


Optimizing Large Language Model Performance with ONNX on DataRobot MLOps
In our previous blog post we talked about how to simplify the deployment and monitoring of foundation models with DataRobot MLOps. We took a pre-trained model from HuggingFace using Tensorflow, and we wrote a simple inference script and uploaded the script and the saved model as a custom model package to DataRobot MLOps. We then easily deployed the pre-trained foundation model on DataRobot servers in just a few minutes.
In this blog post, we’ll showcase how you can effortlessly gain a significant improvement in the inference speed of the same model while decreasing its resource consumption. In our walkthrough, you’ll learn that the only thing needed is to convert your language model to the ONNX format. The native support for the ONNX Runtime in DataRobot will take care of the rest.
Why Are Large Language Models Challenging for Inference?
Previously, we talked about what language models are. The neural architecture of large language models can have billions of parameters. Having a huge number of parameters means these models will be hungry for resources and slow to predict. Because of this, they are challenging to serve for inference with high performance. In addition, we want these models to not only process one input at a time, but also process batches of inputs and consume them more efficiently. The good news is that we have a way of improving their performance and throughput by accelerating their inference process, thanks to the capabilities of the ONNX Runtime.
What Is ONNX and the ONNX Runtime?
ONNX (Open Neural Network Exchange) is an open standard format to represent machine learning (ML) models built on various frameworks such as PyTorch, Tensorflow/Keras, scikit-learn. ONNX Runtime is also an open source project that’s built on the ONNX standard. It’s an inference engine optimized to accelerate the inference process of models converted to the ONNX format across a wide range of operating systems, languages, and hardware platforms.
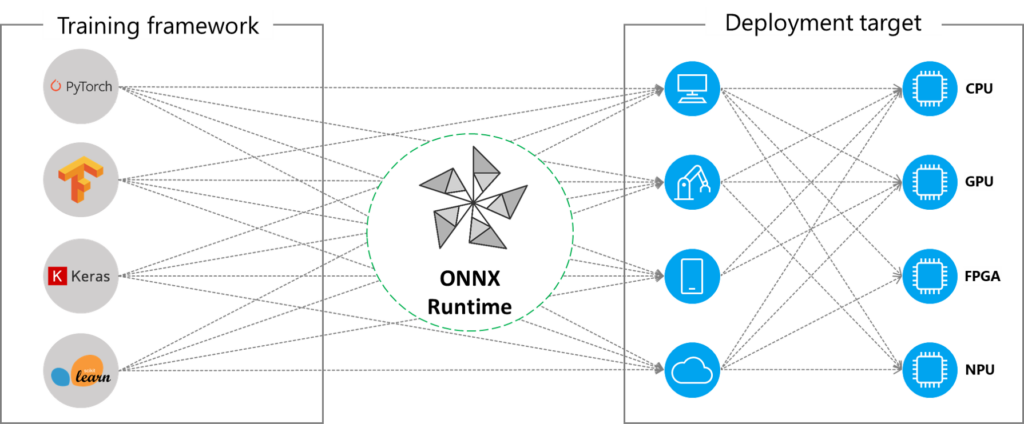
ONNX and its runtime together form the basis of standardizing and accelerating model inference in production environments. Through certain optimization techniques1, ONNX Runtime accelerates model inference on different platforms, such as mobile devices, cloud, or edge environments. It provides an abstraction by leveraging these platforms’ compute capabilities through a single API interface.
In addition, by converting models to ONNX, we gain the advantage of framework interoperability as we can export models trained in various ML frameworks to ONNX and vice versa, load previously exported ONNX models into memory, and use them in our ML framework of choice.
Accelerating Transformer-Based Model Inference with ONNX Runtime
Various benchmarks executed by independent engineering teams in the industry have demonstrated that transformer-based models can significantly benefit from ONNX Runtime optimizations to reduce latency and increase throughput on CPUs.
Some examples include Microsoft’s work around BERT model optimization using ONNX Runtime2, Twitter benchmarking results for transformer CPU inference in Google Cloud3, and sentence transformers acceleration with Hugging Face Optimum4.
