデマ判定に重要であったか」, 「重要であった特徴量の値と予測の対象(デマツイートである可能性)にはどのような関係性があるのか」といった観点からモデルの解釈を行うことで, 分析前に立てていた仮説を検証できたり新しい気づきを得られるため, ひいてはモデルの信頼性向上にも繋がる. 特徴量とモデルの関係の確認にはDataRobot Auto MLの「特徴量のインパクト」と「特徴量ごとの作用」という機能が利用された.
特徴量のインパクトからは, 特徴量が予測精度に与える影響を確認できる(最も影響力の強い特徴量を100%とし, 他の特徴量の影響力が相対的に表示される). チームは仮説として重要であるとされている特徴量が本当に影響力の強いものとして捉えられているか, あるいは新しい気づきとなるような意外な特徴量が重要だと捉えられているかを確認した.
特徴量ごとの作用からは, 特徴量の値が変化したときに, 予測値がどう変化するかを確認できる. 例えば, ツイートのいいね数が0から100に変わるとデマスコアは約69%から59%まで急激に約10ポイントも低くなるという関係をみることができた. また, 特徴量ごとにモデルの予測値と実測値を比べることで, その特徴量のどの領域でモデルの性能が悪いのかを特定した.
さらに, 今回の取り組みでは, ユーザー名やプロフィール文がテキスト型の特徴量として含まれていたので, テキストマイニングが実行され, どの単語がデマツイート/非デマツイートであるかどうかと強い関係性があるのかを確認した.
モデルからのアウトプットは確率値で表されたデマツイートの可能性であり, 「デマスコア」と呼べるだろう. スコアが高ければデマの確率が高く, スコアが低ければデマの確率が低い. 今回の取り組みでのモデルの活用イメージは, 手動でファクトチェックをする人の支援であるから, デマスコアに加えて, そのスコアに至った理由を説明できると, ファクトチェッカーに有力な情報を提供でき, モデルの信頼性の向上にも繋がる. DataRobot Auto ML には, 個々のスコアの理由を説明する機能がある. この「予測の説明」機能を使用して, ツイートのどのような特徴が高いデマスコア, 低いデマスコアに影響しているのかをスコア単位で確認した.
検証結果
モデルの精度
DataRobot Auto ML で多数のモデルを作成して精度を比較した結果, 最も精度の良かったモデルは, 交差検定での AUC が0.8893と最も高かった GLM Blender で, eXtreme Gradient Boosted Trees Classifier と Keras Slim Residual Neural Network Classifier と Neural Network Classifier を組み合わせたものであった(表3). 先行研究で, チリで起きた地震災害時のツイートを機械学習でデマ判定できるか検証した際, AUC は0.86という結果が得られている3. 今回の検証の方がモデルの精度が良いが, 異常なほどかけ離れているわけではない. アルゴリズムの種類, ブレンダーの構築, データの前処理などが先行研究との違いだ. また, 先行研究では, ユーザー名とプロフィール文は特徴量として使用されてないという違いもある. これらの特徴量がデマ判定に重要だという結果は, 日本特有かもしれないが, 今回の取り組みから得られた新しい気づきである.

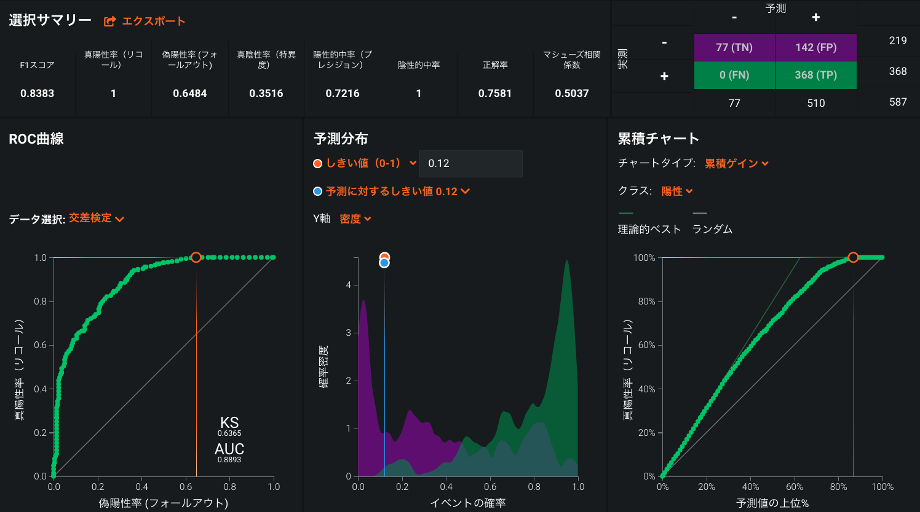
デマ判定モデルの使い方を考えたとき, 出来る限りデマツイートの取りこぼしは無くしたい. 実際にデマであるツイートは, モデルにデマだと判定して欲しい. このパフォーマンスは, 上述のようにリコールという指標で評価するが, もしリコールを1.0と全く見逃しをしない設定にした時に, デマと予測したツイートに実際にデマであるツイートがどれくらい入っているかを評価する指標であるプレシジョンがどのような値になるかを確認した. 最も精度の良かった GLM Blender では, リコールを1.0としたときのプレシジョンは0.7216であった. つまり, デマとモデルが判断したツイートのうち72%は実際にデマで, 28%は非デマツイートをデマと誤判断したということになる.
