プロジェクトアサインを予測モデル搭載チャットボットで解決する
DataRobotでデータサイエンティストをしています小川幹雄です。
社内のハッカソンでDataRobotを活用したチャットボットを作成したのでそのことについて紹介します。
背景
弊社のプロジェクトはJIRAというチケットシステムで内容や担当者、進捗状況などが管理されています。下の図は横軸が時間になっていて縦軸がチケットの件数になっています。そして各チケットのプロジェクト種別ごとに色分けしています。図で確認できるように、始めは単純な進捗管理だけでプロジェクトに別れていなかったのですが、人や組織、機能が増えたことによってプロジェクトの細分化が発生しています。またチケットの件数自体も増加傾向にあります。
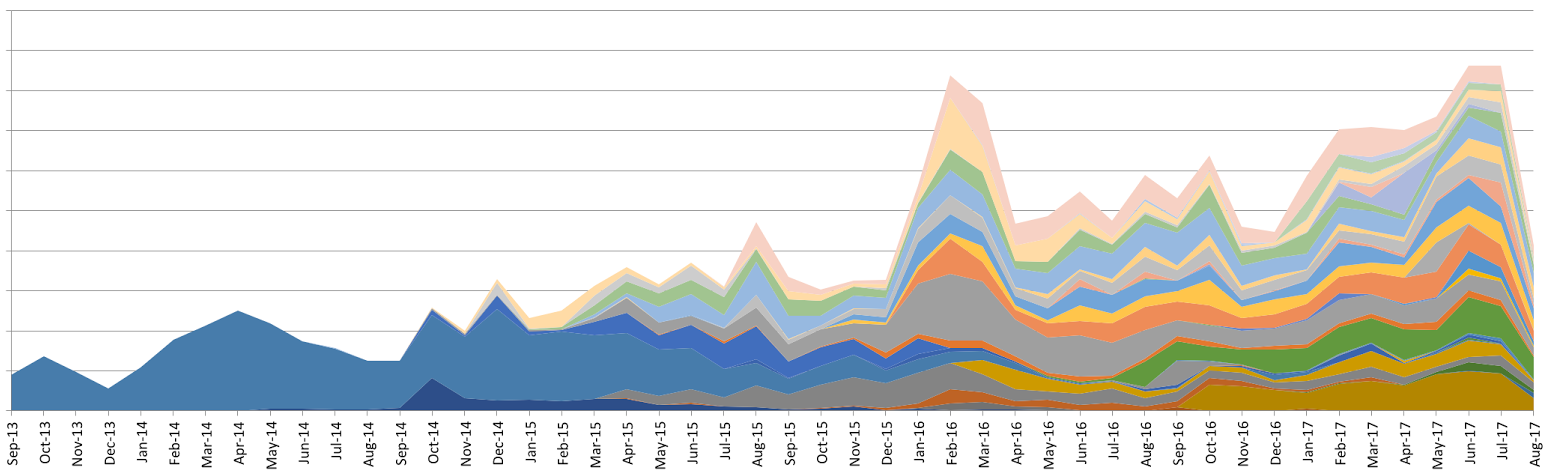
会社自体が急激に成長している中で、新しい人がどんどん入社しています。新しい人は問い合わせ先がどのプロジェクトチームなのかを覚えるのも一苦労で、問い合わせを受けるプロジェクトチームも自分たちが担当でない問い合わせを受けるのは時間の無駄となります。
このような問い合わせ先のディスパッチはどの企業でも多かれ少なかれ問題になると思います。今回はハッカソンの一環として、チケットシステムにある過去データからどのプロジェクトになるかを予測する機械学習モデルを作成し、問い合わせに対しての答えを返してくれるチャットボットを作成することにしました。
弊社は社内チャットツールとしてはSlackを利用しているため、チャットのインターフェースとしてはSlack、機械学習エンジンとしてはもちろんDataRobotを利用しました。元のデータはJIRAからAPIを利用して取得しています。
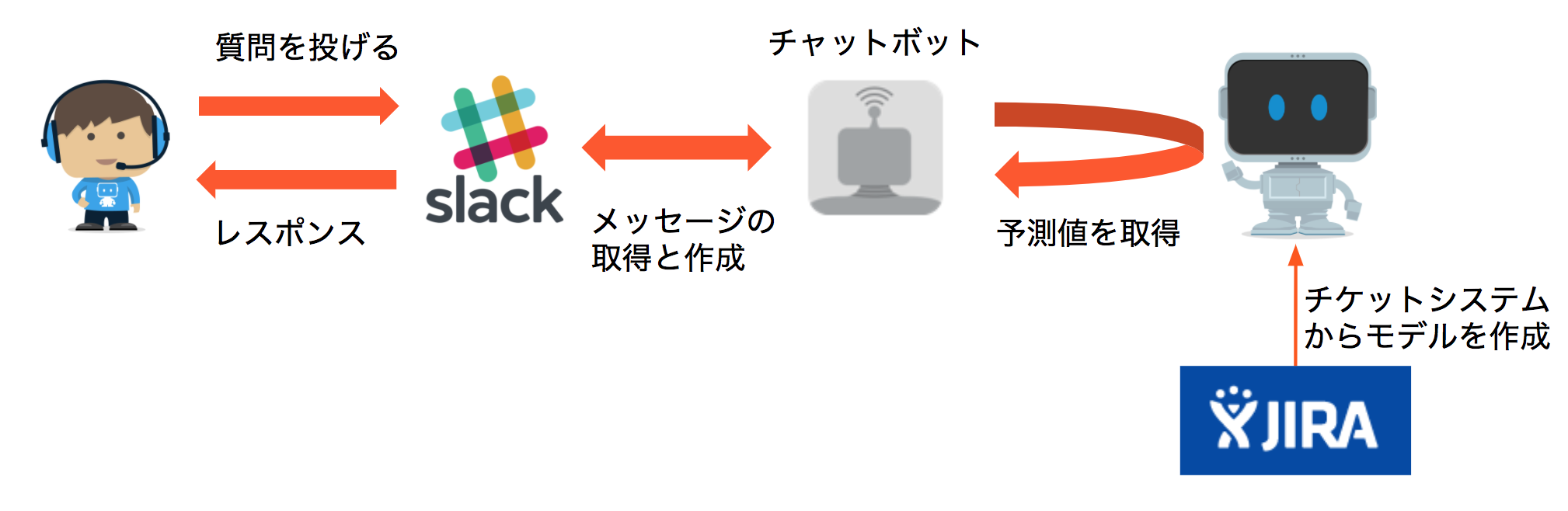
学習データと予測モデルを作成する
学習データ取得と定常化
まずは予測モデルを作成しないといけないので、チケットシステムからデータを抜き出してきます。一件一件チケットを手動で抜くわけには行かないのでJIRAのAPIを活用しました。普段あまり利用しないAPIを利用することは、どんなデータ形式でどんなデータが抜き出せるのか把握するのは大変ですが、学習データの作成をスクリプト化しておくことによって、今後データが増えた際にデータの再収集が楽になります。参考までにJIRAのAPIでデータを抜いて来た時のコードを紹介します。コード化することによって、今後新しいチケットができた場合にも同じコードでデータを簡単に収集することができます。
