製造業:センサデータを機械学習に使う
DataRobotで製造業やユーティリティー業界のお客様を担当しているデータサイエンティストの川越雄介です。今回は、データサイエンティストの詹金、顧毅夫と連名での投稿です。
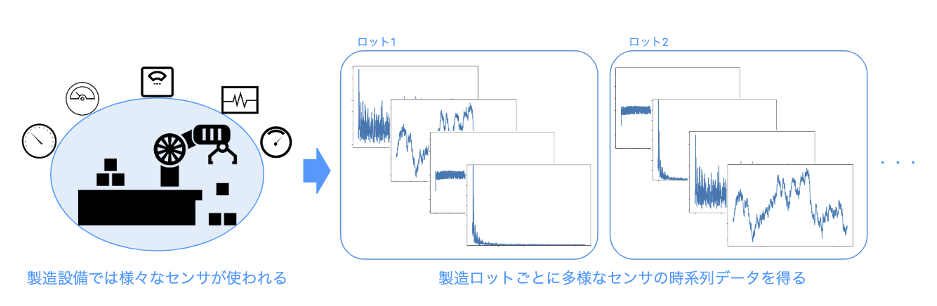
製造業やユーティリティー業界では、従来から製造設備やインフラ設備で多くのセンサが用いられてきました。近年ではビッグデータやIoTの機運の高まりから、センサの計測波形を蓄積し、機械学習で活用する動きも活発になっています。設備の異常検知・不良品の発生予測など製造プロセス・インフラ保守への活用や、R&Dにおける実験での利用に加え、昨今ではエンドユーザーのデータを製品に搭載したセンサを介して取得し、新たなサービスに繋げようとする動きも見られます。
そこで本稿では、センサの計測波形データを機械学習に使用するためのプロセスについてご説明します。
センサデータが取得されるシーン
まずは時系列のセンサデータが取得されるシーンを想定してみましょう。
ある製造設備では、製造ロットごとに良品・不良品が発生しています。工程の改善を行うために、機械学習で良品・不良品を分類するモデルを作り、不良品が発生する要因を探っていきたいと考えています。
製造設備には、状態計測や制御のために多種多様なセンサが付いています。温度センサ、湿度センサ、圧力センサ、流量センサ、加速度センサ、変位センサ、振動センサ、電力センサ、電流センサ……など、数え上げればキリがありませんが、これらの計測値はデータロガー等でロギングすることで、時間に対する計測値、すなわち時系列の波形データとして容易に取得することができます。(もちろんデータロガーを使わずとも、定期的な「目視」により一定の時間間隔で記録したデータも立派な時系列データです。)
製造プロセスのフィードバック制御に使う計測センサでしたら、その設定値(SP: Set Point)は各プロセスにおいて一意ですので、良品・不良品を分類する特徴量の一つとして使えそうです。「工程1のSP」「工程2のSP」・・・といった具合に特徴量としてデータに持たせるのはおそらく有用でしょう。
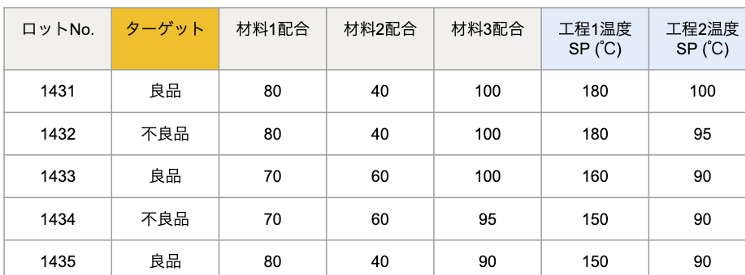
データセットのイメージ
一方で、センサの現在値(PV: Present Value)をロギングして取得した時系列データ(波形データ)も、各工程における設備の状態の履歴を表すため、重要な特徴量となり得ます。こうした時系列データをこのデータセットに追加するには、どのようにすればよいでしょうか?
時系列データを特徴量に使うには
生データをそのまま使えるか?
