
機械学習における不均衡データへの対処法
はじめに
DataRobot で小売・流通業のお客様を担当しているデータサイエンティストの井原です。
データサイエンスにおけるモデリング段階で、実際に得られるデータのサンプル数が限られている場合があります。特に、特定のデータが少なくそのパターンを見つけにくい場合、目的とことなった結果を算出しているのに、表面上は問題がないようにみえてしまうことがあります。
本稿では、機械学習のモデリングにおいて偏りのあるデータに遭遇したときに、どう対処したらよいかを状況別に分けて紹介します。なお、ここで扱うデータはテーブルデータを前提としています。
不均衡データとはなにか
機械学習の予測モデルを作る際に、予測対象となるターゲットのバランスが悪い場合があります。例えば、分類において片方のクラスが極端に少ない状況がこれに該当します。このような偏りのあるデータは不均衡データ(インバランスデータ)と呼ばれます。
例えば、予測ターゲットが「正常」あるいは「異常」である二値分類のデータセットのうち、「正常」のラベルをもつサンプルが100,000、「異常」のラベルをもつサンプルが10の場合、異常のサンプル数が極端に少ない不均衡なデータになっています。
このようにデータが不均衡になる原因として、サンプルの少ないクラスの事象は稀にしか起こらないイベントであることがよくあります。しかし、稀なイベントにも関わらず、実は全体に大きな影響を及ぼすことが多く、この稀なイベントを予測することは重要な課題です。
データの不均衡は特定の分野に限らず幅広い分野で起こりえます。不均衡データが起こりやすい課題の例として、機械の故障検知、割引キャンペーンによって購買する人の検出、社員の退職予測、薬で副作用が起こる人の予測、クレジットカードの不正利用の検知などが挙げられます。これらの課題に共通しているのは、前述の通り、予測対象が稀なイベントであるという点です。ではこのような不均衡なデータを分析する際には何に注意をしたらよいのでしょうか。
不均衡データの分析における問題点
不均衡なデータは通常のデータと比較して、サンプル数の少ない少数派クラス(マイノリティクラス)に対するモデルの感度が低くなります。そのため、不均衡データに適切な対処をせずにモデルを作ってしまうと精度、計算量、インサイトなどの面で問題が生じます。
まずは精度面での問題をみていきましょう。例えば、割引キャンペーンによって購入する人を予測したい場合、モデリングに使用する過去のデータは購入した人が非常に少ないデータになっていることがあります。ここで、割引キャンペーン対象者1万人のうち、実際に購入まで至ったのは100人だったとしましょう。(図1)このような不均衡データを元にこれからの対象者がキャンペーンによって購入するかどうかをターゲットとしてモデリングしたときに、全員を「購入なし」と分類したとしても正解率 (Accuracy) は99%になります。
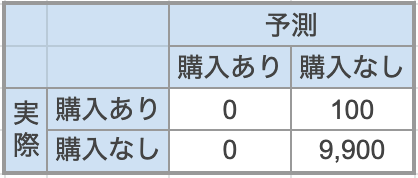
数値だけ見ると良い予測精度ですが、モデリングの当初のターゲットである「割引キャンペーンで購入する人」100人は全く当てられていません。このように、何も意識せずに不均衡なデータでモデリングをすると、誤った結果を導いてしまうことがあります。
不均衡データはモデルの精度面だけではなく、計算コストの問題も抱えています。前述の割引キャンペーンの例では、モデルを学習するときに、ほとんどの時間を「購入なし」に費やします。長い計算時間をかけても、結果的に「購入あり」の判別にはそれほど貢献できないモデルしか作ることができません。