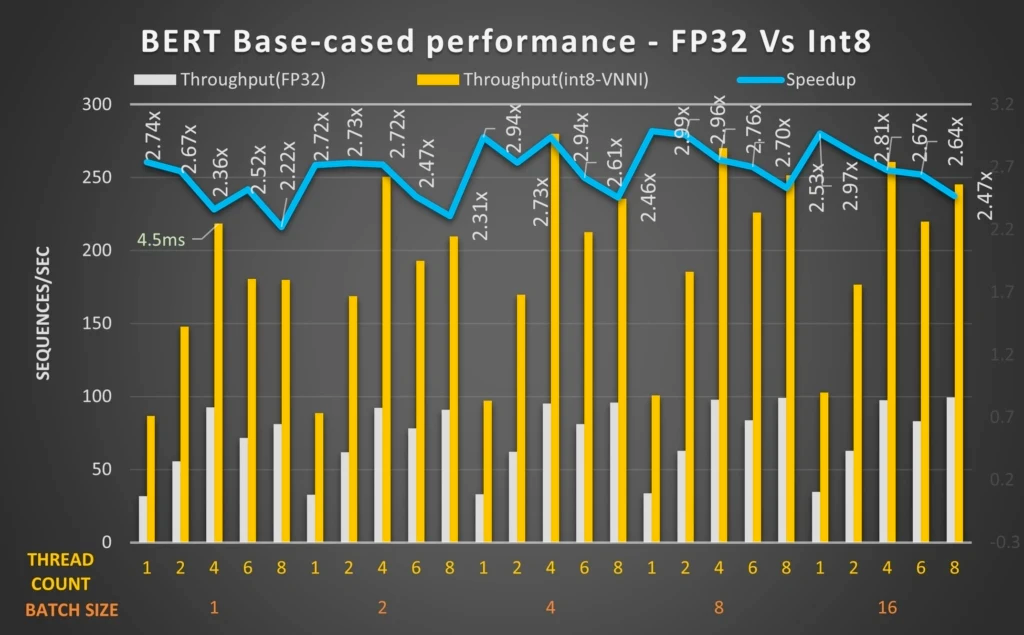
These benchmarks demonstrate that we can significantly increase throughput and performance for transformer-based NLP models, especially through quantization. For example, in Microsoft team’s benchmark above, the quantized BERT 12-layer model with Intel® DL Boost: VNNI and ONNX Runtime can achieve up to 2.9 times performance gains.
How Does DataRobot MLOps Natively Support ONNX?
For your modeling or inference workflows, you can integrate your custom code into DataRobot with these two mechanisms:
- As a custom task: While DataRobot provides hundreds of built-in tasks, there are situations where you need preprocessing or modeling methods that are not currently supported out-of-the-box. To fill this gap, you can bring a custom task that implements a missing method, plug that task into a blueprint inside DataRobot, and then train, evaluate, and deploy that blueprint in the same way as you would for any DataRobot-generated blueprint. You can review how the process works here.
- As a custom inference model: This might be a pre-trained model or user code prepared for inference, or a combination of both. An inference model can have a predefined input/output schema for classification/regression/anomaly detection or be completely unstructured. You can read more details on deploying your custom inference models here.
In both cases, in order to run your custom models on the DataRobot AI Platform with MLOps support, you first select one of our public_dropin_environments such as Python3 + PyTorch, Python3 + Keras/Tensorflow or Python3 + ONNX. These environments each define the libraries available in the environment and provide a template. Your own dependency requirements can be applied to one of these base environments to create a runtime environment for your custom tasks or custom inference models.
The bonus perk of DataRobot execution environments is that if you have a single model artifact and your model conforms to certain input/output structures, meaning you do not need a custom inference script to transform the input request or the raw predictions, you do not even need to provide a custom script in your uploaded model package. In the ONNX case, if you only want to predict with a single .onnx file, and this model file conforms to the structured specification, when you select Python3+ONNX base environment for your custom model package, DataRobot MLOps will know how to load this model into memory and predict with it. To learn more and get your hands on easy-to-reproduce examples, please visit the custom inference model templates section in our custom models repository.
Walkthrough
After reading all this information about the performance benefits and the relative simplicity of implementing models through ONNX, I’m sure you’re more than excited to get started.
To demonstrate an end-to-end example, we’ll perform the following steps:
- Grab the same foundation model in our previous blog post and save it on your local drive.
- Export the saved Tensorflow model to ONNX format.
- Package the ONNX model artifact along with a custom inference (custom.py) script.
- Upload the custom model package to DataRobot MLOps on the ONNX base environment.
- Create a deployment.
- Send prediction requests to the deployment endpoint.
