
ものづくり現場でのAI利活用 (課題と機会)
はじめに
DataRobot で製造業のお客様を担当しているデータサイエンティストの顧です。近年、製造業のものづくり現場においてAI/機械学習が生産性向上に大きく貢献したというユースケースが次々と発表されています[1]。しかしながら、AI 導入初期の成功(第一の矢)を社内で横展開し、二の矢、三の矢を放つ際、徐々に停滞してしまう傾向があります。
例えば、ある部品の検品工程(表面仕上げの良/不良判定)で機械学習を活用した画像による自動判定が成功したとしましょう。他部品の検品工程でも同じ仕組みを利用したい、あるいは組み立て工程など、他の工程でも機械学習を活用したい場合、画像判定の仕組みをそのまま流用する程度であれば比較的容易に実現できるかもしれませんが、画像データだけでなく加工中の設備のセンサー値や前工程の情報も活用したいとなると、現場で運用するまでに膨大な準備期間が必要になる可能性があります。
本稿では、ものづくり企業がAIを活用して継続的に成果を出し続けるためのポイントについて考察します。
ものづくり現場で行われてきた改善の取り組み
日本のものづくり企業には改善の文化が根付いています。
生産ラインを立ち上げる際には、設備とその配置、そして発生し得る課題を生産ラインの設計段階から十分に検討し、問題の発生を未然に防ぎます。そのため本番稼働(量産)の前には既に、安定生産をするための製造条件の調整や、製造不良、設備の故障などの分析はある程度分析・定型化されており、ノウハウが蓄積されているケースが多いでしょう。
このように、ものづくり現場における不具合要因分析や設備の長寿命化などと関連する課題の大半は、上記のような絶え間ない改善活動と生産方式の見直しや、想定される問題を予測して対策を打つための未然防止フレームワークである DRBFM[2] の導入などにより、量産時には多くが既に解決されています。一方、近年、データ収集の手段が増える中でファクトリー IoT などが登場し、先進的なものづくり企業ではさらに高い品質・生産性レベルを達成するためにデジタルデータ活用を推進する動きも活発になっています。
製品を安定的に量産するための課題
データ量と因子数の増加
年々機能が複雑化・高度化する製品の歩留まりを維持するため、生産現場では分析官の工数も含め膨大なリソースが割かれています。経験豊富な分析官が、品質管理課題に時間をかけて念入りに取り組めるのであれば、伝統的な統計的品質管理手法(SQC)で解決できる課題も依然多いでしょう。
しかしながら現実は複雑化する生産条件に関する情報や、スマートファクトリー化で新たに収集されるようになったセンサーデータなど、従来は十分に活用できていなかった情報も収集できるようになり、分析対象データが膨大になってきています。このような状況下で、弊社ユーザー様からのご相談をお聞きしていても従来の SQC 手法だけでは対応できる範囲に限界が出てきているのも事実です。
予防保全の限界
これまでも生産設備では消耗品などの部品を故障前に交換する「予防保全」を行ってラインの正常な稼働を維持してきました。当然、交換タイミング前に生産設備部品の故障が発生すると製造ラインの停止を招き、製造を停止している時間や加工ワークの廃棄、壊れた設備部品の交換だけでなく原因の特定や影響範囲の調査など、様々な損失が発生します。
しかし、こういった部品は個体ごとに寿命や不具合発生タイミングが異なり、これらを従来のアプローチで故障前に察知することは困難である場合も多いです。
AI 導入のメリット
多種多様なデータでも分析可能に
従来の統計的な手法では、主に10個以下程度の少数の変数(因子)を中心に分析するケースが多く、因子の数が非常に多い場合には、ドメイン知識に基づいて取捨選択していく必要がありました。(複数の因子の中から重要な因子を発見するために、ステップワイズ法のような統計的検定を繰り返して因子を絞り込んでいくアプローチも従来使用されてきましたが、多数の因子から絞り込む場合には多重検定のリスクがあって推奨できません[3])