少数派のクラスが多数派のクラスより重要視されるような場合、モデル構築時にこの不均衡をどう考慮すればよいのでしょうか。
不均衡データの一般的な対処法
不均衡データの代表的な対処法としてデータの工夫や適切な最適化指標の選択があります。ここでは不均衡データの対処法について、データサイズと不均衡具合の観点で状況を3つに分け、それぞれの対処法を紹介します。
- データサイズがそれほど大きくない場合 (~数GB)
データサイズが大きくなく計算量がそれほど問題にならない場合は、目的に沿った精度を得ることに注力します。不均衡データの対策として、多数派クラス(マジョリティクラス)のサンプルを捨てることによる偏りの低減(Negative Down Sampling)がよく使われますが、多数派のデータを捨てても精度が上がることはあまりなく最終的な問題解決にはなりません。
計算量が問題にならない規模の不均衡データで確認したい点は最適化指標です。分類の最適化指標は、重要視する結果がターゲットそのもの(例:対象者が購入するかどうか)あるいはターゲットの確率(例:対象者が購入する確率)どちらであるか、特定のクラスを重要視するかどのクラスも同じように扱うのかなど、状況に応じて決める必要があります。目的に沿った最適化指標を選んでいないと、誤った結果になることがあります。例えば、二値分類でよく使われるROC曲線下の面積(ROC-AUC)は、片方のクラスを重視することはなく両方のクラスを同等に扱います。不均衡データの場合にこの最適化指標を使うと、多数派のクラスを重視しすぎてモデルの質によらずに高い値を取りやすくなることが多々あります。[1]
最適化指標の選択方法の詳細についてはここでは触れませんが、不均衡なデータセットでも結果が変わらないLogLossや、少数派クラスを重きを置いたPR曲線の下の領域(PR曲線のAUC、AUC-PR)を最適化指標として使用するとよいでしょう。
- 少数派クラスのサンプル数が少なくデータサイズが大きい場合 (約1~10%, 数十GB~)
データサイズが大きいために計算時間がかかっているが少数派クラスのサンプル数はある程度確保できている場合、問題は全体のサンプル数が多すぎることです。そのため、まずは計算量を減らすことで効率よく分析を進めていきます。
このような場合に一番最初に試すことは、少数派も多数派もまとめてランダムにサンプリングを行い、全体のデータサイズを小さくすることです。少数派と多数派の比率を維持したい場合は層化抽出を行いましょう。この理由は、データサイズが大きくなればなるほど精度が向上していくとは限らず、むしろ通常はある程度のデータサイズから精度改善が緩やかになるためです。
ここで、どれくらいのサンプリングを行えばよいのかという疑問が生じます。データセットのサイズによる予測ののび具合は、学習データのサンプル数と予測性能の関係を表した学習曲線で確認します。まずは計算時間が許容できる範囲内で小さめのデータセットから試していくと良いでしょう。
ある程度の精度を保ちながらデータのサイズを小さくすることで、計算時間を削減することができ、特徴量エンジニアリングなど他のところに時間をかけて精度改善の検討ができるようになります。
- 少数派クラスのサンプル数が極端に少ないのにデータサイズが大きい場合(約1%以下, 数十GB)
データの不均衡具合とデータサイズの大きさが問題である場合、両方の問題を解決する必要があります。ランダムサンプリングで全体のサンプル数を減らすと、今回重要視している少数派クラスのサンプル数も減ってしまいます。そこで、多数派のクラスだけをサンプリングする Negative Down Sampling によって計算量を削減します。
