
需要予測におけるクラスタリング技術の活用
(このブログポストは Product Clustering Techniques in Demand Forecasting の和訳です)
需要予測は、多くの DataRobot ユーザーが取り組んでいる時系列のユースケースです。過去の販売データ、商品/製品の特徴、イベントカレンダー、経済指標に関するデータを使って、未来の需要予測を行います。この予測をもとに在庫管理やサプライチェーンの計画をして、業務全体の効率化を図ることができます。
さまざまな企業での需要予測における共通課題は、商品ライン、すなわちSKU (Stock Keeping Unit) の多さにどう対処するかです。ここでの問題は、SKU の数が多い場合、全ての SKU について正確な予測を作成するのは簡単ではないということです。特に、消費財を扱う典型的な小売業での需要予測モデルは、何千、何万もの SKU を予測しなければならないこともあります。
SKU 数が多い場合の需要予測モデルのパフォーマンスを向上させるためのいくつかのテクニック(手法)があります。これらのテクニックは商品のクラスタリングを中心としたもので、互いに「近い」または類似している商品カテゴリや SKU をクラスタリングし、一緒にモデル化します。
このブログでは、これらの手法に注目して解説します。需要予測のユースケースでは、これらのテクニックを一つだけでなく、複数適用することもできます。
1. 商品グループごとのクラスタリング
SKU のクラスタリングで最も直感的な方法は、商品グループによってクラスタリング(グループ化)することです。商品の種類によって需要のパターンが異なることは当然です。例えば、高価な宝飾品の需要は比較的低めで金の価格に大きく左右されますが、一般的にネックレスやイヤリングなどのファッション性の高いアクセサリーは需要パターンに一貫性があり取引量も多くなります。テーマ性のある宝飾品の販売パターンには強い季節性があり、バレンタインデーや母の日などの特定イベントにピークを迎えます。このように、ドメイン知識から需要の性質が似ていると考えられる商品グループを一緒にモデル化することでモデルに影響を及ぼす要因をよりよく捉え、結果的に予測精度を高めることができます。また、これらのデータセットを作るために機械学習などの方法を取る必要はなく、商品カテゴリごとにグルーピングすることで簡単に用意できます。
2. 売上プロファイルごとのクラスタリング