[sourcecode language=”python” wraplines=”false” collapse=”false”]
import pandas as pd
from jira import JIRA
JIRA_USERNAME = ‘mikio.ogawa@datarobot.com’
JIRA_PASSWORD = ‘XXXXXXXXXXXXXXXXXXXXXXXXX’
JIRA_URL = ‘https://atlassian.net/’
def get_jira_client(**kwargs):
jira_client = JIRA(JIRA_URL,
basic_auth=(JIRA_USERNAME, JIRA_PASSWORD),
**kwargs)
return jira_client
def get_feature_from_issue(issue):
Key = issue.raw[“key”]
ProjectName = issue.raw[“fields”][“project”][“name”]
Summary = issue.raw[“fields”][“summary”]
Description = issue.raw[“fields”][“description”]
d = {‘Key’ : Key,’ProjectName’ : ProjectName,’Description’ : Description,’Summary’ : Summary}
df = pd.DataFrame([d])
return df
jira = get_jira_client()
df = pd.DataFrame([])
for startnumber in range(0, 80000, 100):
issues = jira.search_issues(‘status IN (“Resolved”,”Closed”,”Done”)’,
startAt=startnumber, maxResults=100,fields=”summary,description,project”)
for issue in issues:
tmpdf = get_feature_from_issue(issue)
df = df.append(tmpdf, ignore_index=True)
print(startnumber)
df.to_csv(‘training.csv’,index=None,header=True)
[/sourcecode]
学習データ作成で気をつけるポイントとしては、JIRAには、チケットが登録されてからのコメント、アサインされた人、添付ファイルなど様々な情報が記録されています。ただ今回の目的としては、チケットを登録するときにどのプロジェクトチームに向けて登録するかを教えて欲しいチャットボットを作ることです。そのため、チケットを登録する瞬間で得られる情報だけで学習データを作っていきます。
リーケージなどの学習データのクオリテチェック
元々はチケットを登録した際の区分(新機能リクエストなのか、不具合報告なのか)もやくにたつと思ったのですが、最初に選んだプロジェクトによって、入力可能な区分に制約があり、リーケージとなっていたため除くことにしました。劇的に精度が高くなるわけではなく、見つけづらいリーケージでしたが、このようなものもしっかりと除いて汎化性能を高めます。また、チケットの中には未対応、対応中、完了などのステータス情報があります。未対応や対応中のものに関しては、チケットが進むに連れてプロジェクトが変わる可能性があるため、ステータスが完了のチケットのみを学習データで使用します。状態が揺らぐものを除くことによって学習データの質をよくします。さらに調べていくとプロジェクトの中にはもう解散したプロジェクト、マージされたプロジェクトが存在したため、解散したプロジェクトのデータは除き、マージされたプロジェクトはデータの方もマージしました。
予測モデルの作成
ここまでくればモデルを作るパートとしては、DataRobotは多値分類に対応していて、テキストデータもそのまま分析に使用することができるので、学習データを放り込んで開始ボタンを押すだけです。*DataRobotでは現時点では10カテゴリまでをサポートしていますが、社内プロジェクトのため、特別に30カテゴリまで拡張しています。
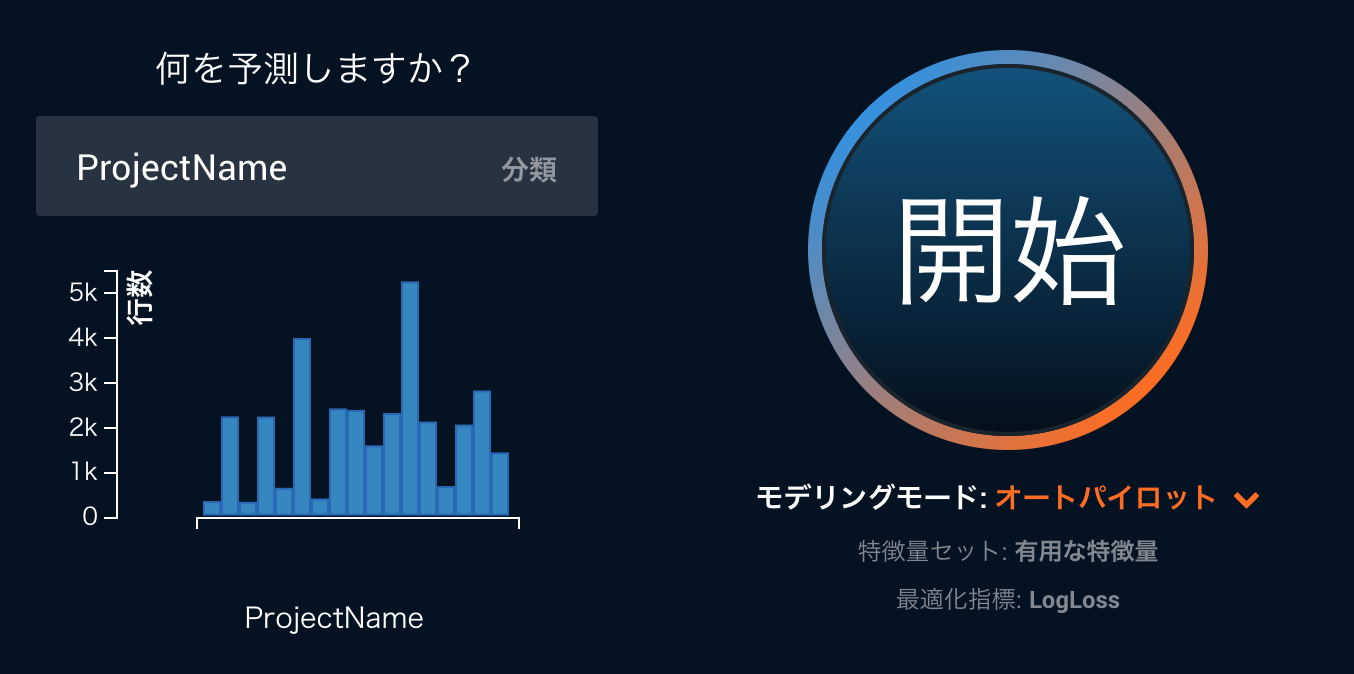
予測モデルを確認
作成した予測モデルが実際に使えるものか確認します。