GLM Blender の精度をもう少し細かく見ていきたいと思う. DataRobot Auto ML は, 作成した全てのモデルで, 混同行列や ROC 曲線, 予測の分布を可視化している(図4). 図4の右上にある混同行列を見てみると, 交差検定で使われた587件のツイートのうち, 510件をデマだと予測し, 残りの77件は非デマと予測している(これは, 見逃しがないようにリコールが1.0になる閾値を設定した時の数字であることに注意). 非デマとモデルが予測した中に, デマは一つも入っていない. 587件のツイートのうち77件は調査する必要がないということになる. 13%と大きい割合ではないが, 効率化に繋がるところだ. デマだと予測した510件のツイートのうち, 142件は非デマであった. これらのツイートは人が確認することになるが, デマスコアの高いツイートから調査することでより早くデマツイートを発見し対応できるかもしれない. デマスコアが最も高い10%のツイートを見たところ, 95%が実際にデマツイートで, 誤判断となった136件の非デマツイートは3件しか入っていなかった.
今回の検証では, デマの見逃しをしないという想定で, リコールを1.0としたときのプレシジョンで評価したが, 違う想定もあり得る. 例えば, ファクトチェックできるツイートの件数に上限がある場合, 予測でデマと判定される件数がこの上限内に収まるように閾値を設定することになる.
モデルと特徴量の関係
構築したモデルに関して知りたい情報の一つは, どの特徴量がモデルにとって重要なのかだ. すでに述べたようにチームは GLM Blender の特徴量のインパクトを確認した(図5). 実はこのモデルの精度に一番影響したのは, プロフィール文だった. 次に影響力があったのが, ユーザー名で, その下に添付 URL, いいね数, ツイート投稿曜日, フォロー数とフォロワー数の比, 総リスト登録数と続く. 時間ごとのリツイート数とリプライ数の増加率は, リツイート数増加率が特徴量のインパクトのグラフに出てきているが, 上位ではなかった. また, ポジネガ極性は, 1時間後の否定的なリプライ数が特徴量のインパクトの上位9番目に現れた.
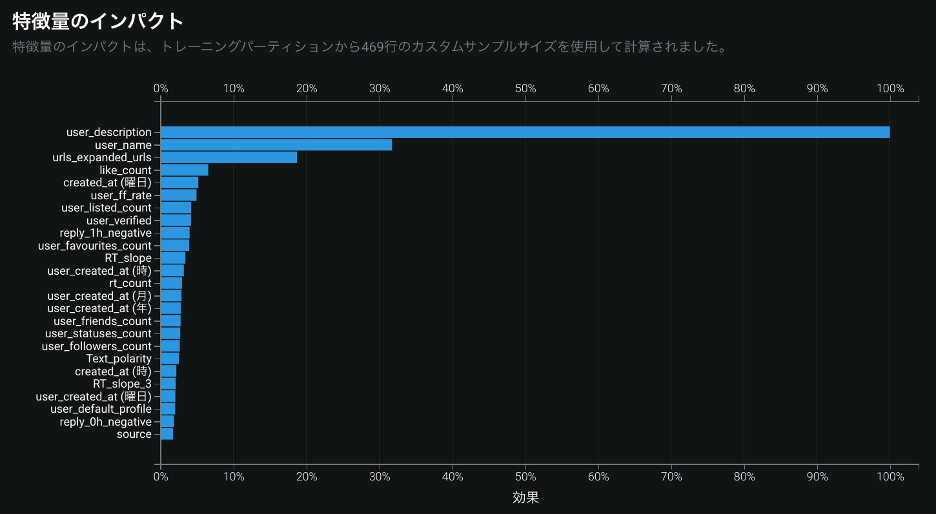
トップ3のプロフィール文, ユーザー名, 添付 URL はいずれもテキスト型の特徴量なので, チームは DataRobot Auto ML が作成したワードクラウドも確認した(図6). ワードクラウドでは, 単語が赤いほどデマである傾向が強く, 単語が青いほど非デマである傾向が強い. また, 大きさはその単語の出現頻度を表している.

