

Measuring Prediction Accuracy: Uploading Actual Results
This post was originally part of the DataRobot Community. Visit now to browse discussions and ask questions about the DataRobot AI Platform, data science, and more.
You can find the latest information for deploying and monitoring models in the DataRobot public documentation. Also, click ? in-app to access the full platform documentation for your version of DataRobot.
It is common to think of Machine Learning as a 2-step process: first, we train a model using historical data; then, we deploy that model into the wild for production use. However, just because it’s been deployed doesn’t mean we are finished! Au contraire! Now we’ll need to monitor our model deployment for health and performance.
DataRobot has the ability to monitor local and remotely deployed models for data drift, target drift, and accuracy as explained in this article. While the results of drift tracking are reported immediately, calculating accuracy can only be done once model predictions have been realized. Once available, the actual outcomes can be fed back into DataRobot to report on accuracy over time. Multiple accuracy metrics are available, such as LogLoss, AUC, RMSE, etc.
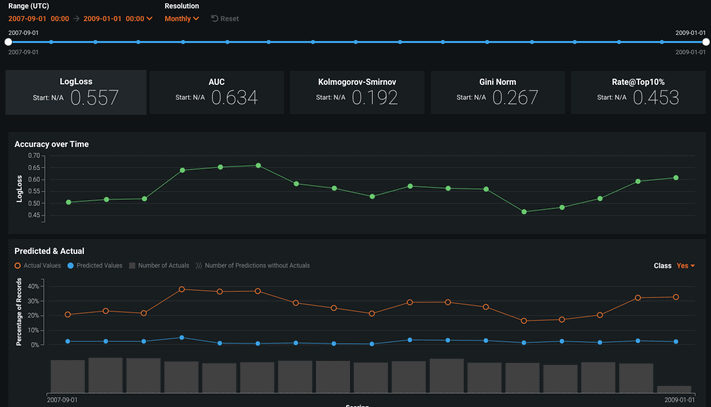
Specifying an Association ID
Reporting actuals for accuracy tracking involves specifying an Association ID and uploading the actual results to DataRobot so that actual outcomes can be linked back to the DataRobot prediction.
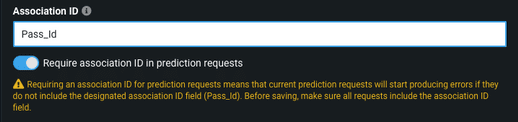
You set an Association ID for a deployed model, either during or after model deployment. DataRobot treats the ID as a string. Essentially, the Association ID is the name of the column in your training dataset which contains values that DataRobot can use later to match actual values with prediction values.
The column name of the Association ID will need to be provided, and it will be expected in the records sent to the deployment for a scoring request. If an Association ID is required for prediction requests (see the following image) and not provided, an error is displayed.
What should the values for the Association ID be?
The Association ID should represent a unique prediction instance. This may be obvious, or it could be a bit tricky. If a customer is scored once through a model for example, it could simply be a customer_id value. However, if they are scored weekly to see if they will churn in the next 7 days, then the Association ID should perhaps be a concatenation of customer_id and the week starting date when the prediction is made; for example an Association ID of customer_id_week with a value of 123456_07_12_2020.
Some important notes when configuring deployments:
- The Accuracy tab does not yet support multiclass model deployments.
- The Association ID can be expected to be used at both scoring time and reporting time as a unique identifier whose associated data is replaced if sent again. If an Associated ID has already been reported on, and it is reported again with a different actual value, the latest will be used in all calculations.
- The Association ID field cannot be changed once the field has been specified and a scoring request has been made through the deployment.
- The threshold is of particular importance for binary classification models; DataRobot responds to a scoring request with results for both positive and negative class labels, as well as a predicted label with the threshold towards the positive class applied. Accuracy will be compared against this threshold applied label.
- Consider an example using Titanic survival of 0.52 score label 0 non-survival vs. 0.48 score label 1 survival, with a threshold of 0.5. Since 0.48 does not meet 0.5, DataRobot will choose a prediction of label 0, i.e., non-survival. A downstream application may use this same value, or may choose to apply a different threshold against the 0.48 score. DataRobot Accuracy will always use the threshold set in the deployment.
- Time series can be a little trickier, as a series identifier and date (or other time interval) may be produced multiple times. A proposed Association ID value for a time series deployment would be the forecast date concatenated with the forecast distance. A multiseries model would additionally include the series identifier.
- The Association ID feature and value will be automatically returned in the scoring response.
- If an Application from DataRobot’s Application Gallery is planned to be used on top of the deployment, the Association ID will need to be disabled.
Upload Actual Results via the GUI
To upload actual results, navigate to that deployment in DataRobot and select the Settings tab. Under the Actuals section you can import a results file from the AI Catalog (if was was uploaded previously), or choose a local file.