ここで気になるのは、Negative Down Samplingによる精度低下です。これに対しては、サンプリングのシードを変えて繰り返しアンサンブルするブートストラップ法を用いることによって精度低下を補う方法がよく使われます。
少し違った視点として、問題設計を変える方法もあります。故障検知など、異常状態のデータがなかなか取れない状況では、教師なしの異常検知として課題の再設定をすることもあります。
今回は、データセットサイズと不均衡具合に応じた状況別の一般的な対処法を紹介しています。データによっては該当しない対処法もありますので、あくまで一般的な方法だと理解しておいてください。
DataRobotにおける不均衡データの対処法
前章では、状況別で以下のような不均衡データの対処法がありました。
- 不均衡データにロバストな最適化指標の設定
- 学習曲線の確認による適切なデータサイズの決定
- Negative Down Samplingによる計算量の削減
- Balanced Bootstrapによる精度低下の補填
- 異常検知問題としての取り扱い
これらの方法をDataRobotで行うにはどうすればよいのでしょうか。もちろんDataRobotが自動で設定する点もありますが、ユーザ側で指定する箇所もあります。DataRobotがカバーしている機能の範囲を知り、正しく分析を進めていく方法をみていきましょう。
1. 不均衡データにロバストな最適化指標の設定
不均衡なデータでモデリングする場合、DataRobotは自動的にターゲット変数の値の分布から最適なモデル最適化指標を選択します。
これまでは分類問題を前提で話を進めてきましたが、不均衡データの問題は分類、回帰どちらでも起こりえる問題です。図2の分類の不均衡データセットの例では、DataRobotは前述のLogLossを最適化指標として選択しています。
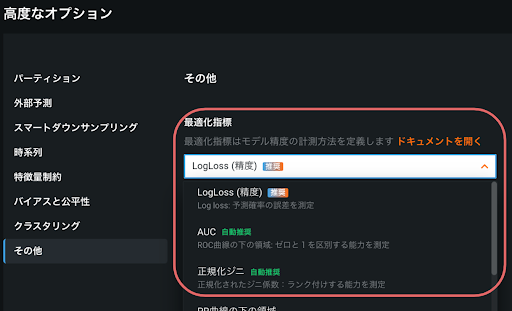
同様に、回帰でも、例えばターゲットの値の大半をゼロが占めるような不均衡データ(ゼロ過剰)を扱うことがあります。このようなゼロ過剰の場合には、最適化指標としてTweedie Devianceがよく使われます。DataRobotは回帰の不均衡データの場合でも自動的に適切な最適化指標を選択します。なぜTweedie Devianceが使われるのかを知りたい方はドキュメントページDataRobotの指標をご確認ください。
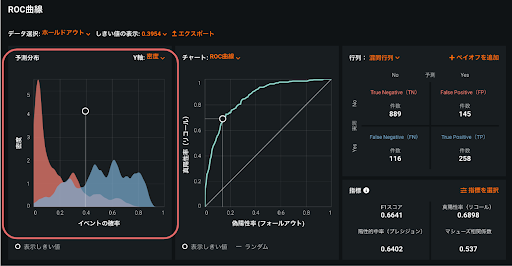
ここで、結果のROC曲線も確認しておきましょう。ROC曲線の情報を活用することで、不均衡なデータがモデルのパフォーマンスに与える影響を最小限に抑えることができます。前述の割引キャンペーンの例で考えてみましょう。キャンペーンを実施する際に、できる限りたくさんの人にキャンペーンで購入してほしいのですが、全員にキャンペーンチラシを送るとコストがかさんでしまいます。コストを抑えて購入率の高い人にだけ送付するのか、機会損失を防ぐために多めの人にキャンペーンを案内しておくのかについては、予算やキャンペーンの内容によって変わってきます。予測分布グラフの予測しきい値(図3)を調節することにより、割引キャンペーンで購入すると予測されたが実際は購入しなかった人(偽陽性)と購入しないと予測されたが実際は購入した人(偽陰性)それぞれがどれだけ許容できるかを決定します。これによって、少数派のクラスに対する予測が改善される可能性があります。
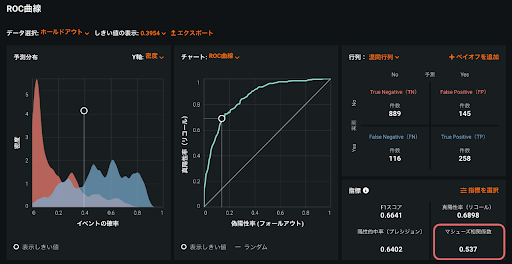