ワードクラウドから得られた知見は以下の通りである. ツイートを拡散する前に, ユーザー名やプロフィール文を確認すると, ツイートの信頼性を判断するために使える情報が得られるかもしれない.
- プロフィール文とユーザー名に, 「公式アカウント」や「ニュース」「市」といった単語が入っていると, 非デマの傾向がある
- プロフィール文に「です」や「ます」が使われていて丁寧であると非デマの傾向がある
- プロフィール文が入っておらず「nan」になっているとデマの傾向がある
チームは次に, 特徴量のインパクトの上位4番目に現れている「いいね数」とデマスコア(デマツイートである確率)の関係も確認した(図7). ツイートへのいいね数が0から100に変わるとデマスコアは約69%から59%まで急激に約10ポイントも低くなっている. Twitter ではデマツイートへの注意喚起がされることもあり, デマツイートにはいいねがつきにくいと考えられる.
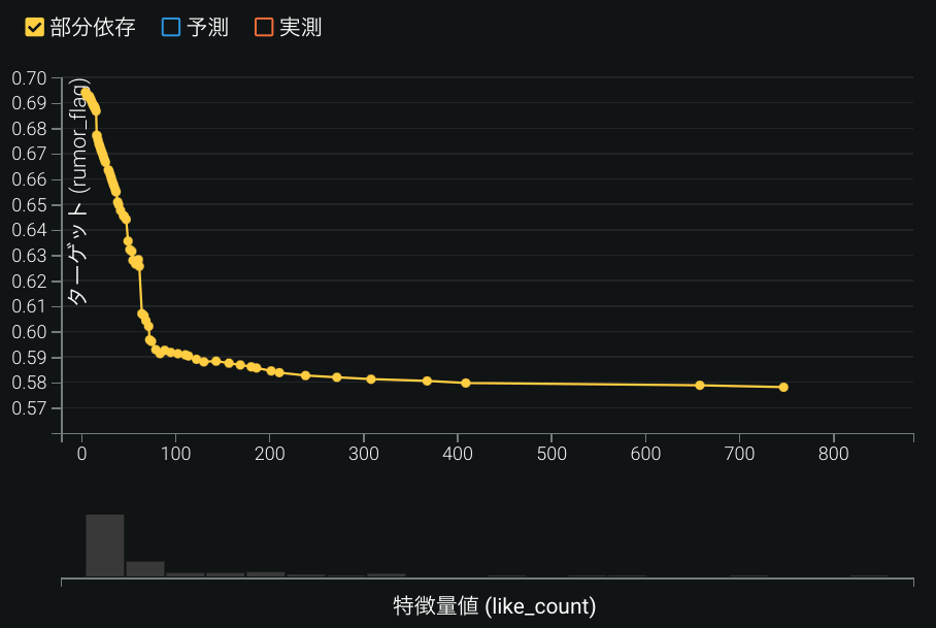
実際、デマツイートに対するリプライ13,505件と, 非デマツイートに対するリプライ3,702件の中身を分析してみると, 「デマ」という単語は, デマツイートのリプライには6.2%出現するのに対して, 非デマツイートのリプライには0.7%しか出現しない. 例えば, 「ひどいデマを拡散している方ですね. 早く訂正されないと. 」といったリプライがデマツイートには見られた. このようなデマツイートへの注意があり, いいねがつかない傾向にあると考えられる.