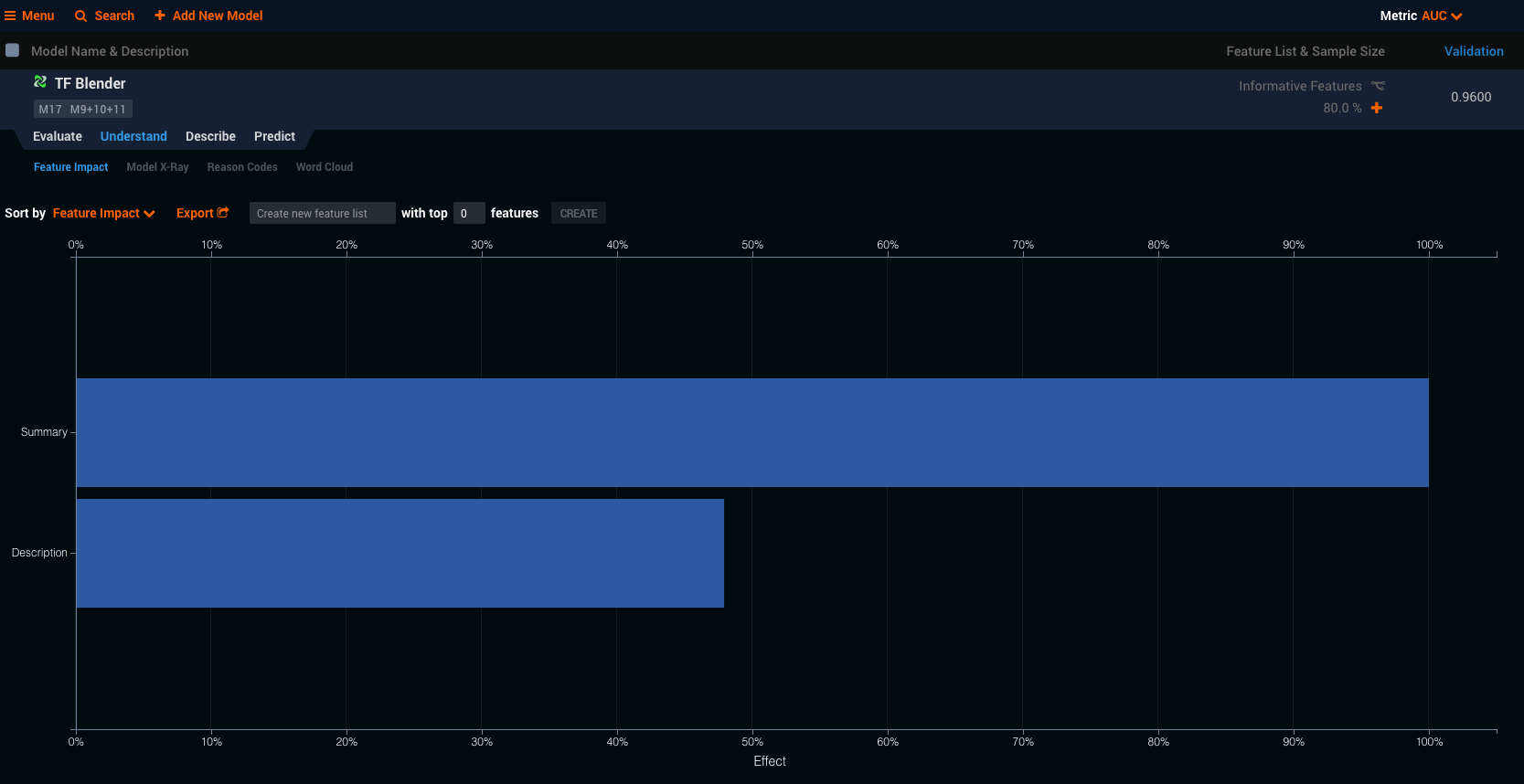
トップのモデルはTensorFlow Blender AUC 0.96。これだけ見るとおかしいくらい良いモデルに見えますが、元々難しい未来を予測しているのではなく、専門のエンジニアがテキストを見ればほぼ間違いなく正しいプロジェクトに割り振れるので妥当な数字です。特徴量のインパクトを見ると文字量のわりにSummary(要約)が、Description(詳細)に比べて倍以上効いている結果になりました。ちゃんとタイトルに情報を短くまとめられている証拠かもしれません。テキストの文字数、添付ファイルの拡張子などのフューチャーエンジニアリングも実施しましたが、精度にほとんど影響を与えられず、その割にコードの修正、予測時の入力の手間が増えるのでシンプルにSummaryとDescriptionだけを特徴量として使用することに決断しました。
作成した予測モデルのプロジェクトごとのAccuracy(正解率)を予測としてトップに出てくる一つ(Top1)だけで当てた場合、Top2で当てた場合、Top3で当てた場合で積立棒グラフでプロットしました。
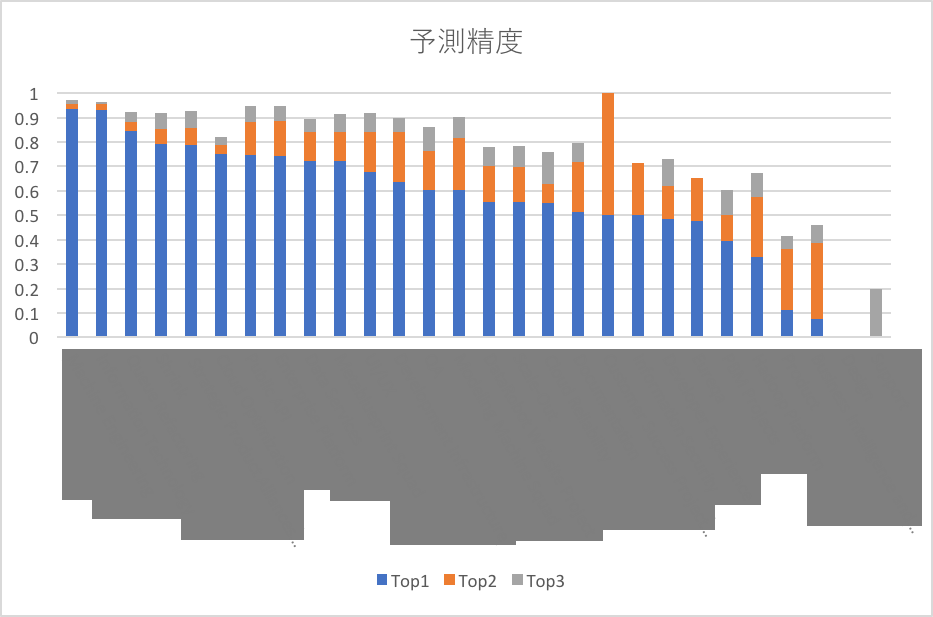
比較的当てやすいプロジェクトはTop1で80-90%を超えていますが、50−60%付近のものも多くあります。Top2にすることによって、だいたいのプロジェクトが70%を超えてきて、Top3にするとほとんどが80%を超えてきます。二つほど異常に低いプロジェクトがありますが、件数も少なく中身を確認するとどう見ても他のプロジェクトと同じ内容であったので、ここは社内で再度確認が必要という課題も見つかりました。全体のAccuracyだと、Top1で71.1%、Top2で84.2%、Top3で90.4%という精度になりました。
予測値としては、一番高い確率に予測されたプロジェクト名だけを返すのが当初の予定でしたが、それだけだと精度が要件を満たせないので、トップ3のプロジェクト名を返すようにプランを変更しました。予測モデルの確認が完了したので、100%の学習データで再学習させて予測モデルの準備は完了です。
Slack Bot(チャットボット)の作成