For brevity, we’ll only show the additional and modified steps you’ll perform on top of the walkthrough from our previous blog, but the end-to-end implementation is available on this Google Colab notebook under the DataRobot Community repository.
Converting the Foundation Model to ONNX
For this tutorial, we’ll use the transformer library’s ONNX conversion tool to convert our question answering LLM into the ONNX format as below.
FOUNDATION_MODEL = "bert-large-uncased-whole-word-masking-finetuned-squad"
!python -m transformers.onnx --model=$FOUNDATION_MODEL --feature=question-answering $BASE_PATH
Modifying Your Custom Inference Script to Use Your ONNX Model
For inferencing with this model on DataRobot MLOps, we’ll have our custom.py script load the ONNX model into memory in an ONNX runtime session and handle the incoming prediction requests as follows:
%%writefile $BASE_PATH/custom.py
"""
Copyright 2021 DataRobot, Inc. and its affiliates.
All rights reserved.
This is proprietary source code of DataRobot, Inc. and its affiliates.
Released under the terms of DataRobot Tool and Utility Agreement.
"""
import json
import os
import io
from transformers import AutoTokenizer
import onnxruntime as ort
import numpy as np
import pandas as pd
def load_model(input_dir):
global model_load_duration
onnx_path = os.path.join(input_dir, "model.onnx")
tokenizer_path = os.path.join(input_dir)
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
sess = ort.InferenceSession(onnx_path)
return sess, tokenizer
def _get_answer_in_text(output, input_ids, idx, tokenizer):
answer_start = np.argmax(output[0], axis=1)[idx]
answer_end = (np.argmax(output[1], axis=1) + 1)[idx]
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
return answer
def score_unstructured(model, data, query, **kwargs):
global model_load_duration
sess, tokenizer = model
# Assume batch input is sent with mimetype:"text/csv"
# Treat as single prediction input if no mimetype is set
is_batch = kwargs["mimetype"] == "text/csv"
if is_batch:
input_pd = pd.read_csv(io.StringIO(data), sep="|")
input_pairs = list(zip(input_pd["context"], input_pd["question"]))
inputs = tokenizer.batch_encode_plus(
input_pairs, add_special_tokens=True, padding=True, return_tensors="np"
)
input_ids = inputs["input_ids"]
output = sess.run(["start_logits", "end_logits"], input_feed=dict(inputs))
responses = []
for i, row in input_pd.iterrows():
answer = _get_answer_in_text(output, input_ids[i], i, tokenizer)
response = {
"context": row["context"],
"question": row["question"],
"answer": answer,
}
responses.append(response)
to_return = json.dumps(
{
"predictions": responses
}
)
else:
data_dict = json.loads(data)
context, question = data_dict["context"], data_dict["question"]
inputs = tokenizer(
question,
context,
add_special_tokens=True,
padding=True,
return_tensors="np",
)
input_ids = inputs["input_ids"][0]
output = sess.run(["start_logits", "end_logits"], input_feed=dict(inputs))
answer = _get_answer_in_text(output, input_ids, 0, tokenizer)
to_return = json.dumps(
{
"context": context,
"question": question,
"answer": answer
}
)
return to_returnCreating your custom inference model deployment on DataRobot’s ONNX base environment
As the final change, we’ll create this custom model’s deployment on the ONNX base environment of DataRobot MLOps as below:
deployment = deploy_to_datarobot(BASE_PATH,
"ONNX",
"bert-onnx-questionAnswering",
"Pretrained BERT model, fine-tuned on SQUAD for question answering")When the deployment is ready, we’ll test our custom model with our test input and make sure that we’re getting our questions answered by our pre-trained LLM:
datarobot_predict(test_input, deployment.id)
Performance Comparison
Now that we have everything ready, it’s time to compare our previous Tensorflow deployment with the ONNX alternative.
For our benchmarking purposes, we constrained our custom model deployment to only have 4GB of memory from our MLOps settings so that we could compare the Tensorflow and ONNX alternatives under resource constraints.
As can be seen from the results below, our model in ONNX predicts 1.5x faster than its Tensorflow counterpart. And this result can be seen through just an additional basic ONNX export, (i.e. without any further optimization configurations, such as quantization).