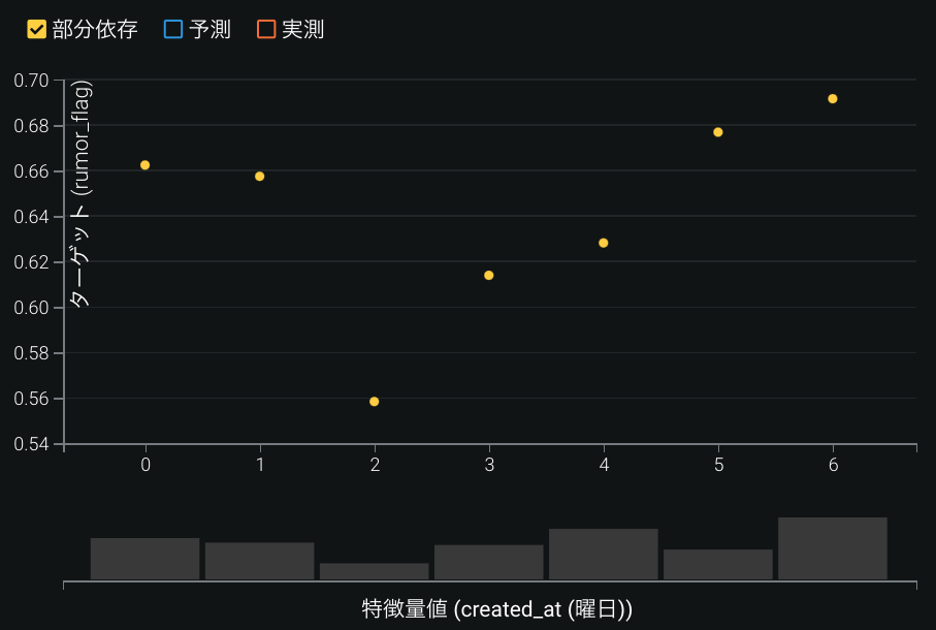
特徴量のインパクトの上位5番目に現れる特徴量は「ツイート投稿曜日」だ. こちらもデマスコアとの関係性を確認したところ(図8), 月曜日と火曜日はデマスコアが約66%で, 水曜日に約56%まで下がり、木曜日と金曜日で徐々にデマスコアが上がり、週末には約68%まで上がった. 週末は、ツイート数が全体的に増える傾向にあるので, デマの量もそれに合わせて増えると同時に, 企業や自治体などの, デマを拡散する可能性が低い公式アカウントのツイートが少なくなるのもあり, デマの確率が上がると考えられる. 月曜日と火曜日にデマスコアが高い理由としては, 週末に出たデマ情報が火曜日まではツイートされるのかもしれない. 実際に, 火曜日に投稿されたデマツイートには, ソースとなるツイートが週末に登場していたというケースもあった. しかしながら, 水曜日に突然デマスコアが下がる理由は, より詳細に調べないとわからない.
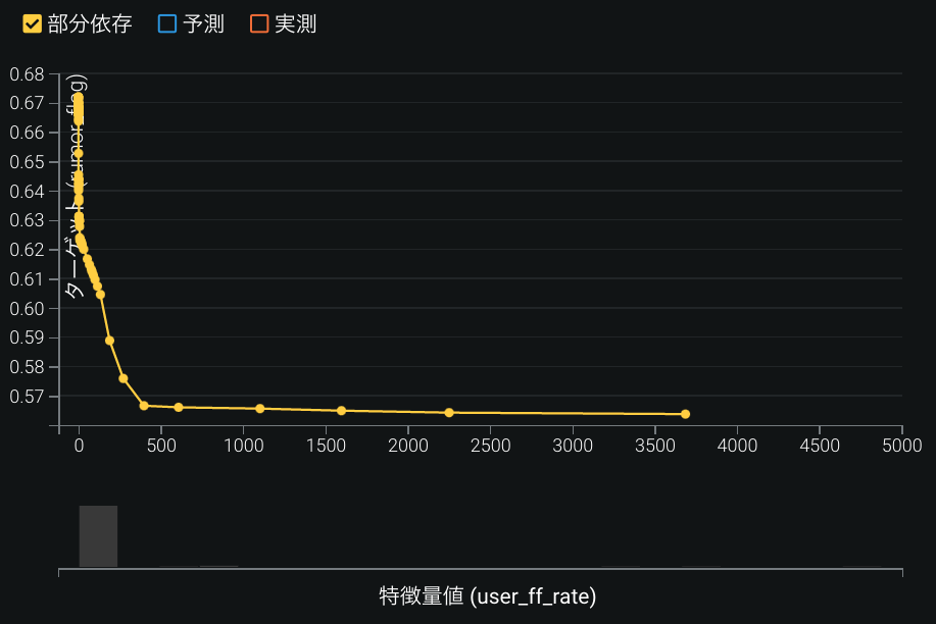
フォロワー数とフォロー数の比に関しては, フォロワー数がフォロー数よりも非常に多いトレンドセッタータイプが投稿したツイートはデマである確率がおよそ56%であるのに対して, フォロー数がフォロワー数より劇的に多いリスナータイプからのツイートはデマである確率が約67%となった(図9). トレンドセッタータイプは, 地域に頻繁にツイートし情報共有するような公式アカウントが多く, 内容を確認して情報を共有する傾向にあるのかもしれない. 逆に, リスナータイプは, あまりツイート投稿に慣れておらず, 緊急時に人助けをしたいという思いで, ファクトチェックをせず有力そうな情報を共有してしまう傾向があるのかもしれない.