まずはじめに浮かぶアイデアが、取得した生データを「そのまま」使うことです。例えば1秒ごとに取得されたデータであれば、製造を開始してから「10秒後のPV」「20秒後のPV」・・・といった具合に追加することです。
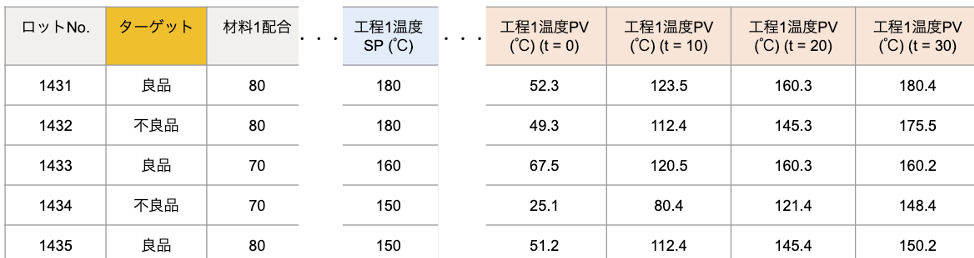
計測値をそのまま特徴量に使う場合のイメージ
しかし、この場合は注意すべき欠点があります。まず、カラム一つ一つが独立して扱われるために時間の連続性を完全に失ってしまうことです。周期性を持つ音や振動のように時間的要素が極めて重要な時系列データでは、全く無意味なカラムとなってしまうでしょう。
また、各サンプリング時刻における計測値は、ロット間で本当に比較できるものなのかを十分に考慮する必要があります。もしロットごとに取得した波形データの時間長がバラバラ(可変長データ)だったり、同じ時間長であっても計測開始点にオフセットがある場合は、それぞれのデータの同じサンプリング時刻(例えば上図のt = 20)に記録された計測値が表すものは、全くの別物かもしれません。
このように、時系列データの各サンプリング時刻における計測値そのものを特徴量として使うことは、多くの場合で有用ではありません。
時系列データの特徴抽出
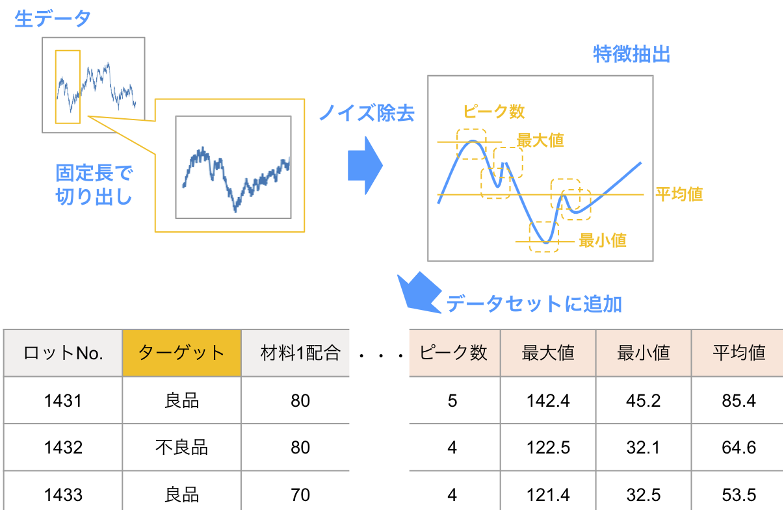
そこで行うのが、センサで取得した時系列データを加工し、その波形の様々な特徴を表す値を得る特徴抽出です。具体的なステップは下記の通りになります。
- 固定時間長で切り出す(ウィンドウイング)
- 波形で注目する箇所を決め、固定時間長(ウィンドウ)で波形を切り出す。
- 機械的に切り出すウィンドウを時間方向にスライドし、連続的に切り出すことも有用。
- 必要に応じてノイズを除去する。
- 移動平均、フィルタなど
- 加工し、特徴量として抽出する(特徴抽出)。
- 統計量(平均、分散、最大値、最小値など)
- 差分変換(前後のデータ間での差分をとり、その統計量をとる)
- 微積分(傾き、面積など)
- ピーク検出(数、高さ)
- 周波数分析(フーリエ変換など)
- 自己相関
- その他、手法は多数
- 生成した特徴量をデータセットに加える。
このように抽出した特徴は、機械学習モデルの予測ターゲットを説明する有用な特徴量となり得ます。次の章で、特徴抽出の具体例を見てみましょう。
音声データの前処理例
想定ケース
センサで取得できる時系列データの一つに音声データがあります。本章ではポンプやファンなど、製造設備が発する音で設備の異常を判断するケースを想定して、音声データの前処理例について述べたいと思います。
次のようなケースを想定して見ましょう。これまでは、経験豊富な現場の職人が音を聞いただけでその設備が異常かどうかを判断し、大事に至る前に設備を修繕してきました。しかし、その職人はまもなく引退してしまいます。適切に修繕ができないと重大な故障に繋がり、莫大なコスト損失を招きかねません。
幸い、これまで設備の音声データと、その音は正常か異常かの記録はしっかりと蓄積してきました。音声の波形データは、次のように時間ごとの振幅で表されます。
波形データを眺めてみると、何となく正常と異常とで波形が違いそうだなと感じるかもしれませんが、明瞭ではありません。では、このデータからは、どのような特徴を抽出できるのでしょうか?