Slackのアカウントがあれば、こちらからボット用アカウントを作成できます。ボットを作成すると、APIトークンが確認でき、ボットのサムネイル画像などを設定できます。APIトークンはコードからボットを認証させるのに使用するので、大切に保管しましょう。
Slackにはボット用のAPIが用意されており、様々なプログラミング言語に対応したSDKがこちらに提供されています。今回はデータセット作成でPythonを使用していたので、そのままPythonのSDKを利用しました。
Slack Botコードを作成
Slack Botの動きとしては、サーバでボット用のプログラムを作成しておくと、Slackのトークにポーリングを行い、特定のメッセージに反応して動作します。業務で利用するため、そこまでフランクな話しかけなどに対応する必要はなく、ボットに対して直接、SummaryとDescriptionを問いかけると予測モデルを使用して該当しそうなプロジェクトをトークに返してくれるようにします。
メインのコードだけを紹介します。実際のコードでは初期設定、ロギング、エラーハンドリングも実装していますが、キーポイントだけピックアップしたものにしています。
[sourcecode language=”python” wraplines=”false” collapse=”false”]
class PredictionBot(object):
def __init__(self, slack_client, datarobot_client):
self.datarobot_client = datarobot_client
self.slack_client = slack_client
self.bot_id = slack_client.api_call(‘auth.test’)[‘user_id’]
def do_predictions(self, channel, message):
summary, description = message.split(‘n’, 1)
self.say(
channel,
‘Ok, please give me a minute to think about it :thinking_face:’,
)
try:
predictions = self.get_predictions(summary, description)
except Exception as e:
msg = ‘I am sorry but I am puzzled with your request :dizzy_face: `%s`’ % e
self.say(channel, msg)
return
if predictions is None:
self.say(
channel,
‘Something went wrong with this prediction. I am sorry about that :confused:’,
)
return
most_probable = predictions[:3] # top 3 predictions to show
context = itertools.chain.from_iterable(most_probable)
context = [i if type(i) == str else i * 100 for i in context]
response = (
‘I think it should belong to `{1}` with {0:.2f} accuracy :nerd_face:’
‘or `{3}` with {2:.2f}%, `{5}` with {4:.2f}%’
).format(*context)
self.say(channel, response)
def event_loop(self, sleep_time=0.5):
while True:
events = self.slack_client.rtm_read()
if not events:
time.sleep(sleep_time)
continue
for channel, message in self.parse_events(events):
if message.startswith(‘ self.do_switch(channel, message)
elif self.validate_request(message):
self.do_predictions(channel, message)
else:
self.say(
channel,
‘Sorry but I am puzzled. I have expected at least two lines as input. ‘
‘The first line stands for summary and all the rest for a description’,
)
if __name__ == ‘__main__’:
# Slack
slack_token = os.environ.get(‘SLACK_TOKEN’, ”)
slack_client = SlackClient(slack_token)
bot_id = slack_client.api_call(‘auth.test’)[‘user_id’]
# Datarobot
datarobot_token = os.environ.get(‘DATAROBOT_TOKEN’, ”)
datarobot_endpoint = os.environ.get(‘DATAROBOT_ENDPOINT’, ”)
datarobot_client = dr.Client(
endpoint=datarobot_endpoint,
token=datarobot_token,
)
# Default PID,LID
pid = os.environ.get(‘PROJECT_ID’, ”)
lid = os.environ.get(‘MODEL_ID’, ”)
# Setup and run main loop
bot = PredictionBot(slack_client, datarobot_client)
bot.setup(pid, lid)
bot.event_loop()
[/sourcecode]
Slackイベントのポーリング
event_loopから見ていくと、events = self.slack_client.rtm_read()と出てきますが、これはSlackのAPIを利用してイベントが発生しているかポーリングを行なっていきます。イベントが発生していなければスリープに入るようになっており、発生していればその条件にそってアクションを実行し、do_switchとdo_predictionsのどちらかを実行します。
モデルの動的切り替え機能
do_switchはメッセージがurlだとDataRobotで使用するモデルを切り替える機能を仕込んでいます。モデルは一度作成したら終わりでなく、時間とともに劣化していくもののため、継続的に作成し直していく必要があります。作り直すたびにボットを停止させるとメンテナンスが大変なためこの機能をつけました。