特徴量のインパクトの上位7番目に現れる特徴量は「総リスト登録数」だ. こちらもデマスコアとの関係性を確認したところ(図10), 他のユーザーが作成したリストに数多く入っているユーザーほど, 投稿するツイートの信ぴょう性が高いという傾向があった. 総リスト登録数が0件から約1000件に増えると, デマスコアが約68%から60%まで, 8ポイント下がる. 提供する情報の信ぴょう性が高いため, 多くのユーザーに有益な情報発信者だと認識され, リスト登録されていると考えられる.
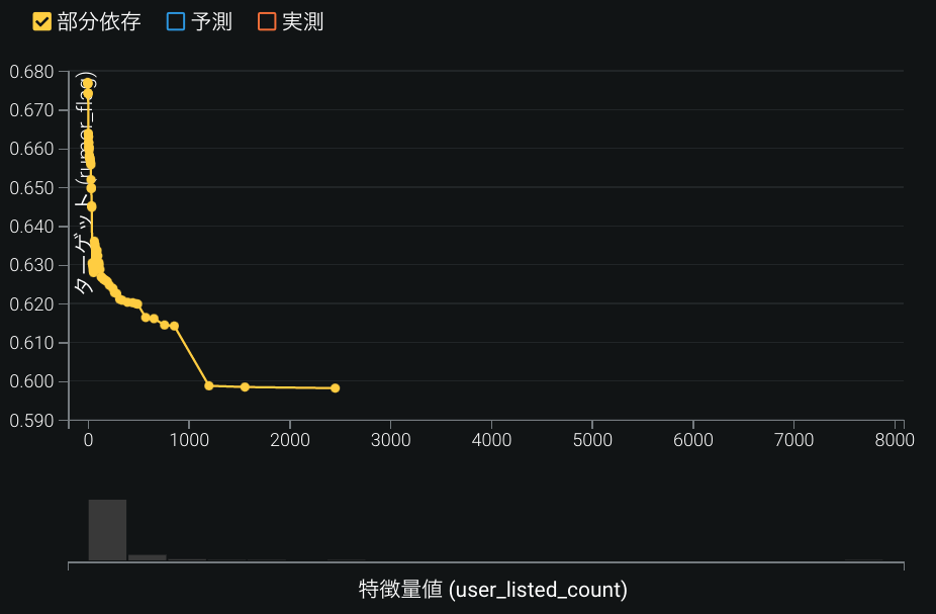
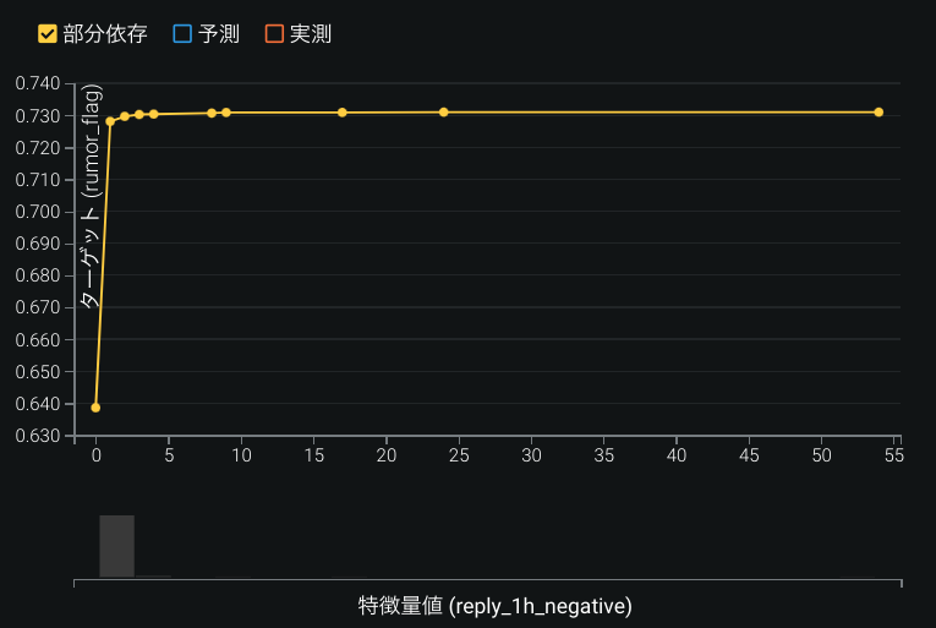
特徴量のインパクトの上位9番目に「投稿1時間後の否定的リプライ数」が現れた(図11). 投稿1時間後の否定的なリプライ数が0件の場合はデマスコアが約64%なのに対し, 否定的なリプライ数が3件あると, デマスコアが73%まで9ポイント上がるとわかった. Twitter 上では, 自浄作用が働いており, デマツイートにはリプライで注意喚起がされるため, 否定的なリプライの数が増えると考えられる.