メル周波数ケプストラム(MFCC)
一般的に、音声や振動のようなデータはフーリエ変換によって時間領域から周波数領域に変換してその特徴を調べることが最初のステップですが、今回はさらに「メル周波数ケプストラム(MFCC)」によって特徴抽出を行いました。(DataRobotコミュニティでサンプルコードを公開しています。)
MFCCは、Stanley Smith Stevensらが1937年に提案したメル尺度を用いています。人の聴覚上重要な周波数成分が引き伸ばされてケプストラム全体における割合が増え、人が聞いた音の特徴をよく表すと考えられています。また、N次のメルフィルタバンクを通すことにより、人の聴覚上重要な特徴を保ちながらケプストラムの次元をNまで減らすことができ、機械学習における計算負荷を減らせるメリットもあります。
本章の想定ケースでは、およそ4500ロットの音声データより20次のMFCCを得ました。次の図は、一段目のグラフが各ロットに対して付与された正常(Normal : 0)または異常(Anomaly : 1)のラベルをロットごとに並べたもの、そして二段目・三段目のグラフが20次元のMFCCの中から3次および12次のケプストラムをロットごとに並べたものです。正常と異常とで、ケプストラムの傾向が異なることが目視でも分かります。これは期待できそうです。
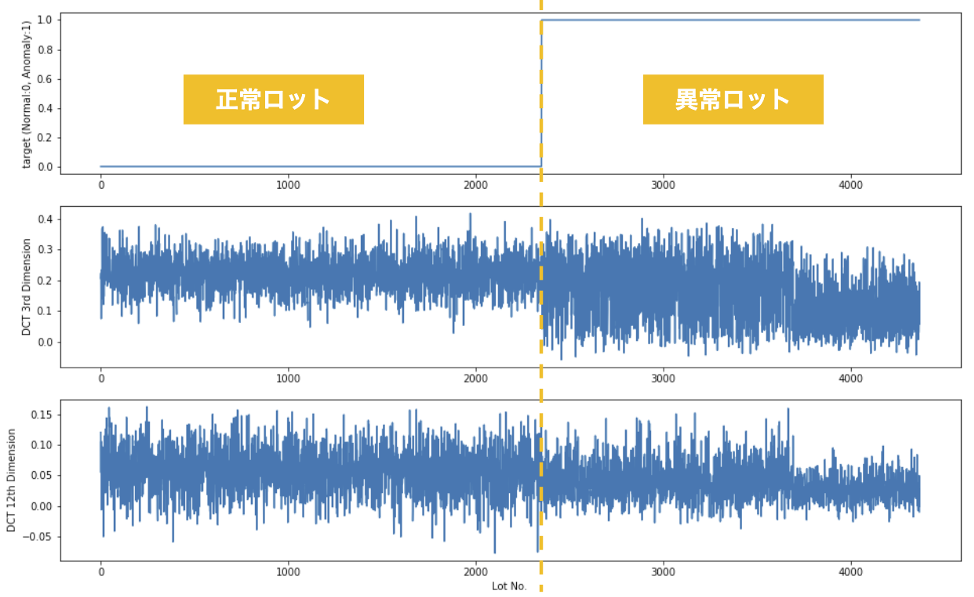
MFCCにより、生の波形データから20の特徴量を抽出することができました。いよいよDataRobotで機械学習モデルを作成しましょう!