商品グループごとにモデルを構築する手法は、シンプルでわかりやすい出発点です。しかし、同じ商品グループでも、販売パターンや性質が大きく異なる商品が存在することもあります。そのような場合には、過去の売上をプロットしてパターンを可視化しながら陳腐化した商品や売上数にゼロがたくさんある商品を特定し、より良いサブクラスタリングを作成することができます。また、可視化によって潜在的なデータの問題を発見したり、ビジネス部門が気づいていないような興味深い販売パターンから洞察を得たりすることができます。
過去の販売パターンを可視化する場合、数千の SKU を可視化するには多少のコーディングスキルが必要かもしれませんが、Python や R で実現するのはそれほど難しい作業ではありません。また、Tableau(英語)や PowerBI などの BI ツールを使えば、これらのタスクを簡単に実行できます。
3. DataRobot でのパフォーマンスクラスタモデルの活用

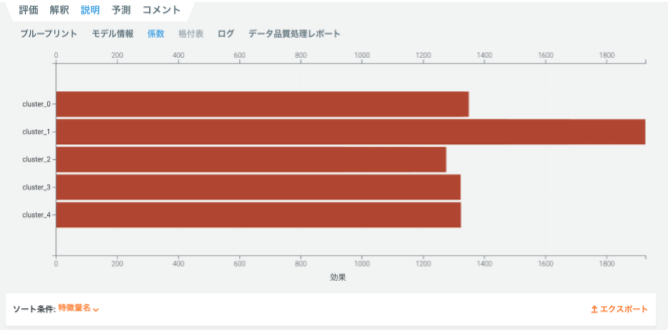
上図のようなパフォーマンスクラスタモデルでは、ベースとなるモデルを用いたときの各系列の推定精度に基づいて系列データをクラスタリングします。ここではベースモデルとして eXtreme Gradient Boosting モデル(XGB)を使用しています。XGB の推定を数回繰り返した後、モデル性能が類似している系列データを個々のクラスタに割り当てます。上記モデルには5つのクラスタがあります。
モデルが作成したクラスタの数と各クラスタに含まれる系列の数に関する情報は、係数のセクションで確認できます。また、系列 ID とクラスタ番号の対応付けは、同じウィンドウのエクスポートオプションからダウンロードできます。
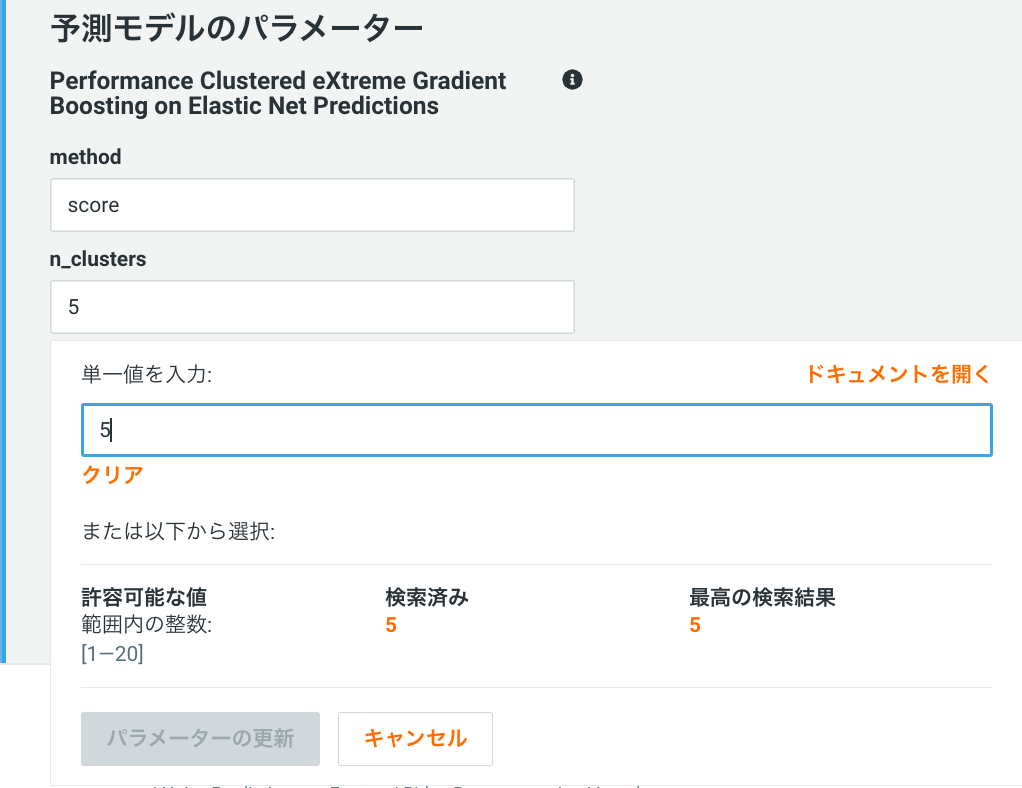
パフォーマンスクラスタモデルにおけるクラスタ数はモデルのハイパーパラメータの一つで、DataRobot オプション内の高度なチューニングの画面からモデル作成者が最大20クラスタまで設定可能です。
4. DataRobot における系列のインサイト機能の活用
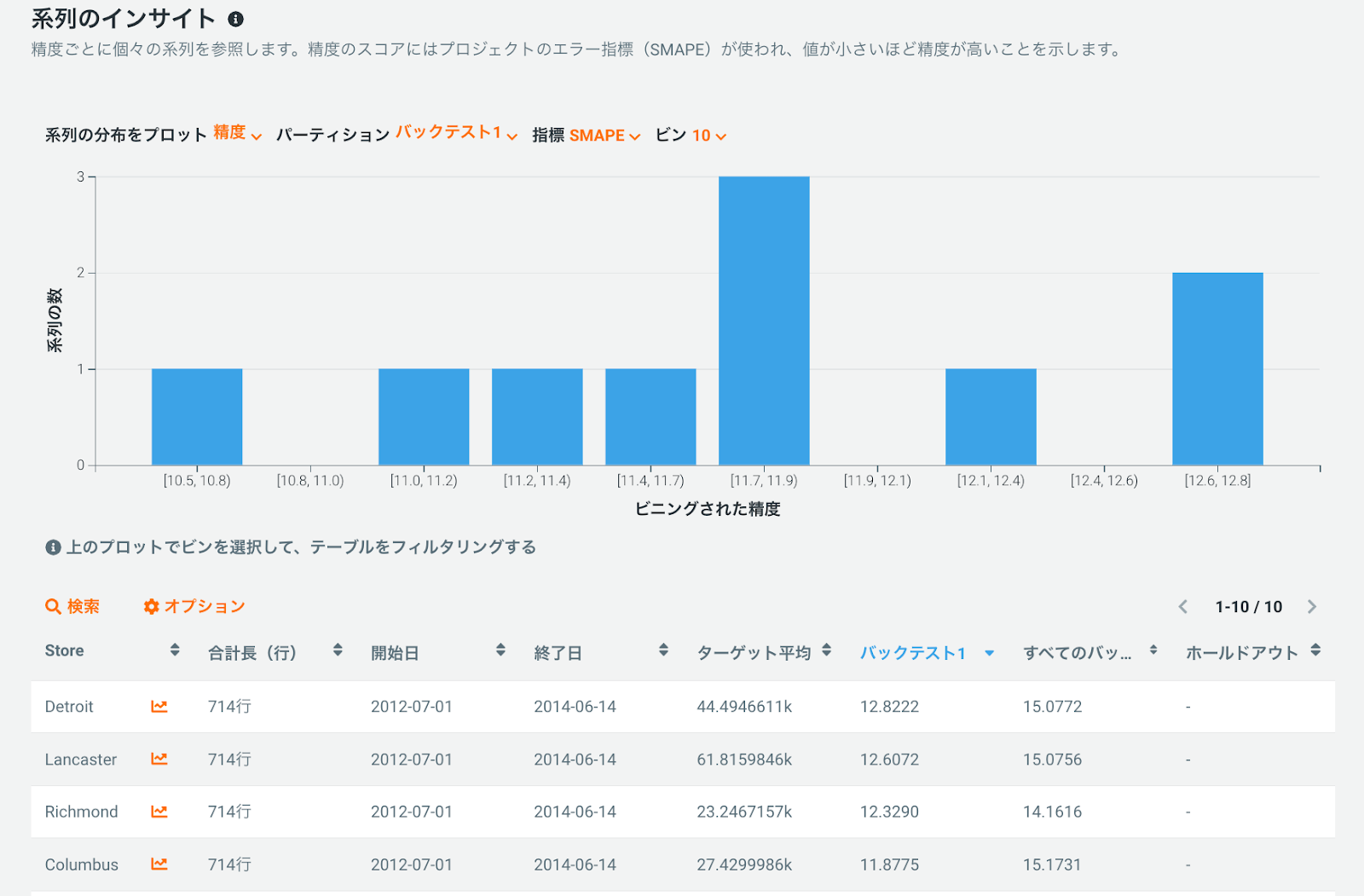
また、系列のインサイトタブを使用して、個々の系列を調査することもできます。系列のインサイトは、異なるバックテストで選択した評価指標(例:SMAPE)に基づき、各系列がどれくらいの精度なのかを教えてくれます。
ここから、モデルのパフォーマンスおよび/または商品グループや販売プロファイルが類似している系列を発見できます。商品クラスタリングはモデル駆動型とビジネス駆動型を組み合わせて行えるので、この商品クラスタリングに基づいて、個々の DataRobot プロジェクトを構築します。