デマスコアと特徴量の関係
機械学習でデマ判定をする際, 予測のスコアがアウトプットされる. デマスコアがある閾値以上のツイートはデマと判定され, そのようなツイートのみ人が調査をするというのが今回のモデル活用イメージだ. この時, デマスコアだけではなく, なぜそういうスコアになったのかの説明があると, 人が調査しやすいし, モデルの信頼性向上に繋がる.
図12は, DataRobot Auto ML の「予測の説明」という機能である. 上部のチャートは予測値の分布を示していて, 分布の青いところがデマの確率が低いケースで, 赤いところがデマの確率が高いケースを示している. 下半分の表では, デマスコアが最も高い3つの例と, デマスコアが最も低い3つの例をサンプルとして表示している. 予測されたデマスコアごとに, どの特徴量がそのスコアに対して重要だったかが重要度上位3個まで表示されている(何個まで表示するかは UI 上で変更できる). 例えば, 最もデマスコアが高いツイートは, (1)ある添付 URL が含まれており, (2)プロフィール文の内容と(3)総ツイート数によりこういったデマスコアになったと説明されている. 逆に, デマスコアが低いツイートを見てみると, 認定された公式アカウントであるといった理由で低いスコアとなっている.
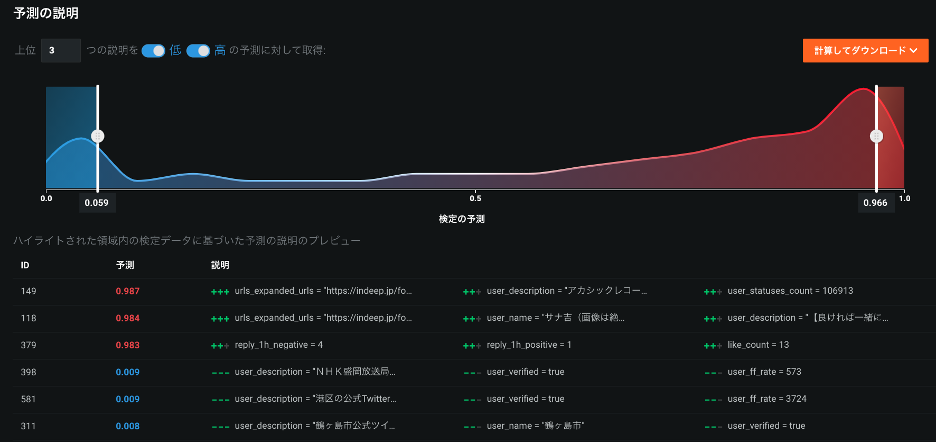
モデルと特徴量の関係をみる特徴量のインパクトで重要度上位に来ていた特徴量が, 予測スコアの説明でも重要な理由として上がっている. プロフィール文, ユーザー名, 添付 URL, いいね数, フォロワーとフォロー数の比の他にも, リプライのポジネガ極性や認証済みアカウントかが予測スコアの理由として上がってきた. このように, デマの信頼性を確認するファクトチェッカーに予測スコアに加えて予測理由を説明する情報を与えられれば, ファクトチェクの効率化をサポートできると考える.
ディスカッション
本検証を実施する中で, DataRobot Auto ML が出力した様々なインサイトをレビューし, 「ツイートへの反応」や「投稿者の情報」からツイートの信ぴょう性を確認する際のポイントを見つけられた. このセクションでは, 信頼できるツイートか見極めるためのポイントをまとめた後, 今後のモデル活用に向けて考えていることを紹介する.
デマ判定のポイント
- ユーザー名, プロフィール文の内容: ツイートの信頼性を判断するために, 投稿者のプロフィールやユーザー名を見ることは重要だとわかった.
- プロフィールを丁寧に記載しているアカウントが投稿したツイートの信ぴょう性は高い
- 情報発信や公式を謳っているアカウントが投稿したツイートの信ぴょう性は高い
- プロフィールを記載していないアカウントが投稿したツイートの信ぴょう性は低い
- ツイートへの反応: ツイートの信頼性を判断するために, いいね数と否定的なリプライ数を見ることは重要だとわかった.