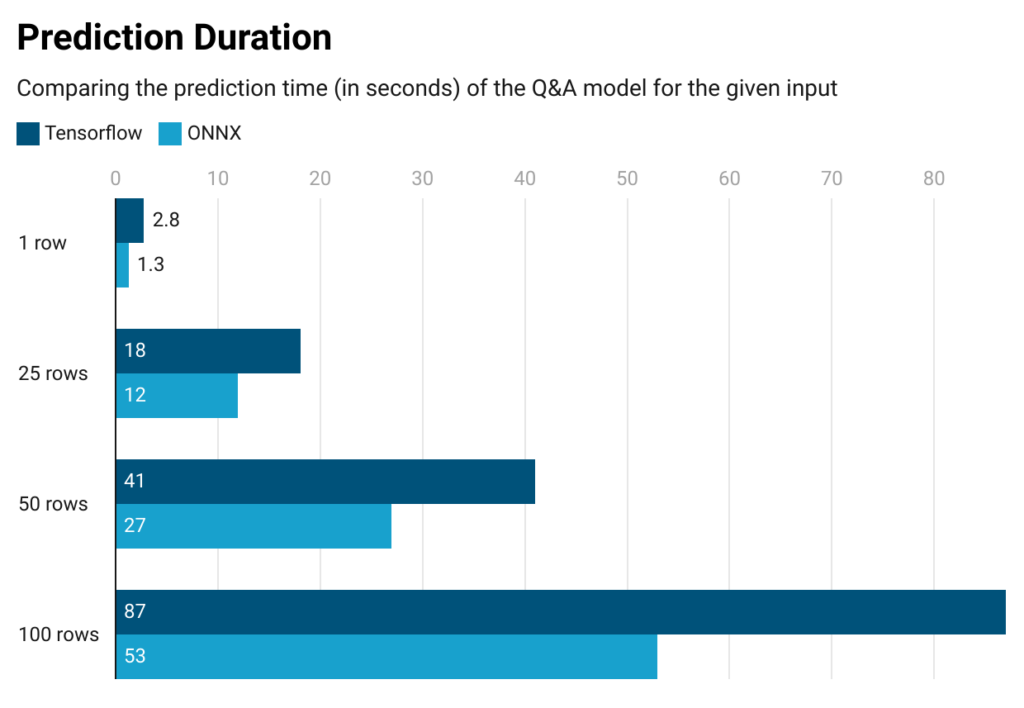
Regarding resource consumption, somewhere after ~100 rows, our Tensorflow model deployment starts returning Out of Memory (OOM) errors, meaning that this model would require more than 4GBs of memory to process and predict for ~100 rows of input. On the other hand, our ONNX model deployment can calculate predictions up to ~450 rows without throwing an OOM error. As a conclusion for our use case, the fact that the Tensorflow model handles up to 100 rows, while its ONNX equivalent handles up to 450 rows shows that the ONNX model is more resource efficient, because it uses much less memory.
Start Leveraging ONNX for Your Custom Models
By leveraging the open source ONNX standard and the ONNX Runtime, AI builders can take advantage of the framework interoperability and accelerated inference performance, especially for transformer-based large language models on their preferred execution environment. With its native ONNX support, DataRobot MLOps makes it easy for organizations to gain value from their machine learning deployments with optimized inference speed and throughput.
In this blog post, we showed how effortless it is to use a large language model for question answering in ONNX as a DataRobot custom model and how much inference performance and resource efficiency you can gain with a simple conversion step. To replicate this workflow, you can find the end-to-end notebook under the DataRobot Community repo, along with many other tutorials to empower AI builders with the capabilities of DataRobot.
1 ONNX Runtime, Model Optimizations
2 Microsoft, Optimizing BERT model for Intel CPU Cores using ONNX runtime default execution provider
3 Twitter Blog, Speeding up Transformer CPU inference in Google Cloud
4 Philipp Schmid, Accelerate Sentence Transformers with Hugging Face Optimum
5 Microsoft, Optimizing BERT model for Intel CPU Cores using ONNX runtime default execution provider

Aslı Sabancı Demiröz is a Staff Machine Learning Engineer at DataRobot. She holds a BS in Computer Engineering with a double major in Control Engineering from Istanbul Technical University. Working in the office of the CTO, she enjoys being at the heart of DataRobot’s R&D to drive innovation. Her passion lies in the deep learning space and she specifically enjoys creating powerful integrations between platform and application layers in the ML ecosystem, aiming to make the whole greater than the sum of the parts.
-
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read -
6 Reasons Why Generative AI Initiatives Fail and How to Overcome Them
February 8, 2024· 9 min read
Latest posts