一方で、機械学習を用いるアプローチではデータからどの因子が重要なのかをシミュレーションから解析的に確認することができます[4]。また、数値データ以外の稼働ログ等、例えばテキストデータも機械学習によって分析可能であるため、対象の幅とボリュームは増えていると言えるでしょう。
予防保全から予知保全へのシフト
工場の設備に対して決められた計画に基づいて部品交換や点検を行うのではなく、生産設備部品の状態を監視し、交換の予兆をつかむことで交換作業ができると、個体ごとのポテンシャルを発揮できると同時に、閾値による交換判断と比べて、使用寿命が短い個体の故障によるラインの異常停止や計画外交換に伴うコストを削減することができます。
熟練者の技能の継承と形式知化
原因と結果の因果関係を明らかにするための故障モードや要因の分析はドメイン知識と SQC 両方に精通した少数の専門分析官でなければ難しいというケースが多いでしょう。もちろん、IoT データを大量に収集できた後のフェーズであっても、因果関係を検証するために一番有効な手段が「ドメイン知識から導き出した因果仮説を実験によってテストする」であることに変わりはありませんが、熟練者の着目点を”模倣”するモデルを構築することで、そのモデルから得られる様々なインサイトを通じて若手の分析者がものづくり現場の深い知恵(暗黙知)をもっと形式知化して直感的に感じることができるようになります。それによって、AI 導入企業ではものづくり現場の技術者人材育成を大幅に効率化することができるでしょう。
AI で価値を出し続けるためのチャレンジ
前章まで、ものづくり企業の現場が近年直面している課題を AI 導入によって解決できると解説してきました。しかしながら、AI モデルを現場に導入することはゴールではなく、スタートラインに過ぎません。AI モデルは実運用フェーズで使われなければ価値を生みませんが、実は生産設備と同様、製造現場で運用する AI モデルには搭載可否検討や安定稼働のための保全計画が必要です。もしそれらを疎かにしていると運用の段階で必ず問題が発生します。
本章以降は、ものづくり現場に導入したAIを実際に運用して価値を出し続けるため必要となる考え方や具体的な方策を考察します。
予測機能だけでなく監視&トラッキングの仕組みが必要
AIモデルを現場で使うためには、様々な準備が必要です。工場ではインターネット接続ができず、通信速度も遅いケースが多いので、モデルを稼働するための端末が必要になります。端末や現場システムとの通信を含めて、インフラ周りの死活監視は必須です。
また、ものづくりの現場でトラックされている情報、例えば作業員の動線、設備の加工履歴などをAIモデルで使用している場合には注意が必要です。つまり、モデルを製造現場で使用するためには、同等の情報が必要になってきます。
さらに、AIモデルをものづくりの現場で使用する時にも、工場の設備と同様に時間、工程、ワーク、センサー波形、画像などの情報をインプットにし、判定結果をどのように行ったのか、などの「稼働情報」を履歴として保管しておく必要があります。
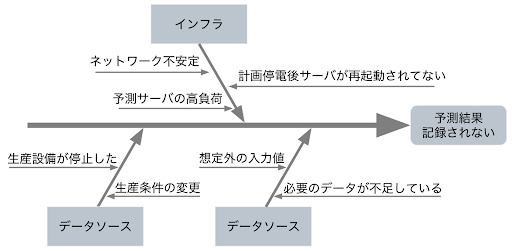
例として予測結果が現場の管理システムに記録されない事象を考えます。この問題には、インプットデータの異常やネットワークの疎通など、様々な要素が関係している可能性があり(下図1)、もし稼働情報がデータとして取られていなければ要因分析は困難でしょう。しかし、予測処理が実行されたタイミングと処理量のデータが取られており、例えば処理量が高い期間と予測を行えなかった期間が重なっていたら、予測サーバのキャパシティーを超えていた可能性があるので、サーバを増強するか、負荷分散する仕組みの導入が対策になり得ます。
このように、現行の仕組みでのAIモデルの稼働状況が監視され、稼働情報が記録されていれば、AIモデルの実運用時に発生する問題の原因特定が可能になり、再発防止策が有効なのかを判断する根拠にもなります。
現場の環境変化に追いつくためモデルも”成長”させる
AI モデルは作成された直後から精度劣化が始まると言われ、決して一度作成したらそれで終わりではありません。工場設備、例えば3次元測定器を使用する際には測定精度を保つため、曇り防止液の塗り直しなどレーザーのメンテナンスが定期的に行われていますが、AI モデルでも同様に、現場で使われているモデルが期待通りの精度を出しているのかを定期的にチェックし、精度劣化が発生したら、新しいデータを投入してモデルを再学習するなどの方法で精度向上の対策をとる必要があります。