抽出した特徴量を使ってDataRobotでモデリング
MFCCにより抽出した20個の特徴量を使って、正常か異常かを分類する予測モデルをDataRobotで作成しました(モデルA)。比較のために、生の波形データをカラム方向に連結し、およそ1800個の特徴量として作成したモデルも示します(モデルB)。
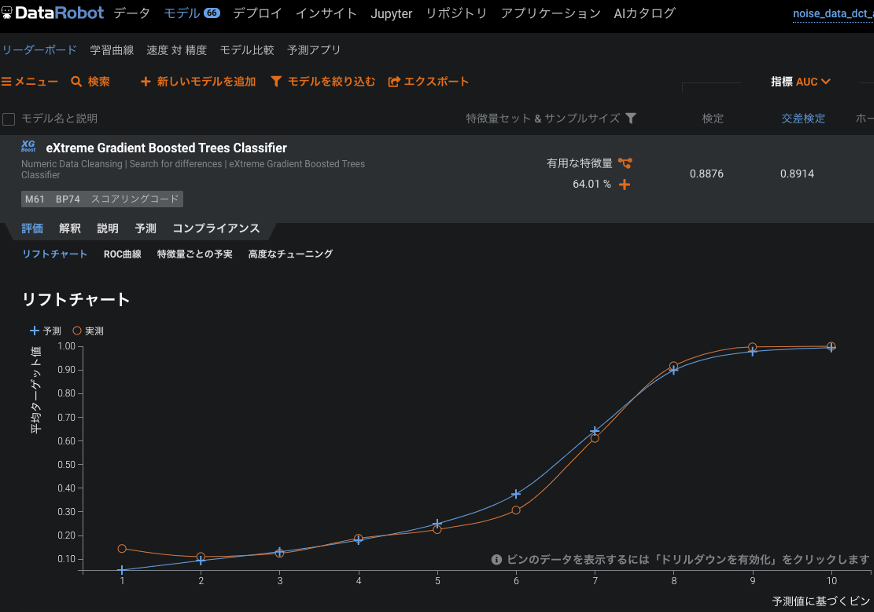
モデルA:MFCCで抽出した20個の特徴量で作成したモデル
モデルB:生の波形データをカラム方向に連結して作成したモデル
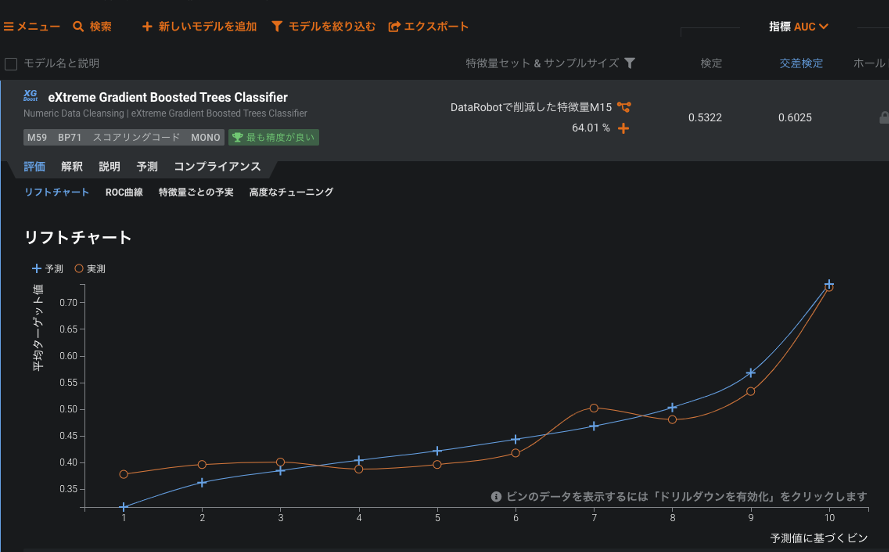
評価指標のAUCは、モデルAは0.8914、モデルBは0.6025(いずれも交差検定)と、大きな違いとなりました。リフトチャートでもモデルAは予実の乖離がわずかです。(評価指標についてはこちらのブログ、リフトチャートについてはこちらのブログで詳しく説明しています。)生の波形データをそのまま使うモデルよりも、MFCCでその波形の特徴を抽出したモデルの方が圧倒的に優れた性能であることが分かります。
波形データから特徴を抽出することの重要さとその効果について実感できたことと思います。今回は短い周期性が極めて重要な音声の波形データ処理についてご説明しましたが、音声に似た振動データでも同様の手法が使えます。一方で、温度や流量など変化が遅い波形データではまた別の方法で処理し特徴抽出することが必要でしょう。次の章では、また別の波形データを例に、実装方法を示したいと思います。
その他の波形データの前処理例
前章では音声データの前処理について述べましたが、波形データはもちろん音声だけではありません。多種多様な波形データを処理するために、オープンソース言語のPythonでは有用なライブラリが様々用意されています。代表的なものを挙げると、例えば以下のようなものがあります。
- numpy: 統計量(平均値、標準偏差、中央値、四分位など)
- scipy.integrate: 積分(定積分(scipy.integrate.quad)など)
- scipy.signal: 信号処理(フーリエ変換、ピーク抽出など)
- librosa: 音声処理に特化したモジュール
- tsfresh: 時系列波形から様々な特徴量を抽出するモジュール
この章ではおすすめのtsfreshを使って下記のサンプル波形データ(S1, S2, S3)から時間領域の様々な特徴量を抽出する方法を示したいと思います。
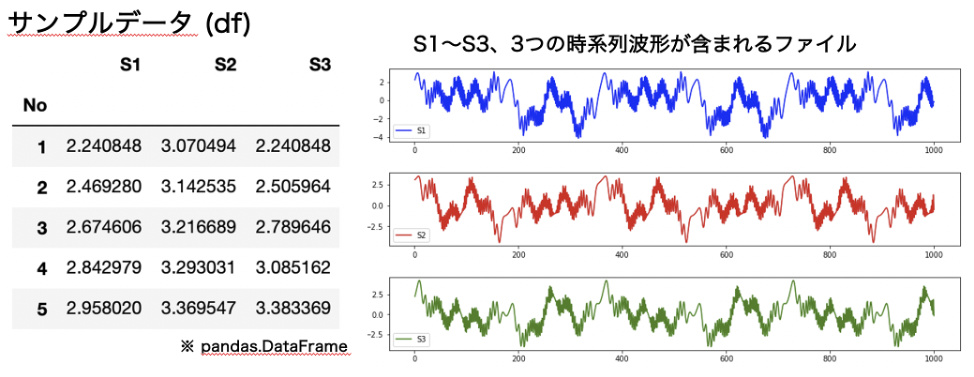