不均衡データの場合、モデル評価指標のひとつであるマシューズ相関係数を参考にするとよいでしょう。(図4)マシューズ相関係数は混同行列の予測と実測の一致度合いを表す指標で、完全に一致していたら+1、不一致なら-1を取ります。データセットの多数派クラスと少数派クラスの大きさに比例した結果を返すため、不均衡なデータセットから構築されたモデルを評価するのに適しています。
2. 学習曲線の確認による適切なデータサイズの決定
データセットのサイズを大きくすることに意味があるかどうかを判断ために、サンプルサイズごとの学習曲線を確認します。「どれくらいの規模のデータを用意すればよいのか」は不均衡データを扱うときだけでなく、一般的に機械学習モデルを作る際によく聞かれる質問です。扱うデータにより状況が異なるので決まった回答はありませんが、学習曲線でサンプルサイズを増やしたときにどれくらいスコアが上がるのかを確認することにより、必要なサンプルサイズのあたりを付けることができます。
DataRobotでは、最初から全てのデータを使わず、最初はデータの一部を使って短時間でモモデリングを行います。図5では、全体の16%のデータから始まって32%、64%とデータを増やしたときに学習曲線(LogLossのスコアがどう減っているか)を確認できます。
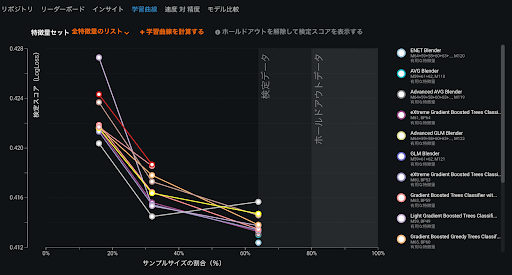
もしデータを増やしたときにスコアがあまり変わっておらずビジネス面での影響が軽微である場合は、サンプルサイズを大きくする必要はないと判断できます。
3. Negative Down Samplingによる計算量の削減
計算量を削減するために、多数派のクラスのサンプル数だけを減らすNegative Down Samplingを行い、クラスごとのサンプル数のバランスを取ります。(図6)しかし、これではサンプリングバイアスが生じ、少数派サンプルが過大評価されてしまいます。そこで、得られたデータセットの効果が元のクラスのバランスと同じになるように重みづけをします。

DataRobotではこの一連の作業をスマートダウンサンプリングとよんでいます。モデリング時にスマートダウンサンプリングのオプションを有効化して使用できます。(図7)なお、データセットのサイズが500MB以上、かつ多数派クラスが少数派クラスの2倍以上データ以下の時には、自動的にスマートダウンサンプリングが適用されます。
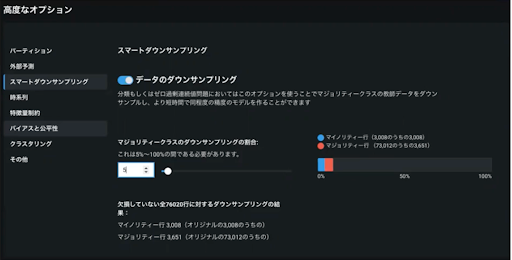
スマートダウンサンプリングの目的は、精度改善ではなくあくまで計算の高速化であることにご注意ください。
4. Balanced Bootstrapによる精度低下の補填
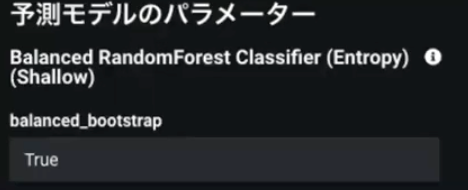
サンプリングによる精度低下の影響を低減するため、ブートストラップ法を使うことは前章で取り上げました。DataRobotでは、“Balanced” という接頭辞がつくブループリントがBalanced Bootstrapに対応したモデルです。(図8)

このモデルが選ばれるかどうかは手動モードでなければDataRobotによって自動的に決定されるため、不均衡データに対してモデリングすると含まれることがあります。また、リポジトリから ”Balanced” から始まるモデルを選択する方法、あるいは高度なチューニングからbalanced_bootstrapのオプションをTrueにする方法で、手動で設定することも可能です。(図9)
5. 異常検知問題としての取り扱い
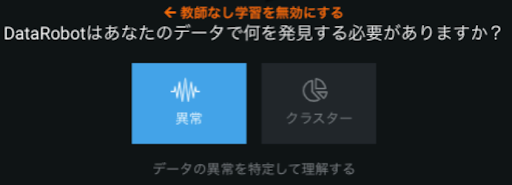