AI モデル精度劣化の一つの要因として、予測に使われるデータが時間経過とともに変化してモデル作成時のデータと大きく乖離する現象があり、機械学習の領域では「ドリフト」とも呼ばれています。ものづくりの現場でも、例えば、測定器に流れてくるワークを2種類から3種類に増やした場合、新しいワークのどこが基準点なのか等、測定器のプログラムに新たに設定を追加する必要がありますが、AI モデルにおいても、新しく追加されたワークの品質を正しく判断するためには、該当データを追加しての再学習を行い、新たな情報をモデルに盛り込む必要があります。
モデル運用フローの事前設計
前章で予測データの変化を反映させるためにAI モデルへ新たなデータを加えてモデルを更新するケースをご紹介しましたが、その他にも例えば季節性がある場合などで、直近のトレンドを取り入れるためにモデルを定期的に再学習することがあります。その際には、新しいモデルができたらそのまま使うのではなく、しかるべき承認フローを通して、モデルの置き換えを行うべきでしょう。
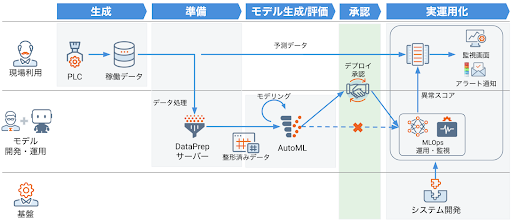
上図2は検査工程を例にして、AI モデルを現場適用する際のモデル運用フローのあるべき姿を表しています。定期的にモデルを再学習させる必要がある場合には、人を介入させずに再学習したモデルを自動で置き換えるようなモデルマネジメントのオペレーションも考えられますが、もし一度人が判断した上でどのモデルを使うかを決めていくオペレーションを採用するのであれば、モデル運用フローを予め設計しておくことが極めて重要になってきます。
多くの製造業企業が取り組んでいる統計的品質管理(SQC)の文脈でも、例えば工程の重要管理指標が管理限界線を超えた時にとるべきアクションフローを予め決めておく必要性が強調されていますが、モデル運用フローのコンセプトはこれと全く同じです。
DataRobot による課題解決
前述の通り、AI モデルは言わば生モノです、現場の業務プロセスで実運用して効果を出し続けるためにはモデル管理/監視の仕組みを持ち、モデルを環境変化に合わせて進化させ続けなければなりません。DataRobot は AI モデル実運用フェーズで直面するこれらの課題を解決するために考え抜かれた機能を備えたプラットフォームであり、DataRobot MLOps によってものづくり現場へ AI を活用するための課題の多くを解決することができます。
![図3. CRISP-DMによるデータ分析プロセス[5]](https://www.datarobot.com/jp/wp-content/uploads/sites/2/2022/09/blog_monodukuri3.png)
以前弊社のブログでも紹介した、データ分析の進め方に関するフレームワークである CRISP-DM によれば、「Business Understanding」すなわち課題の理解から、データの理解、準備からデプロイまで、データを中心に様々なタスクを行っていく必要があります。
機械学習プロセス(下図4)を俯瞰すると、データ収集/準備、モデルの生成ステップでは分析者が比較的自由にツールを選ぶことができます。しかし、モデルの実運用化ステップに入ると、IT エンジニアなどのプロジェクトメンバーと協力しながら、運用の連携先システムに関する様々な制約の元で稼働条件を決めます。さらに、ものづくり現場でAIモデルを使用するのであれば、実際のユーザーに対しての説明も必要になります。
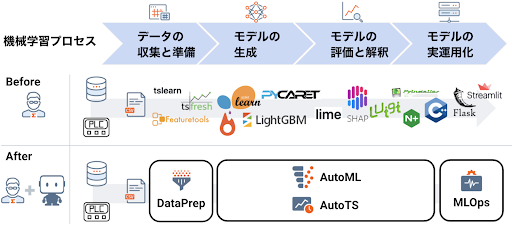
DataRobot はデータ準備から運用までをエンドツーエンドで実現するプラットフォームであり、AI 活用に関係する全てのステークホルダー共通の基盤となり、共通言語でのコミュニケーションを可能にします。その結果、AI モデル作成者が現場システムと連携するためにモデルを実装し直すようなマニュアル作業の多くを省くことができます。