- いいね数が少ないほど, 信ぴょう性は低い
- 投稿後1時間など, 早いタイミングで否定的なリプライがされるツイートほど, 信ぴょう性が低い
- ツイート投稿者の情報: ツイートの信頼性を判断するために, ツイート投稿者の性質を見ることが重要だとわかった.
- フォロワー数がフォロー数よりも多い, 公式アカウントタイプほど, 投稿するツイートの信ぴょう性が高い
- フォロー数がフォロワー数より劇的に多い, リスナータイプほど, 投稿するツイートの信ぴょう性が低い
- 他のユーザーが作成したリストに数多く入っているユーザーほど, 投稿するツイートの信ぴょう性が高い
今後のモデル活用に向けて
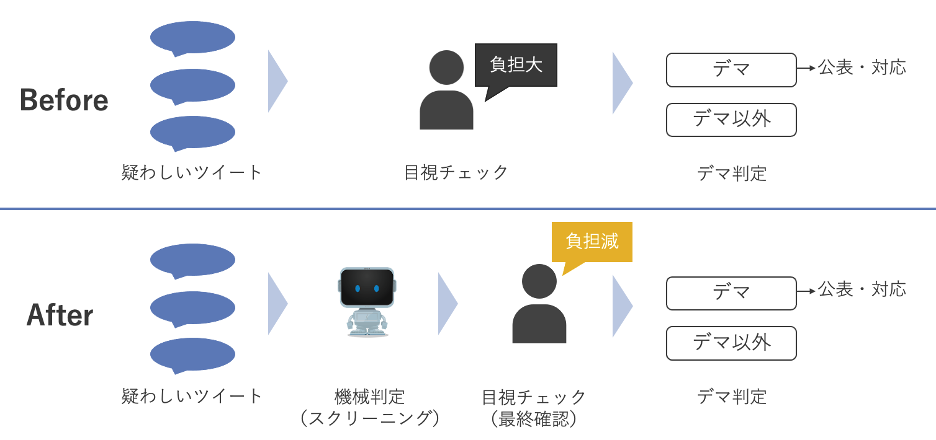
今回作成したモデルでデマを1つも取りこぼさずに判定しようとすると, デマと予測するツイートの中に28%ほど非デマのツイートが混ざることが分かった. この点を踏まえて活用用途を考えると, 信ぴょう性が疑われる大量の情報を人手で捌いているケースで, 今回のモデルをスクリーニングで活用すれば, 作業効率の改善を測ったり, これまで処理しきれなかった大量の情報に対処することが可能になると考える. 本検証でのシミュレーションでは、スクリーニングによる負担軽減効果は13%で、予測デマスコアの高いツイートから調査するようにトリアージすることで、対応速度の改善に繋がるという結果となった.
今後, 機械学習モデルをデマ判定に活用していくためには, さらなる検証が必要である. まず, 今回はDataRobot の COVID-19 プログラムでライセンスを使える期間の中で検証する必要があったため, 限られた時間と人でデマか非デマかのラベル付けを行った結果, 学習用データとして587ツイートしか準備できなかった. しかしそれでも先行研究で報告されているより精度の高いモデルを構築できることが分かったため, より多くの新型コロナウィルス関連のツイートを学習データとして利用してデマ判定モデルを検証したいと考えている.
一方, チームはいつまでも検証だけを続けるのではなく, 実運用しながら改善していくという進め方がベストだと考えている. 今回, 精度パフォーマンスの観点では非デマをデマと判定してしまうという間違いをもっと減らしたいところだが, 実は先行研究で重要だと特定された特徴量で, 今回使用していないものがあるので, それらを試してみる価値がある.
- URL の情報: 今回の検証では添付 URL の深掘りを行わなかったが, 先行研究では 3, URL 先のウェブページが最も人気のあるウェブサイトのリストに入っていると, ツイートの信ぴょう性が高くなるという結果が報告されている. URL 先のウェブページが信頼できるかという情報を特徴量にして, モデルのデマ判定の精度を上げられるか検証したいと思う.
- 感性: 今回の検証ではポジネガ極性を特徴量として作成したが, 感性は含めなかった. 不安になるようなデマは特に拡散されやすいという先行研究結果もあるので, NTT データ社の「なずき」を使用して, 感性を特徴量として作成し, モデルの精度向上を試みたいと思う.
- 代名詞: 疑問符や感嘆符がツイートに含まれていたり, 一人称代名詞や三人称代名詞が使われているツイートは, デマである確率が高かったという報告がある3. このような特徴量を加えて, モデルによるデマ判定の精度を上げられるか確認したいと思う.