Tip: As these tend to be one-time, single-use files, we recommend that you remove them from the AI Catalog after they are successfully ingested to keep the catalog free from clutter.
The AI Catalog is a good option for ingesting a large dataset of actuals from a source like a database or data warehouse, where DataRobot can access this data through a SQL query. Through other workflows, a local file on a desktop or server may be available.
Consider this example simple set of five actuals that you upload:
Pass_Id,actual_result
892,1
893,0
894,0
895,1
896,1
After selecting an actual source, then you specify the associated fields:

When the results are done and saved out, DataRobot processes and presents them within the deployment for accuracy tracking. (This article provides a video of this process.)
Uploading Actual Results via the API
You can also use the API for reporting actuals back, which is the recommended method when automating reporting. The DataRobot Python Client wraps the API and makes it easy to submit actual values from Python after importing the module.
The field in the inference data that provides the Association ID must be named associate_id. Similarly, the actual result must be named actual_value. A simple Python script to call from the command line and leverage the API is provided below.
import sys
import datarobot as dr
import pandas as pd
import numpy as np
APP_HOST = 'https://app.datarobot.com' # cloud SaaS host
API_TOKEN = '123_YOUR_TOKEN_456'
APP_HOST_ENDPOINT = APP_HOST + '/api/v2'
print("\n\nExpected Usage: python upload_actuals.py DEPLOYMENT_ID ACTUALS_FILE.CSV")
print("API token and host expected to be found inside upload_actuals.py")
print("\n\nACTUALS_FILE.CSV expected to contain 2 columns named:")
print("association_id - string value of the association id sent in with the scoring request.")
print("actual_value - the actual value for the predicted target at this association_id instance.")
print("")
deployment_id = sys.argv[1]
actuals = pd.read_csv(sys.argv[2])
if 'association_id' in actuals.columns and 'actual_value' in actuals.columns:
if actuals['association_id'].dtype != np.dtype(object):
actuals['association_id'] = actuals['association_id'].apply(str)
dr.Client(endpoint=APP_HOST_ENDPOINT, token=API_TOKEN, #ssl_verify=False
)
deployment = dr.Deployment.get(deployment_id=deployment_id)
print("uploading...")
deployment.submit_actuals(actuals)
print("success")
else:
print("aborted: make sure input file contains case-sensitive columns association_id and actual_value.")This script was saved with the name upload_actuals.py and will use an input file with the following data:
association_id, actual_value
892,1
893,0
894,0
895,1
896,1
The API token is specified in the script, and the deployment is passed as a parameter along with the actuals filename.
python upload_actuals.py 5f3b1234567890 actuals.csv
Once actuals have been uploaded, DataRobot’s model monitoring capabilities will be able to provide even more insight into how the model is performing over time. Drift metrics for both input data and target output values can be evaluated alongside predictions vs actual values. You can review these values manually or programmatically to identify performance decay, trigger a new workflow to train, and replace the model with a new one. Happy model monitoring!
For more information on setting up an association ID and uploading actuals for your deployment, see the DataRobot public documentation for Enable accuracy for deployments.

-
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read -
6 Reasons Why Generative AI Initiatives Fail and How to Overcome Them
February 8, 2024· 9 min read
Latest posts