また、現場で運用しているモデルが一つの設備と見做せる場合には、製造ラインに組み込んだ時がAIモデル稼働のスタートになりますので、安定かつ期待通りの挙動を確実にするためには前章で考察したような生産設備と同等レベルの保全の仕組みが必要になってきますが、DataRobot MLOps はこの目的に最適な運用基盤であり、これを活用して、モデルの保全業務の負荷を大幅に低減することができます。
DataRobot MLOps の特徴
DataRobot MLOps は本番稼働しているモデルすべてを一元的に運用、監視、管理できるプラットフォームであり、前述した課題の多くについての解決方法を用意しています。
開発環境と実行環境の違いに対応した多様なデプロイ方法
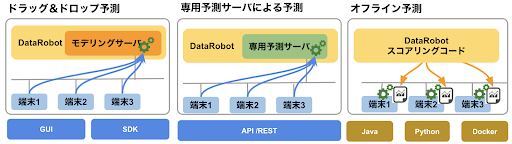
現場でモデルを活用するために、DataRobot は多様なデプロイ方法を用意しています。特にものづくりの現場においては、前述したようにインターネットに接続できないケースも多く、ライン側での運用が大事になってきます。DataRobot の Scoring Code 機能では、作成したモデルをJavaの実行モジュールとして出力することができます、なお、画像などを含めたデータを使用する場合にも対応できるよう、DataRobot のポータブル予測サーバー機能では Docker ベースの予測方式も提供しており、解析時の環境と予測時の環境を統一するようにしています。
モデル監視、トラッキングの仕組みが充実
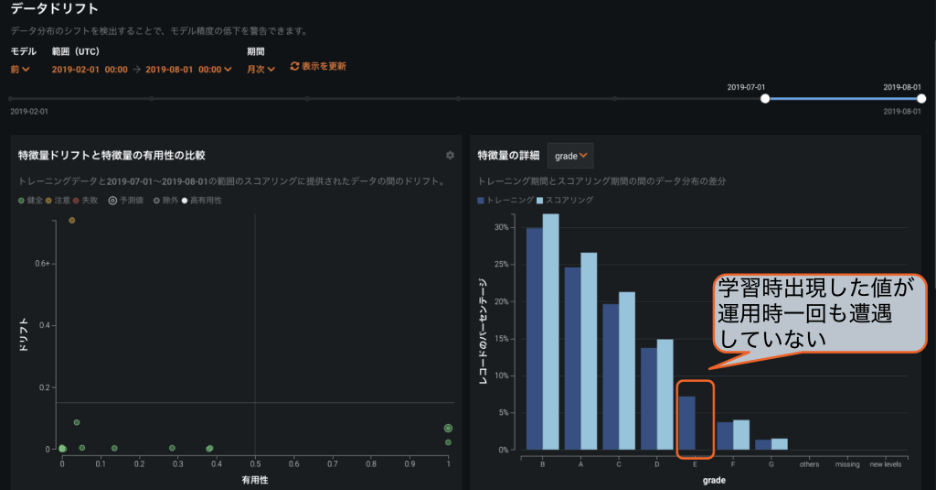
モデルが稼働しているインフラの死活監視と精度パフォーマンスのトラッキングは当然として、精度劣化の前兆と見られる特徴量の分布変化までも、DataRobot では PSI を指標にモニタリングしています
モデルの自動再学習が可能
2021年6月末、DataRobot はモデルの精度パフォーマンスに劣化が見られた時には自動的に再学習を行う機能を発表しました。これにより、常に最新のデータに基づいた高精度なモデルを維持し続けることができます。
| 想定される課題 | 解決方法 |
| ・開発と実行環境の違い | →AI モデルの書き出し機能 |
| ・監視、トラッキングの仕組みが必要 | →DataRobot MLOps の管理・監視機能 |
| ・精度を維持するためモデル再学習が必要 | →自動再学習機能 |
まとめ
本稿では、ものづくり企業が現場で A Iを活用して成果を出し続けるためのポイントを考察・解説しました。特に、AI モデルを作成した後のフェーズにも多くのチャレンジがあることを指摘し、それらを解決するための重要な考え方を、ものづくり現場で品質管理・監視を行う例と比較しながら考察しました。最後に、ものづくり企業が AI モデルにより現場で価値を創出し続けるため必要とされる仕組みが DataRobot MLOps プラットフォーム上に搭載されていることをご紹介しました。
ものづくり企業で AI 導入をご検討されている方にとって参考となれば幸いです。
参考文献
[1] DataRobot Pathfinder:製造業界でのユースケース
[2] トヨタ企業サイト トヨタ自動車75年史 研究開発支援 技術企画・開発プロセス改革
[3] 統計解析と機械学習:要因分析からの考察 Part 1
[4] Permutation Importanceを使ってモデルがどの特徴量から学習したかを定量化する
[5] Shearer C., The CRISP-DM model: the new blueprint for data mining, J Data Warehousing (2000); 5:13—22.

DataRobot シニアデータサイエンティスト。地盤工学のバックグラウドと IoT のソフトウェアベンダーで勤めた経験をもとに、建設、自動車メーカー様をメインに製造業のお客様の AI 活用をサポート。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事