最後に、DataRobot にはデータの蓄積がないコールドスタートとデータがある程度確保できるウォームスタートの両方を同じモデルで扱うことができるブループリントがあります。一般的に、これらのブループリントは2段階のアプローチを使用します。
- データ全体に対して、平均化された派生特徴量に対してうまく作用する主効果モデルを構築します。
- ステップ1で得た他の商品に共通してみられる特徴量(利用可能な場合)を過去のデータが全くない商品に対して使用して予測を行い、各系列に対するインパクトの大きさを得ます。部分的にデータがある商品に対しては、データ全体に共通する特徴量だけでなく、系列パターンも使用して予測を行います。

以上をまとめると、需要予測のユースケースにおいて、商品クラスタリングのテクニックを使用してモデルの精度パフォーマンスを向上させることができます。また、モデル主導型とビジネス主導型の商品クラスタリングを組み合わせて使用することで、需要予測モデルを最適化できます。DataRobot の Automated Time Series (AutoTS) の詳細については、Automated Time Series の製品ページや、AutoTS HowTo (DataRobot University) の自習教材、 時系列予測に関連するオンデマンドウェブセミナーをご覧ください。

シンガポールを拠点とした DataRobot のデータサイエンティスト。公共部門、ヘルスケア、通信が専門分野。シンガポール国立大学で計算生物学の学士号(第1級優等学位)、統計学の修士号を取得している。

シンガポールを拠点に活動する DataRobot のデータサイエンティスト。フィンテック、保険、製造、小売業界におけるデータサイエンスの専門知識を持っている。DataRobot 入社以前は、金融市場でポートフォリオパフォーマンスとリスク管理を専門としていました。公認証券アナリストであり、シンガポールの南洋理工大学で数理科学の学士号を取得している。
-
DataRobot, Papermill, MLflowを活用した機械学習効率化とログ管理 | AIのプロが解説
2024/03/01· 推定読書時間 3 分 -
建設業界のデジタル変革 〜AIと人間の協働の可能性とは?〜
2024/02/09· 推定読書時間 5 分 -
DataRobot Summer Launchから生成AIによるAI構築の最新動向を紹介
2023/10/11· 推定読書時間 2 分
最近のブログ記事