このサンプルデータはS1 ~ S3の系列ごとの1000行のテーブルデータですが、tsfreshでは一旦、整然データに整形する必要があります。(pandas.DataFrame.meltが便利です。)
# データを整然データに整形df = df.melt(var_name="sample", value_name="A")df.head()

整然データに整形したら、tsfreshで特徴量を抽出します。
# tsfreshのextract_featuresをインポート
from tsfresh import extract_features# 特徴量の抽出
df_extracted_features = extract_features(df, column_id="sample")

# 抽出された特徴量のデータフレームを確認
df_extracted_features.head()
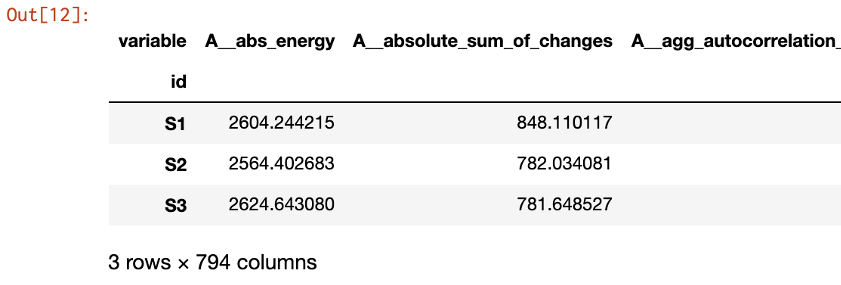
# 抽出された特徴量(カラム名)を確認
print(df_extracted_features.head())

全部で794個もの特徴量を自動で抽出できました。抽出する特徴量の一覧はこちらで確認できます。これらの特徴量をデータセットに加え、DataRobotでモデリングすることで、予測モデルの精度を向上できる可能性が高まります。
取得したセンサデータを有効に利用し、DataRobotでの機械学習モデルの性能を一層と高めてください。

DataRobot シニアデータサイエンティスト。2019年から DataRobot にて活動。10年以上、ガス会社で機械設備の技術開発に携わった経験を活かし、電気や機械が分かるデータサイエンティストとして、主に製造業・ユーティリティー企業様の AI 活用推進を支援している。現在も名古屋市に居住しており、中部地方や西日本のお客様を中心にサポート。

DataRobot データサイエンティスト、Kaggle GrandMaster。主にはお客様のモデル精度改善の業務担当している。余暇ではいろいろな機械学習コンペティション(Kaggle、Signate、ProbSpace、Tianchi…)に取り組んでおります。Kaggle Meetup Tokyo、Kaggle Days Tokyo 登壇したことあり。

DataRobot シニアデータサイエンティスト。地盤工学のバックグラウドと IoT のソフトウェアベンダーで勤めた経験をもとに、建設、自動車メーカー様をメインに製造業のお客様の AI 活用をサポート。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事