DataRobotは分類や回帰の教師あり学習だけではなく、教師なしの異常検知にも対応しています。(図10)どうしても少数派クラスのサンプル数が十分に得られない場合は課題設定を見直すことも検討してください。
関連トピック
最後に、不均衡データの対処法としてよく挙げられるデータの拡張(水増し)について触れます。計算量を減らす目的で行ったNegative Down Samplingでは多数派クラスのサンプル数を減らしましたが、逆に少数派クラスのサンプル数を水増しする方法(アップサンプリング)はどうでしょうか。水増しをした際に元データと水増しデータのサンプルのクラスラベルが同じと保証される場合は、精度向上の可能性があるでしょう。
例えば、画像データで判別モデルを作る際に、画像を左右反転させたり角度を変えてデータ拡張(Data Augmentation)を行います。この拡張方法がある程度うまくいく理由は、大半の場合は左右反転してもターゲットが同じためです。データ拡張でも例えば人を判別する際に上下反転でデータ拡張を行ってもそれほど精度が上がらないことが大半です。人が逆さまの状態になっていることはあまりないためです。このことから、データを拡張する際には、元のデータと水増ししたデータが同じ対象物と認識できる場合、判別に有用な情報を増やす事ができると言えます。
現在提案されているテーブルデータにおける少数派クラスのサンプル水増し方法は、元データと水増しデータのクラスラベルが同じであるという仮定が成立していないことがあります。データ拡張を検討する場合は、本当に問題を解決できる手段であるかどうかを考えて実施することが必要です。
最後に
今回は、偏りのあるデータにおける一般的な対処法とDataRobotにおける対処法を取り上げました。より最適化指標や評価指標について深く知りたい方はモデル最適化指標点評価指標の選び方やマシューズ相関係数とはをご覧ください。不均衡データでもこんなに細かい対処はしなくてもよいのではないかと思われたかもしれません。しかし実際、最初に挙げた例のように「全て多数派クラスとして分類」を誤ったアクションにつなげてしまっている状況を時々みかけます。不均衡データに対するそれぞれの対処法で解決できる内容を理解することで、モデリングを実ビジネスに活用していただければと思っています。
この投稿は、DataRobot Communityに投稿された質問が元になっています。DataRobotの操作方法だけでなく、予測モデリングやプロジェクト管理など、AIプロジェクトを行う上でのお困りごとがありましたらお気軽にコミュニティに投稿してください。
関連ページ
- [アーカイブ] DataRobotコミュニティウェビナー: 「DataRobotに相談してみよう」2022年7月回
参考文献
[1] T. Saito and M. Rehmsmeier, “The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets,” PLoS One. 2015; 10(3): e0118432. Published online 2015 Mar 4. doi: 10.1371/journal.pone.0118432

小売業、不動産、外食、旅行業界のマーケティング分析や需要予測などの分析業務を担当。
過去にコンサルティングファームや通信販売会社においてDXプロジェクトの推進やマーケティング施策の立案&実行をしてきた経験を活かして、お客様のAIプロジェクト支援をしている。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事