プロジェクトの予測
do_predictionsは2行からなるメッセージの1行目をSummary、2行目をDescriptionと認識して、予測モデルを利用してどのプロジェクトに該当するかの確率を返します。DataRobotの予測コードに関しては、以前にブログで書いていますがハッカソンでも例文とほぼ同じものを利用しています。DataRobotは実際には今回のような多値分類の際には該当する全てのクラスに所属する確率を返しますが、先ほどの精度のレベル的にトップ3までを返すように設定します。

今後のプランとまとめ
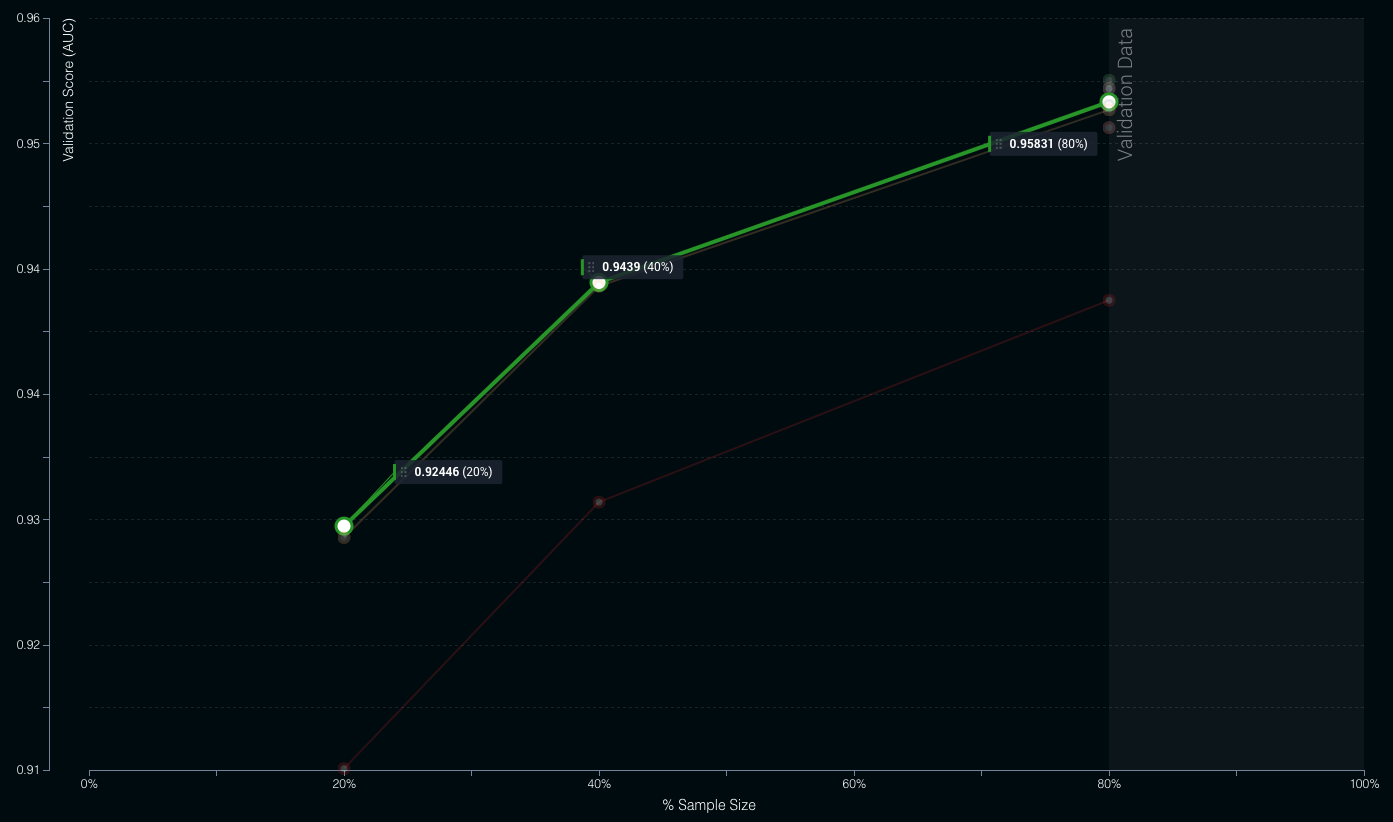
学習曲線を見た所、より多くのデータが溜まっていけばさらなる精度向上が望めます。DataRobotでは学習データを増やす価値がどれくらいあるかも一目でわかる機能を設けていますので、この点も今後のプラン作りに役に立ちます。新しいモデルを作成した場合には、モデルのスイッチ機能を利用すればダウンタイムなしでモデルを更新することができるので、数ヶ月後にはモデル更新を予定しています。
今回のSlack Botの仕組みは別のチケットシステムにも応用ができそうだとすでに実験が始まっています。他にもチケットがどれくらいで解決するのかの解決目安を予測するとかアイディアはつきません。
機械学習プロジェクトにおいて最後のデプロイにつまずくことはよくあります。チャットボットなら比較的簡単に実装できるので、本当のビジネス実装前の試験運用に有効なアプローチとなります。機械学習のモデルをデプロイする一つの手段として皆さんもぜひチャットボットに挑戦して見てください。

DataRobot Japan 3番目のメンバーとして参加。現在は、金融業界を担当するディレクター兼リードデータサイエンティストとして、金融機関のお客様での AI 導入支援から CoE 構築の支援を行いながら、イベント、大学機関、金融庁、経産省などでの講演を多数実施。初期はインフラからプロダクトマネジメント業、パートナリング業まで DataRobot のあらゆる業務を担当。前職はデータマネジメント系の外資ベンダーで分析ソリューション・ビッグデータ全般を担当。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事