おわりに
このブログでご紹介した取り組みでは, Twitter の投稿や投稿者の情報を使い, 新型コロナウィルスに関するツイートのデマ判定をするモデル構築にトライした. 汎用性を持たせるために, ツイート本文を使わないアプローチを取ったが, 本文以外の情報のみで良い精度のモデルを構築できた. デマツイート判定の閾値をデマを一つも取りこぼさないように設定すると, 多少非デマをデマと誤判定してしまうが, そこを改善しながら, ファクトチェッカーのスクリーニング支援という形の実運用化へ進める価値があるデマ判定モデルが構築できたと考える.
構築したモデルを解釈する中で, デマツイートの特徴を分析した. ツイートに対する反応情報や投稿者情報から, ツイートの信頼性を判断するために見るべきポイントを発見できた. プロフィールを丁寧に記載しているアカウント, 情報発信や公式を謳っているアカウントが投稿したツイートの信ぴょう性は高く, 逆に, プロフィールを記載していないアカウントが投稿したツイートの信ぴょう性は低い. また, 否定的なリプライがあったり, いいねが少ないツイートの信ぴょう性は低い. ファクトチェッカーだけでなく, SNSユーザー全員が, こういったツイートの特徴に気を付けながら, ツイートを共有するか考えていただけたら, SNS上の情報の質が上がっていくだろう.
最後に, チームメンバーにとっては, Twitter を使用してDataRobot で有益な分析を行えることがわかったというのも一つの発見だった. これから DataRobot x Twitter のユースケースを増やしていきたい.
プロジェクトチームメンバー紹介
中山忠明: プロジェクトリーダーとして全体をマネージ
株式会社NTTデータ ITサービス・ペイメント事業本部 SDDX事業部 マーケティングデザイン統括部 デジタルマーケティング担当。NTTデータにてリスクモニタリング領域における複数のシステム開発プロジェクトにプロジェクトマネージャーとして携わる。現在は Twitter 全量データをはじめソーシャルメディアを活用したマーケティング戦略立案・分析を製造、流通、金融など様々な企業に提供している。
夏 エイチュウ: 分析担当としてデータ準備、モデル構築、モデル解釈を実施
株式会社NTTデータ ITサービス・ペイメント事業本部 SDDX事業部 マーケティングデザイン統括部 デジタルマーケティング担当。中国出身。2019年に NTTデータに入社して以来、Twitter 全量データ活用に従事し、幅広い業種の企業をお客さまとして、マーケティング戦略立案・分析やリスクモニタリングなどに携わっている。
笠原 宏太: データサイエンティストとしてサポート
NTTデータ ビジネスソリューション事業本部 AI&IoT事業部 コンサルティング担当主任。大学院時代に素粒子物理学を専攻し、CERN(欧州原子核研究機構)で暗黒物質の研究に貢献。博士号取得後、NTTデータに入社し大手製造業様向けのデータ分析案件や、自然言語処理関連の分析案件に従事。DataRobot や NTT研究所開発技術 corevoを活用し、分析設計~業務への実装までトータルでの支援を行い、定着化を実現してきた。DataRobot 認定 Customer Facing Data Scientist。
坂本康昭: データサイエンティストとしてサポート
DataRobot データサイエンティスト。2005年にテキサス大学にて認知科学博士号取得。スティーブンス工科大学での教授職時代に SNS 上での情報共有に関する研究を含む50を超える学術論文を出版、データサイエンスプログラム立上げメンバーとして貢献。2015年に日本に戻り、保険会社でチーフサイエンティストとして AI の応用に従事。2017年から DataRobot のデータサイエンティストとして金融、ヘルスケア、製造など様々な業界のお客様をサポート。
参考文献
- Mendoza, M. and Poblete, B. Twitter Under Crisis: Can We Trust What We RT? In Proceedings of the First Workshop on Social Media Analytics, 2010, 71-79.
- Tanaka, Y., Sakamoto, Y., and Matsuka T. Toward a Social-Technological System That Inactivates False Rumors Through the Critical Thinking of Crowds. In Proceedings of Hawaii International Conference on System Sciences, 2013, 649-658.
- Castillo, C., Mendoza, M., Poblete, B. Predicting Information Credibility in Time-Sensitive Social Media. In Internet Research, Vol. 23, Issue 5, Special issue on The Predictive Power of Social Media, 2013, 560-588.

DataRobot データサイエンティスト。2005年にアメリカの大学にて認知科学博士号取得後、教授職時代にデータサイエンスプログラムの立上げを経験。2015年に日本に戻り、保険会社で AI の応用に従事。2017年から DataRobot のデータサイエンティストとして金融業界のお客様をサポート。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事